 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoSci: A Memory-Centric Agentic System for the Full Scientific Research Lifecycle
May 29, 2026Scientific research has traditionally been human-intensive, requiring researchers to coordinate literature, ideas, experiments, manuscripts, and review responses across long project cycles. The rise of LLM-based scientific agents creates an opportunity to automate this process. Such a system must support the full research lifecycle, maintain structured persistent memory across projects, and improve its own research procedures over time. However, existing systems either partially satisfy or fail to satisfy these requirements, leaving a gap for a unified automated scientific research system. As a result, we present AutoSci, a memory-centric agentic system for the full scientific research lifecycle. AutoSci is organized around four modules. SciMem provides schema-governed research memory, separating Long-Term Knowledge Memory for reusable scientific knowledge from Active Research Memory for project-level artifacts such as ideas, experiments, manuscripts, and reviews. SciFlow executes a five-stage lifecycle from literature understanding to rebuttal through a harness that controls state, context, verification, feedback, and orchestration. SciDAG augments difficult skills with DAG-shaped multi-agent operators and reusable stage-specific templates. SciEvolve converts feedback signals from users, experiments, reviews, and external environments into versioned updates to SciMem organization, SciFlow skills, and SciDAG templates. Together, these modules make AutoSci a persistent research environment that can execute, remember, and evolve across research projects. The code repository is available at https://github.com/skyllwt/AutoSci.
OpenMAG: A Comprehensive Benchmark for Multimodal-Attributed Graph
Feb 05, 2026Multimodal-Attributed Graph (MAG) learning has achieved remarkable success in modeling complex real-world systems by integrating graph topology with rich attributes from multiple modalities. With the rapid proliferation of novel MAG models capable of handling intricate cross-modal semantics and structural dependencies, establishing a rigorous and unified evaluation standard has become imperative. Although existing benchmarks have facilitated initial progress, they exhibit critical limitations in domain coverage, encoder flexibility, model diversity, and task scope, presenting significant challenges to fair evaluation. To bridge this gap, we present OpenMAG, a comprehensive benchmark that integrates 19 datasets across 6 domains and incorporates 16 encoders to support both static and trainable feature encoding. OpenMAG further implements a standardized library of 24 state-of-the-art models and supports 8 downstream tasks, enabling fair comparisons within a unified framework. Through systematic assessment of necessity, data quality, effectiveness, robustness, and efficiency, we derive 14 fundamental insights into MAG learning to guide future advancements. Our code is available at https://github.com/YUKI-N810/OpenMAG.
OpenDDI: A Comprehensive Benchmark for DDI Prediction
Jan 31, 2026Drug-Drug Interactions (DDIs) significantly influence therapeutic efficacy and patient safety. As experimental discovery is resource-intensive and time-consuming, efficient computational methodologies have become essential. The predominant paradigm formulates DDI prediction as a drug graph-based link prediction task. However, further progress is hindered by two fundamental challenges: (1) lack of high-quality data: most studies rely on small-scale DDI datasets and single-modal drug representations; (2) lack of standardized evaluation: inconsistent scenarios, varied metrics, and diverse baselines. To address the above issues, we propose OpenDDI, a comprehensive benchmark for DDI prediction. Specifically, (1) from the data perspective, OpenDDI unifies 6 widely used DDI datasets and 2 existing forms of drug representation, while additionally contributing 3 new large-scale LLM-augmented datasets and a new multimodal drug representation covering 5 modalities. (2) From the evaluation perspective, OpenDDI unifies 20 SOTA model baselines across 3 downstream tasks, with standardized protocols for data quality, effectiveness, generalization, robustness, and efficiency. Based on OpenDDI, we conduct a comprehensive evaluation and derive 10 valuable insights for DDI prediction while exposing current limitations to provide critical guidance for this rapidly evolving field. Our code is available at https://github.com/xiaoriwuguang/OpenDDI
MM-OpenFGL: A Comprehensive Benchmark for Multimodal Federated Graph Learning
Jan 29, 2026Multimodal-attributed graphs (MMAGs) provide a unified framework for modeling complex relational data by integrating heterogeneous modalities with graph structures. While centralized learning has shown promising performance, MMAGs in real-world applications are often distributed across isolated platforms and cannot be shared due to privacy concerns or commercial constraints. Federated graph learning (FGL) offers a natural solution for collaborative training under such settings; however, existing studies largely focus on single-modality graphs and do not adequately address the challenges unique to multimodal federated graph learning (MMFGL). To bridge this gap, we present MM-OpenFGL, the first comprehensive benchmark that systematically formalizes the MMFGL paradigm and enables rigorous evaluation. MM-OpenFGL comprises 19 multimodal datasets spanning 7 application domains, 8 simulation strategies capturing modality and topology variations, 6 downstream tasks, and 57 state-of-the-art methods implemented through a modular API. Extensive experiments investigate MMFGL from the perspectives of necessity, effectiveness, robustness, and efficiency, offering valuable insights for future research on MMFGL.
