 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeachBench: A Syllabus-Grounded Framework for Evaluating Teaching Ability in Large Language Models
Jan 29, 2026Large language models (LLMs) show promise as teaching assistants, yet their teaching capability remains insufficiently evaluated. Existing benchmarks mainly focus on problem-solving or problem-level guidance, leaving knowledge-centered teaching underexplored. We propose a syllabus-grounded evaluation framework that measures LLM teaching capability via student performance improvement after multi-turn instruction. By restricting teacher agents to structured knowledge points and example problems, the framework avoids information leakage and enables reuse of existing benchmarks. We instantiate the framework on Gaokao data across multiple subjects. Experiments reveal substantial variation in teaching effectiveness across models and domains: some models perform well in mathematics, while teaching remains challenging in physics and chemistry. We also find that incorporating example problems does not necessarily improve teaching, as models often shift toward example-specific error correction. Overall, our results highlight teaching ability as a distinct and measurable dimension of LLM behavior.
GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Dec 19, 2025Visual grounding, localizing objects from natural language descriptions, represents a critical bridge between language and vision understanding. While multimodal large language models (MLLMs) achieve impressive scores on existing benchmarks, a fundamental question remains: can MLLMs truly ground language in vision with human-like sophistication, or are they merely pattern-matching on simplified datasets? Current benchmarks fail to capture real-world complexity where humans effortlessly navigate ambiguous references and recognize when grounding is impossible. To rigorously assess MLLMs' true capabilities, we introduce GroundingME, a benchmark that systematically challenges models across four critical dimensions: (1) Discriminative, distinguishing highly similar objects, (2) Spatial, understanding complex relational descriptions, (3) Limited, handling occlusions or tiny objects, and (4) Rejection, recognizing ungroundable queries. Through careful curation combining automated generation with human verification, we create 1,005 challenging examples mirroring real-world complexity. Evaluating 25 state-of-the-art MLLMs reveals a profound capability gap: the best model achieves only 45.1% accuracy, while most score 0% on rejection tasks, reflexively hallucinating objects rather than acknowledging their absence, raising critical safety concerns for deployment. We explore two strategies for improvements: (1) test-time scaling selects optimal response by thinking trajectory to improve complex grounding by up to 2.9%, and (2) data-mixture training teaches models to recognize ungroundable queries, boosting rejection accuracy from 0% to 27.9%. GroundingME thus serves as both a diagnostic tool revealing current limitations in MLLMs and a roadmap toward human-level visual grounding.
HauntAttack: When Attack Follows Reasoning as a Shadow
Jun 08, 2025



Emerging Large Reasoning Models (LRMs) consistently excel in mathematical and reasoning tasks, showcasing exceptional capabilities. However, the enhancement of reasoning abilities and the exposure of their internal reasoning processes introduce new safety vulnerabilities. One intriguing concern is: when reasoning is strongly entangled with harmfulness, what safety-reasoning trade-off do LRMs exhibit? To address this issue, we introduce HauntAttack, a novel and general-purpose black-box attack framework that systematically embeds harmful instructions into reasoning questions. Specifically, we treat reasoning questions as carriers and substitute one of their original conditions with a harmful instruction. This process creates a reasoning pathway in which the model is guided step by step toward generating unsafe outputs. Based on HauntAttack, we conduct comprehensive experiments on multiple LRMs. Our results reveal that even the most advanced LRMs exhibit significant safety vulnerabilities. Additionally, we perform a detailed analysis of different models, various types of harmful instructions, and model output patterns, providing valuable insights into the security of LRMs.
SelfBudgeter: Adaptive Token Allocation for Efficient LLM Reasoning
May 16, 2025



