 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Boundary Integral-based Neural Operator for Mesh Deformation
Mar 03, 2026This paper presents an efficient mesh deformation method based on boundary integration and neural operators, formulating the problem as a linear elasticity boundary value problem (BVP). To overcome the high computational cost of traditional finite element methods and the limitations of existing neural operators in handling Dirichlet boundary conditions for vector fields, we introduce a direct boundary integral representation using a Dirichlet-type Green's tensor. This formulation expresses the internal displacement field solely as a function of boundary displacements, eliminating the need to solve for unknown tractions. Building on this, we design a Boundary-Integral-based Neural Operator (BINO) that learns the geometry- and material-aware Green's traction kernel. A key technical advantage of our framework is the mathematical decoupling of the physical integration process from the geometric representation via geometric descriptors. While this study primarily demonstrates robust generalization across diverse boundary conditions, the architecture inherently possesses potential for cross-geometry adaptation. Numerical experiments, including large deformations of flexible beams and rigid-body motions of NACA airfoils, confirm the model's high accuracy and strict adherence to the principles of linearity and superposition. The results demonstrate that the proposed framework ensures mesh quality and computational efficiency, providing a reliable new paradigm for parametric mesh generation and shape optimization in engineering.
TFPS: A Temporal Filtration-enhanced Positive Sample Set Construction Method for Implicit Collaborative Filtering
Feb 26, 2026The negative sampling strategy can effectively train collaborative filtering (CF) recommendation models based on implicit feedback by constructing positive and negative samples. However, existing methods primarily optimize the negative sampling process while neglecting the exploration of positive samples. Some denoising recommendation methods can be applied to denoise positive samples within negative sampling strategies, but they ignore temporal information. Existing work integrates sequential information during model aggregation but neglects time interval information, hindering accurate capture of users' current preferences. To address this problem, from a data perspective, we propose a novel temporal filtration-enhanced approach to construct a high-quality positive sample set. First, we design a time decay model based on interaction time intervals, transforming the original graph into a weighted user-item bipartite graph. Then, based on predefined filtering operations, the weighted user-item bipartite graph is layered. Finally, we design a layer-enhancement strategy to construct a high-quality positive sample set for the layered subgraphs. We provide theoretical insights into why TFPS can improve Recall@k and NDCG@k, and extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed method. Additionally, TFPS can be integrated with various implicit CF recommenders or negative sampling methods to enhance its performance.
LION: A Clifford Neural Paradigm for Multimodal-Attributed Graph Learning
Jan 29, 2026Recently, the rapid advancement of multimodal domains has driven a data-centric paradigm shift in graph ML, transitioning from text-attributed to multimodal-attributed graphs. This advancement significantly enhances data representation and expands the scope of graph downstream tasks, such as modality-oriented tasks, thereby improving the practical utility of graph ML. Despite its promise, limitations exist in the current neural paradigms: (1) Neglect Context in Modality Alignment: Most existing methods adopt topology-constrained or modality-specific operators as tokenizers. These aligners inevitably neglect graph context and inhibit modality interaction, resulting in suboptimal alignment. (2) Lack of Adaptation in Modality Fusion: Most existing methods are simple adaptations for 2-modality graphs and fail to adequately exploit aligned tokens equipped with topology priors during fusion, leading to poor generalizability and performance degradation. To address the above issues, we propose LION (c\underline{LI}ff\underline{O}rd \underline{N}eural paradigm) based on the Clifford algebra and decoupled graph neural paradigm (i.e., propagation-then-aggregation) to implement alignment-then-fusion in multimodal-attributed graphs. Specifically, we first construct a modality-aware geometric manifold grounded in Clifford algebra. This geometric-induced high-order graph propagation efficiently achieves modality interaction, facilitating modality alignment. Then, based on the geometric grade properties of aligned tokens, we propose adaptive holographic aggregation. This module integrates the energy and scale of geometric grades with learnable parameters to improve modality fusion. Extensive experiments on 9 datasets demonstrate that LION significantly outperforms SOTA baselines across 3 graph and 3 modality downstream tasks.