Towards Unbiased Federated Graph Learning: Label and Topology Perspectives
Apr 14, 2025Federated Graph Learning (FGL) enables privacy-preserving, distributed training of graph neural networks without sharing raw data. Among its approaches, subgraph-FL has become the dominant paradigm, with most work focused on improving overall node classification accuracy. However, these methods often overlook fairness due to the complexity of node features, labels, and graph structures. In particular, they perform poorly on nodes with disadvantaged properties, such as being in the minority class within subgraphs or having heterophilous connections (neighbors with dissimilar labels or misleading features). This reveals a critical issue: high accuracy can mask degraded performance on structurally or semantically marginalized nodes. To address this, we advocate for two fairness goals: (1) improving representation of minority class nodes for class-wise fairness and (2) mitigating topological bias from heterophilous connections for topology-aware fairness. We propose FairFGL, a novel framework that enhances fairness through fine-grained graph mining and collaborative learning. On the client side, the History-Preserving Module prevents overfitting to dominant local classes, while the Majority Alignment Module refines representations of heterophilous majority-class nodes. The Gradient Modification Module transfers minority-class knowledge from structurally favorable clients to improve fairness. On the server side, FairFGL uploads only the most influenced subset of parameters to reduce communication costs and better reflect local distributions. A cluster-based aggregation strategy reconciles conflicting updates and curbs global majority dominance . Extensive evaluations on eight benchmarks show FairFGL significantly improves minority-group performance , achieving up to a 22.62 percent Macro-F1 gain while enhancing convergence over state-of-the-art baselines.
Toward Scalable Graph Unlearning: A Node Influence Maximization based Approach
Jan 21, 2025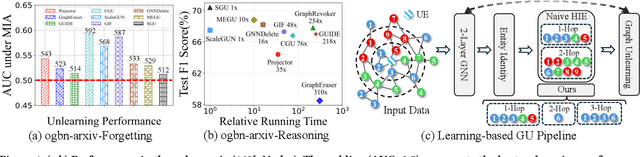
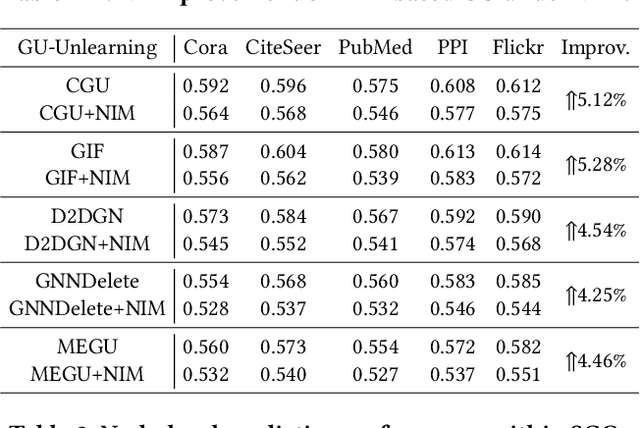
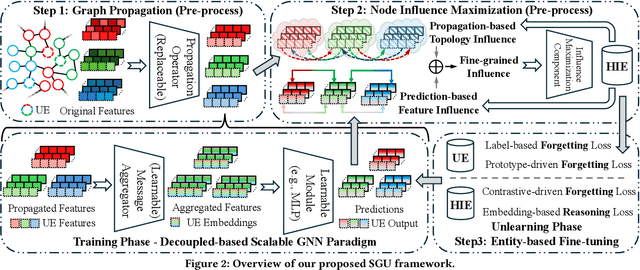
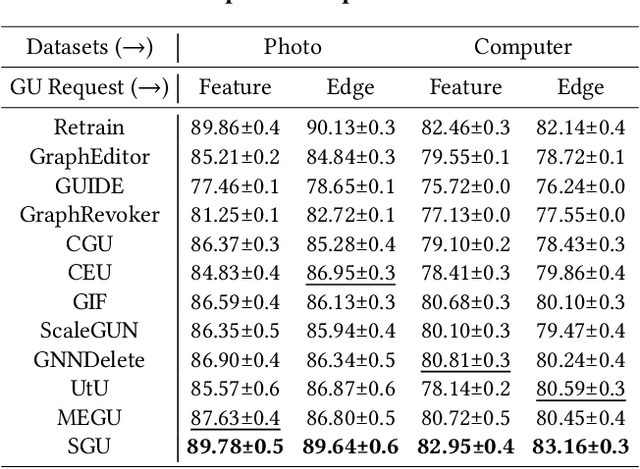
Machine unlearning, as a pivotal technology for enhancing model robustness and data privacy, has garnered significant attention in prevalent web mining applications, especially in thriving graph-based scenarios. However, most existing graph unlearning (GU) approaches face significant challenges due to the intricate interactions among web-scale graph elements during the model training: (1) The gradient-driven node entanglement hinders the complete knowledge removal in response to unlearning requests; (2) The billion-level graph elements in the web scenarios present inevitable scalability issues. To break the above