Recently, large reasoning models demonstrate exceptional performance on various tasks. However, reasoning models inefficiently over-process both trivial and complex queries, leading to resource waste and prolonged user latency. To address this challenge, we propose SelfBudgeter - a self-adaptive controllable reasoning strategy for efficient reasoning. Our approach adopts a dual-phase training paradigm: first, the model learns to pre-estimate the reasoning cost based on the difficulty of the query. Then, we introduce budget-guided GPRO for reinforcement learning, which effectively maintains accuracy while reducing output length. SelfBudgeter allows users to anticipate generation time and make informed decisions about continuing or interrupting the process. Furthermore, our method enables direct manipulation of reasoning length via pre-filling token budget. Experimental results demonstrate that SelfBudgeter can rationally allocate budgets according to problem complexity, achieving up to 74.47% response length compression on the MATH benchmark while maintaining nearly undiminished accuracy.
KnowLogic: A Benchmark for Commonsense Reasoning via Knowledge-Driven Data Synthesis
Mar 08, 2025Current evaluations of commonsense reasoning in LLMs are hindered by the scarcity of natural language corpora with structured annotations for reasoning tasks. To address this, we introduce KnowLogic, a benchmark generated through a knowledge-driven synthetic data strategy. KnowLogic integrates diverse commonsense knowledge, plausible scenarios, and various types of logical reasoning. One of the key advantages of KnowLogic is its adjustable difficulty levels, allowing for flexible control over question complexity. It also includes fine-grained labels for in-depth evaluation of LLMs' reasoning abilities across multiple dimensions. Our benchmark consists of 3,000 bilingual (Chinese and English) questions across various domains, and presents significant challenges for current LLMs, with the highest-performing model achieving only 69.57\%. Our analysis highlights common errors, such as misunderstandings of low-frequency commonsense, logical inconsistencies, and overthinking. This approach, along with our benchmark, provides a valuable tool for assessing and enhancing LLMs' commonsense reasoning capabilities and can be applied to a wide range of knowledge domains.
Be a Multitude to Itself: A Prompt Evolution Framework for Red Teaming
Feb 22, 2025



Large Language Models (LLMs) have gained increasing attention for their remarkable capacity, alongside concerns about safety arising from their potential to produce harmful content. Red teaming aims to find prompts that could elicit harmful responses from LLMs, and is essential to discover and mitigate safety risks before real-world deployment. However, manual red teaming is both time-consuming and expensive, rendering it unscalable. In this paper, we propose RTPE, a scalable evolution framework to evolve red teaming prompts across both breadth and depth dimensions, facilitating the automatic generation of numerous high-quality and diverse red teaming prompts. Specifically, in-breadth evolving employs a novel enhanced in-context learning method to create a multitude of quality prompts, whereas in-depth evolving applies customized transformation operations to enhance both content and form of prompts, thereby increasing diversity. Extensive experiments demonstrate that RTPE surpasses existing representative automatic red teaming methods on both attack success rate and diversity. In addition, based on 4,800 red teaming prompts created by RTPE, we further provide a systematic analysis of 8 representative LLMs across 8 sensitive topics.
Plug-and-Play Training Framework for Preference Optimization
Dec 30, 2024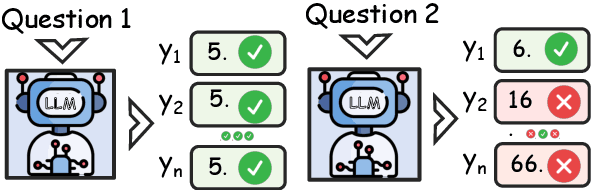
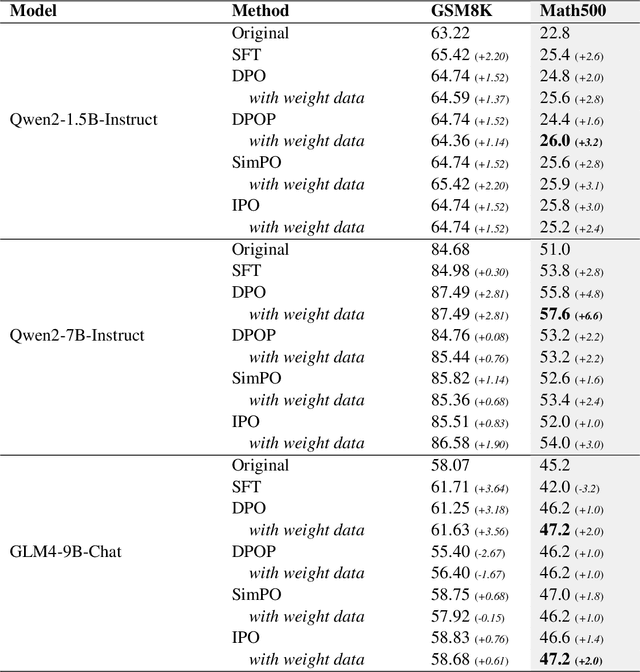
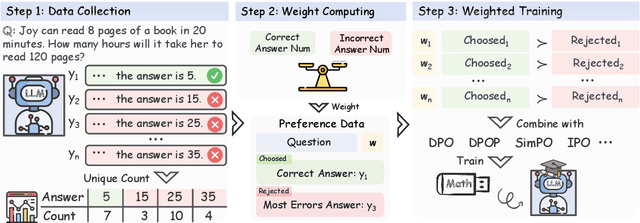
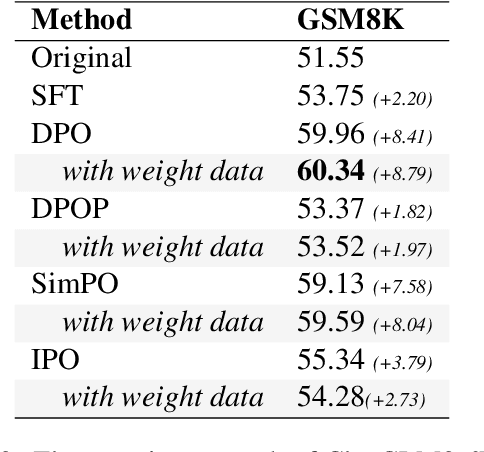
Recently, preference optimization methods such as DPO have significantly enhanced large language models (LLMs) in wide tasks including dialogue and question-answering. However, current methods fail to account for the varying difficulty levels of training samples during preference optimization, leading to mediocre performance in tasks with high accuracy requirements, particularly in mathematical reasoning. To address this limitation, we propose a novel training framework, which employs multiple sampling to analyze output distributions, assign different weights to samples, and incorporate these weights into the preference optimization process. This plug-and-play approach enables LLMs to prioritize challenging examples during training, improving learning efficiency. Experimental results demonstrate that our framework integrates seamlessly with various preference optimization methods and achieves consistent improvements in mathematical reasoning tasks.
Large Language Models Are Unconscious of Unreasonability in Math Problems
Mar 28, 2024