FedBook: A Unified Federated Graph Foundation Codebook with Intra-domain and Inter-domain Knowledge Modeling
Oct 09, 2025Foundation models have shown remarkable cross-domain generalization in language and vision, inspiring the development of graph foundation models (GFMs). However, existing GFMs typically assume centralized access to multi-domain graphs, which is often infeasible due to privacy and institutional constraints. Federated Graph Foundation Models (FedGFMs) address this limitation, but their effectiveness fundamentally hinges on constructing a robust global codebook that achieves intra-domain coherence by consolidating mutually reinforcing semantics within each domain, while also maintaining inter-domain diversity by retaining heterogeneous knowledge across domains. To this end, we propose FedBook, a unified federated graph foundation codebook that systematically aggregates clients' local codebooks during server-side federated pre-training. FedBook follows a two-phase process: (1) Intra-domain Collaboration, where low-frequency tokens are refined by referencing more semantically reliable high-frequency tokens across clients to enhance domain-specific coherence; and (2) Inter-domain Integration, where client contributions are weighted by the semantic distinctiveness of their codebooks during the aggregation of the global GFM, thereby preserving cross-domain diversity. Extensive experiments on 8 benchmarks across multiple domains and tasks demonstrate that FedBook consistently outperforms 21 baselines, including isolated supervised learning, FL/FGL, federated adaptations of centralized GFMs, and FedGFM techniques.
A Comprehensive Data-centric Overview of Federated Graph Learning
Jul 22, 2025In the era of big data applications, Federated Graph Learning (FGL) has emerged as a prominent solution that reconcile the tradeoff between optimizing the collective intelligence between decentralized datasets holders and preserving sensitive information to maximum. Existing FGL surveys have contributed meaningfully but largely focus on integrating Federated Learning (FL) and Graph Machine Learning (GML), resulting in early stage taxonomies that emphasis on methodology and simulated scenarios. Notably, a data centric perspective, which systematically examines FGL methods through the lens of data properties and usage, remains unadapted to reorganize FGL research, yet it is critical to assess how FGL studies manage to tackle data centric constraints to enhance model performances. This survey propose a two-level data centric taxonomy: Data Characteristics, which categorizes studies based on the structural and distributional properties of datasets used in FGL, and Data Utilization, which analyzes the training procedures and techniques employed to overcome key data centric challenges. Each taxonomy level is defined by three orthogonal criteria, each representing a distinct data centric configuration. Beyond taxonomy, this survey examines FGL integration with Pretrained Large Models, showcases realistic applications, and highlights future direction aligned with emerging trends in GML.
Toward Data-centric Directed Graph Learning: An Entropy-driven Approach
May 02, 2025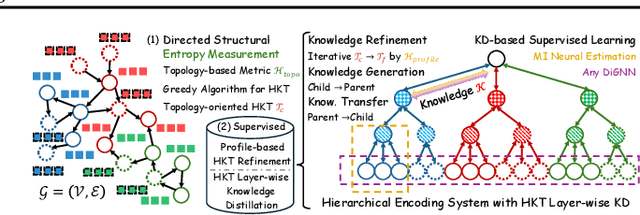
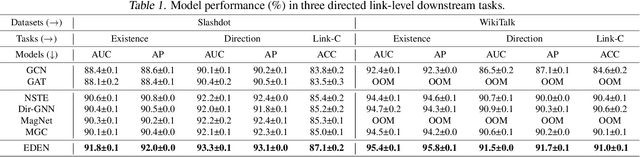
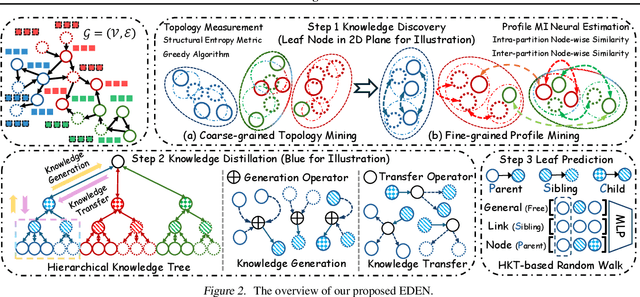
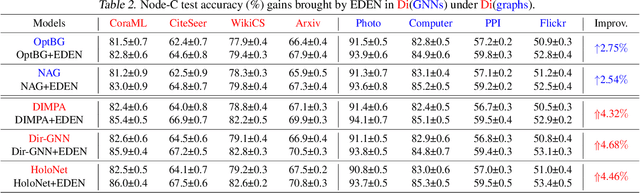
The directed graph (digraph), as a generalization of undirected graphs, exhibits superior representation capability in modeling complex topology systems and has garnered considerable attention in recent years. Despite the notable efforts made by existing DiGraph Neural Networks (DiGNNs) to leverage directed edges, they still fail to comprehensively delve into the abundant data knowledge concealed in the digraphs. This data-level limitation results in model-level sub-optimal predictive performance and underscores the necessity of further exploring the potential correlations between the directed edges (topology) and node profiles (feature and labels) from a data-centric perspective, thereby empowering model-centric neural networks with stronger encoding capabilities. In this paper, we propose \textbf{E}ntropy-driven \textbf{D}igraph knowl\textbf{E}dge distillatio\textbf{N} (EDEN), which can serve as a data-centric digraph learning paradigm or a model-agnostic hot-and-plug data-centric Knowledge Distillation (KD) module. The core idea is to achieve data-centric ML, guided by our proposed hierarchical encoding theory for structured data. Specifically, EDEN first utilizes directed structural measurements from a topology perspective to construct a coarse-grained Hierarchical Knowledge Tree (HKT). Subsequently, EDEN quantifies the mutual information of node profiles to refine knowledge flow in the HKT, enabling data-centric KD supervision within model training. As a general framework, EDEN can also naturally extend to undirected scenarios and demonstrate satisfactory performance. In our experiments, EDEN has been widely evaluated on 14 (di)graph datasets (homophily and heterophily) and across 4 downstream tasks. The results demonstrate that EDEN attains SOTA performance and exhibits strong improvement for prevalent (Di)GNNs.