limitations, we open up a new perspective by drawing a connection between GU and conventional social influence maximization. To this end, we propose Node Influence Maximization (NIM) through the decoupled influence propagation model and fine-grained influence function in a scalable manner, which is crafted to be a plug-and-play strategy to identify potential nodes affected by unlearning entities. This approach enables offline execution independent of GU, allowing it to be seamlessly integrated into most GU methods to improve their unlearning performance. Based on this, we introduce Scalable Graph Unlearning (SGU) as a new fine-tuned framework, which balances the forgetting and reasoning capability of the unlearned model by entity-specific optimizations. Extensive experiments on 14 datasets, including large-scale ogbn-papers100M, have demonstrated the effectiveness of our approach. Specifically, NIM enhances the forgetting capability of most GU methods, while SGU achieves comprehensive SOTA performance and maintains scalability.
OpenGU: A Comprehensive Benchmark for Graph Unlearning
Jan 06, 2025



Graph Machine Learning is essential for understanding and analyzing relational data. However, privacy-sensitive applications demand the ability to efficiently remove sensitive information from trained graph neural networks (GNNs), avoiding the unnecessary time and space overhead caused by retraining models from scratch. To address this issue, Graph Unlearning (GU) has emerged as a critical solution, with the potential to support dynamic graph updates in data management systems and enable scalable unlearning in distributed data systems while ensuring privacy compliance. Unlike machine unlearning in computer vision or other fields, GU faces unique difficulties due to the non-Euclidean nature of graph data and the recursive message-passing mechanism of GNNs. Additionally, the diversity of downstream tasks and the complexity of unlearning requests further amplify these challenges. Despite the proliferation of diverse GU strategies, the absence of a benchmark providing fair comparisons for GU, and the limited flexibility in combining downstream tasks and unlearning requests, have yielded inconsistencies in evaluations, hindering the development of this domain. To fill this gap, we present OpenGU, the first GU benchmark, where 16 SOTA GU algorithms and 37 multi-domain datasets are integrated, enabling various downstream tasks with 13 GNN backbones when responding to flexible unlearning requests. Based on this unified benchmark framework, we are able to provide a comprehensive and fair evaluation for GU. Through extensive experimentation, we have drawn $8$ crucial conclusions about existing GU methods, while also gaining valuable insights into their limitations, shedding light on potential avenues for future research.