Large language models (LLMs) demonstrate substantial capabilities in solving math problems. However, they tend to produce hallucinations when given questions containing unreasonable errors. In this paper, we study the behavior of LLMs when faced with unreasonable math problems and further explore their potential to address these problems. First, we construct the Unreasonable Math Problem (UMP) benchmark to examine the error detection ability of LLMs. Experiments show that LLMs are able to detect unreasonable errors, but still fail in generating non-hallucinatory content. In order to improve their ability of error detection and correction, we further design a strategic prompt template called Critical Calculation and Conclusion(CCC). With CCC, LLMs can better self-evaluate and detect unreasonable errors in math questions, making them more reliable and safe in practical application scenarios.
ShieldLM: Empowering LLMs as Aligned, Customizable and Explainable Safety Detectors
Feb 26, 2024



The safety of Large Language Models (LLMs) has gained increasing attention in recent years, but there still lacks a comprehensive approach for detecting safety issues within LLMs' responses in an aligned, customizable and explainable manner. In this paper, we propose ShieldLM, an LLM-based safety detector, which aligns with general human safety standards, supports customizable detection rules, and provides explanations for its decisions. To train ShieldLM, we compile a large bilingual dataset comprising 14,387 query-response pairs, annotating the safety of responses based on various safety standards. Through extensive experiments, we demonstrate that ShieldLM surpasses strong baselines across four test sets, showcasing remarkable customizability and explainability. Besides performing well on standard detection datasets, ShieldLM has also been shown to be effective in real-world situations as a safety evaluator for advanced LLMs. We release ShieldLM at \url{https://github.com/thu-coai/ShieldLM} to support accurate and explainable safety detection under various safety standards, contributing to the ongoing efforts to enhance the safety of LLMs.
Rethinking Node-wise Propagation for Large-scale Graph Learning
Feb 09, 2024Scalable graph neural networks (GNNs) have emerged as a promising technique, which exhibits superior predictive performance and high running efficiency across numerous large-scale graph-based web applications. However, (i) Most scalable GNNs tend to treat all nodes in graphs with the same propagation rules, neglecting their topological uniqueness; (ii) Existing node-wise propagation optimization strategies are insufficient on web-scale graphs with intricate topology, where a full portrayal of nodes' local properties is required. Intuitively, different nodes in web-scale graphs possess distinct topological roles, and therefore propagating them indiscriminately or neglect local contexts may compromise the quality of node representations. This intricate topology in web-scale graphs cannot be matched by small-scale scenarios. To address the above issues, we propose \textbf{A}daptive \textbf{T}opology-aware \textbf{P}ropagation (ATP), which reduces potential high-bias propagation and extracts structural patterns of each node in a scalable manner to improve running efficiency and predictive performance. Remarkably, ATP is crafted to be a plug-and-play node-wise propagation optimization strategy, allowing for offline execution independent of the graph learning process in a new perspective. Therefore, this approach can be seamlessly integrated into most scalable GNNs while remain orthogonal to existing node-wise propagation optimization strategies. Extensive experiments on 12 datasets, including the most representative large-scale ogbn-papers100M, have demonstrated the effectiveness of ATP. Specifically, ATP has proven to be efficient in improving the performance of prevalent scalable GNNs for semi-supervised node classification while addressing redundant computational costs.