Towards Unbiased Federated Graph Learning: Label and Topology Perspectives
Apr 14, 2025Federated Graph Learning (FGL) enables privacy-preserving, distributed training of graph neural networks without sharing raw data. Among its approaches, subgraph-FL has become the dominant paradigm, with most work focused on improving overall node classification accuracy. However, these methods often overlook fairness due to the complexity of node features, labels, and graph structures. In particular, they perform poorly on nodes with disadvantaged properties, such as being in the minority class within subgraphs or having heterophilous connections (neighbors with dissimilar labels or misleading features). This reveals a critical issue: high accuracy can mask degraded performance on structurally or semantically marginalized nodes. To address this, we advocate for two fairness goals: (1) improving representation of minority class nodes for class-wise fairness and (2) mitigating topological bias from heterophilous connections for topology-aware fairness. We propose FairFGL, a novel framework that enhances fairness through fine-grained graph mining and collaborative learning. On the client side, the History-Preserving Module prevents overfitting to dominant local classes, while the Majority Alignment Module refines representations of heterophilous majority-class nodes. The Gradient Modification Module transfers minority-class knowledge from structurally favorable clients to improve fairness. On the server side, FairFGL uploads only the most influenced subset of parameters to reduce communication costs and better reflect local distributions. A cluster-based aggregation strategy reconciles conflicting updates and curbs global majority dominance . Extensive evaluations on eight benchmarks show FairFGL significantly improves minority-group performance , achieving up to a 22.62 percent Macro-F1 gain while enhancing convergence over state-of-the-art baselines.
Federated Prototype Graph Learning
Apr 13, 2025In recent years, Federated Graph Learning (FGL) has gained significant attention for its distributed training capabilities in graph-based machine intelligence applications, mitigating data silos while offering a new perspective for privacy-preserve large-scale graph learning. However, multi-level FGL heterogeneity presents various client-server collaboration challenges: (1) Model-level: The variation in clients for expected performance and scalability necessitates the deployment of heterogeneous models. Unfortunately, most FGL methods rigidly demand identical client models due to the direct model weight aggregation on the server. (2) Data-level: The intricate nature of graphs, marked by the entanglement of node profiles and topology, poses an optimization dilemma. This implies that models obtained by federated training struggle to achieve superior performance. (3) Communication-level: Some FGL methods attempt to increase message sharing among clients or between clients and the server to improve training, which inevitably leads to high communication costs. In this paper, we propose FedPG as a general prototype-guided optimization method for the above multi-level FGL heterogeneity. Specifically, on the client side, we integrate multi-level topology-aware prototypes to capture local graph semantics. Subsequently, on the server side, leveraging the uploaded prototypes, we employ topology-guided contrastive learning and personalized technology to tailor global prototypes for each client, broadcasting them to improve local training. Experiments demonstrate that FedPG outperforms SOTA baselines by an average of 3.57\% in accuracy while reducing communication costs by 168x.