Collision-Free Navigation of Wheeled Mobile Robots: An Integrated Path Planning and Tube-Following Control Approach
Dec 19, 2023



In this paper, an integrated path planning and tube-following control scheme is proposed for collision-free navigation of a wheeled mobile robot (WMR) in a compact convex workspace cluttered with sufficiently separated spherical obstacles. An analytical path planning algorithm is developed based on Bouligand's tangent cones and Nagumo's invariance theorem, which enables the WMR to navigate towards a designated goal location from almost all initial positions in the free space, without entering into augmented obstacle regions with safety margins. We further construct a virtual "safe tube" around the reference trajectory, ensuring that its radius does not exceed the size of the safety margin. Subsequently, a saturated adaptive controller is designed to achieve safe trajectory tracking in the presence of disturbances. It is shown that this tube-following controller guarantees that the WMR tracks the reference trajectory within the predefined tube, while achieving uniform ultimate boundedness of both the position tracking and parameter estimation errors. This indicates that the WMR will not collide with any obstacles along the way. Finally, we report simulation and experimental results to validate the effectiveness of the proposed method.
Unsupervised Manifold Alignment with Joint Multidimensional Scaling
Jul 06, 2022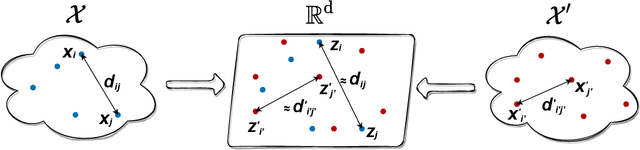
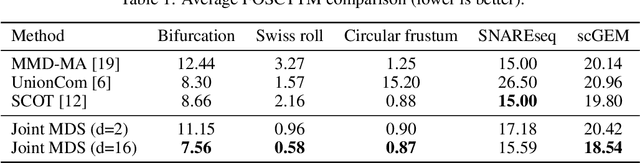
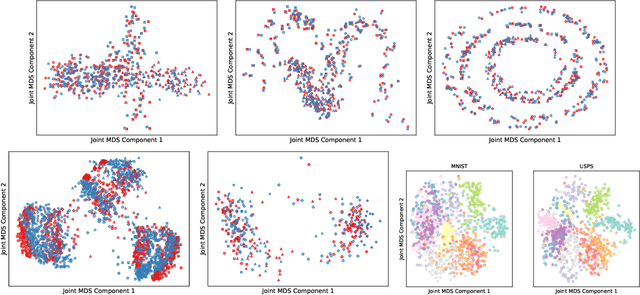

We introduce Joint Multidimensional Scaling, a novel approach for unsupervised manifold alignment, which maps datasets from two different domains, without any known correspondences between data instances across the datasets, to a common low-dimensional Euclidean space. Our approach integrates Multidimensional Scaling (MDS) and Wasserstein Procrustes analysis into a joint optimization problem to simultaneously generate isometric embeddings of data and learn correspondences between instances from two different datasets, while only requiring intra-dataset pairwise dissimilarities as input. This unique characteristic makes our approach applicable to datasets without access to the input features, such as solving the inexact graph matching problem. We propose an alternating optimization scheme to solve the problem that can fully benefit from the optimization techniques for MDS and Wasserstein Procrustes. We demonstrate the effectiveness of our approach in several applications, including joint visualization of two datasets, unsupervised heterogeneous domain adaptation, graph matching, and protein structure alignment.