Toward Effective Digraph Representation Learning: A Magnetic Adaptive Propagation based Approach
Jan 21, 2025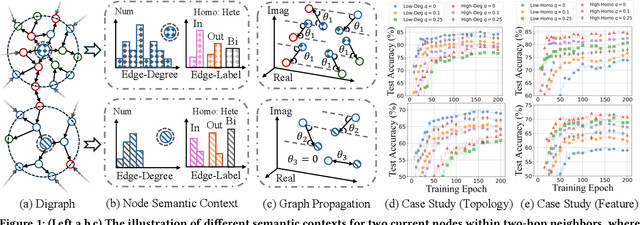
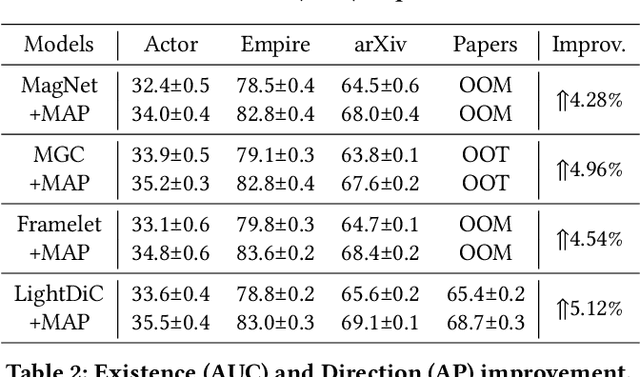
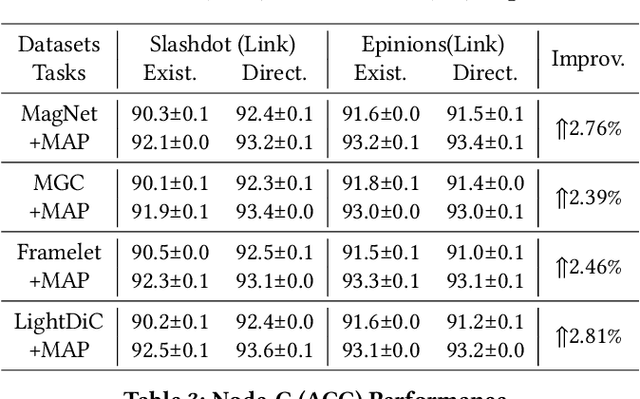
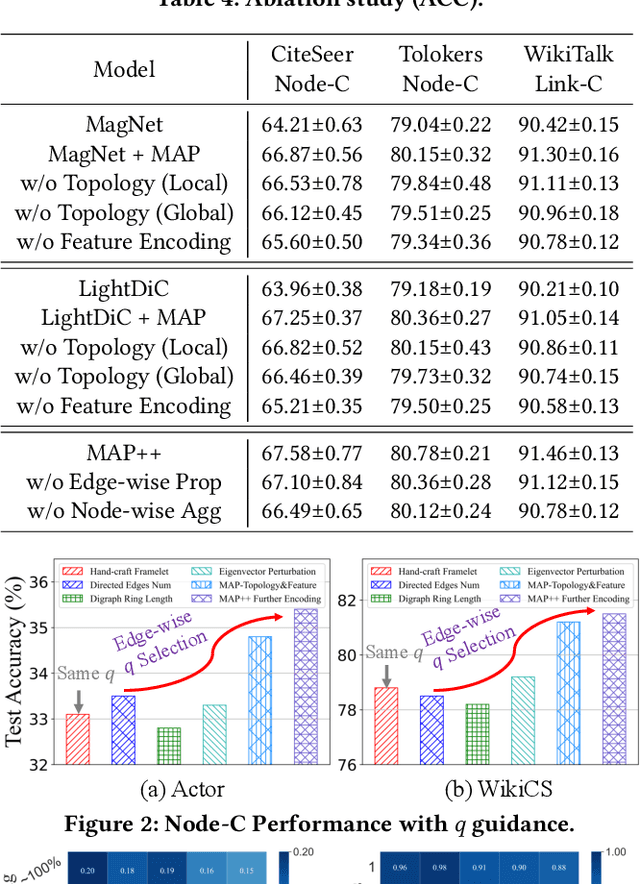
The $q$-parameterized magnetic Laplacian serves as the foundation of directed graph (digraph) convolution, enabling this kind of digraph neural network (MagDG) to encode node features and structural insights by complex-domain message passing. As a generalization of undirected methods, MagDG shows superior capability in modeling intricate web-scale topology. Despite the great success achieved by existing MagDGs, limitations still exist: (1) Hand-crafted $q$: The performance of MagDGs depends on selecting an appropriate $q$-parameter to construct suitable graph propagation equations in the complex domain. This parameter tuning, driven by downstream tasks, limits model flexibility and significantly increases manual effort. (2) Coarse Message Passing: Most approaches treat all nodes with the same complex-domain propagation and aggregation rules, neglecting their unique digraph contexts. This oversight results in sub-optimal performance. To address the above issues, we propose two key techniques: (1) MAP is crafted to be a plug-and-play complex-domain propagation optimization strategy in the context of digraph learning, enabling seamless integration into any MagDG to improve predictions while enjoying high running efficiency. (2) MAP++ is a new digraph learning framework, further incorporating a learnable mechanism to achieve adaptively edge-wise propagation and node-wise aggregation in the complex domain for better performance. Extensive experiments on 12 datasets demonstrate that MAP enjoys flexibility for it can be incorporated with any MagDG, and scalability as it can deal with web-scale digraphs. MAP++ achieves SOTA predictive performance on 4 different downstream tasks.
Toward Scalable Graph Unlearning: A Node Influence Maximization based Approach
Jan 21, 2025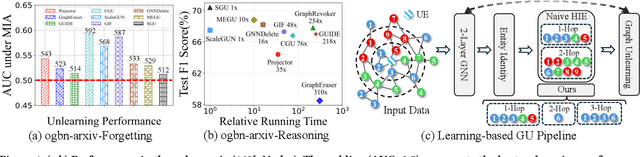
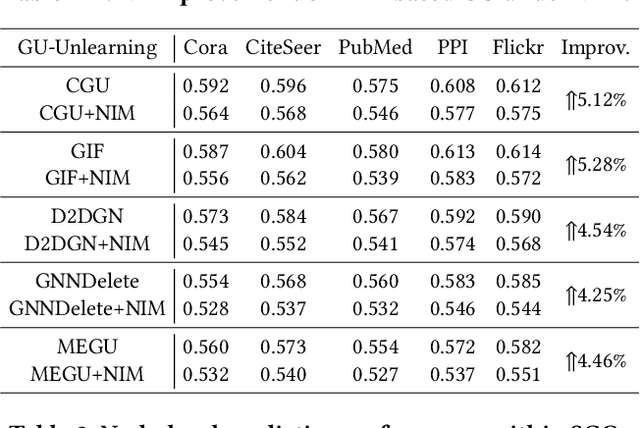
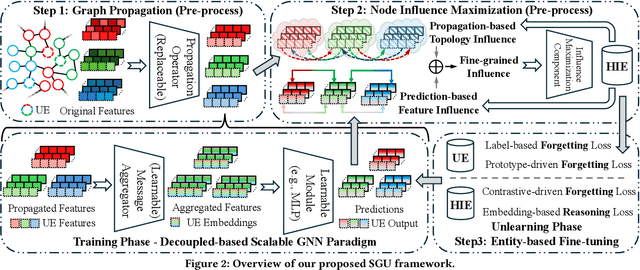
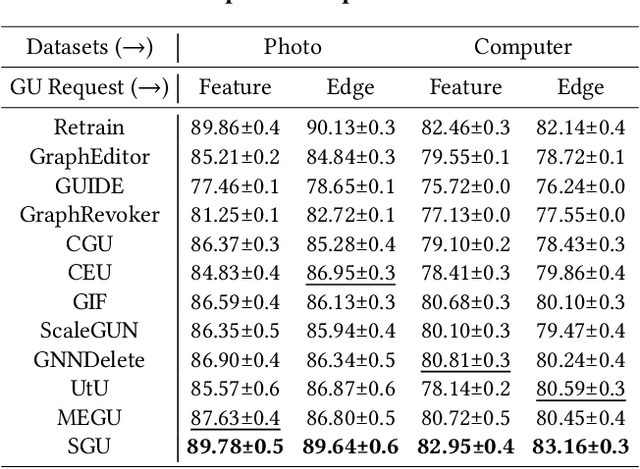
Machine unlearning, as a pivotal technology for enhancing model robustness and data privacy, has garnered significant attention in prevalent web mining applications, especially in thriving graph-based scenarios. However, most existing graph unlearning (GU) approaches face significant challenges due to the intricate interactions among web-scale graph elements during the model training: (1) The gradient-driven node entanglement hinders the complete knowledge removal in response to unlearning requests; (2) The billion-level graph elements in the web scenarios present inevitable scalability issues. To break the above limitations, we open up a new perspective by drawing a connection between GU and conventional social influence maximization. To this end, we propose Node Influence Maximization (NIM) through the decoupled influence propagation model and fine-grained influence function in a scalable manner, which is crafted to be a plug-and-play strategy to identify potential nodes affected by unlearning entities. This approach enables offline execution independent of GU, allowing it to be seamlessly integrated into most GU methods to improve their unlearning performance. Based on this, we introduce Scalable Graph Unlearning (SGU) as a new fine-tuned framework, which balances the forgetting and reasoning capability of the unlearned model by entity-specific optimizations. Extensive experiments on 14 datasets, including large-scale ogbn-papers100M, have demonstrated the effectiveness of our approach. Specifically, NIM enhances the forgetting capability of most GU methods, while SGU achieves comprehensive SOTA performance and maintains scalability.