 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Fold Classification at Scale: Benchmarking and Pretraining
May 18, 2026Classifying protein topology is essential for deciphering biological function, but progress is held back by the lack of large-scale benchmarks that avoid duplicates and by models that do not scale well. We introduce TEDBench, a large-scale, non-redundant benchmark for protein fold classification constructed from the Encyclopedia of Domains (TED) and Foldseek-clustered AlphaFold structures. We show that on TEDBench, current protein representation learning methods either require very large models or fail to deliver strong performance. To address this challenge, we propose Masked Invariant Autoencoders (MiAE), a self-supervised framework for protein structure representation learning. MiAE uses an extremely high masking ratio of up to 90% with an $\mathrm{SE(3)}$-invariant encoder and a lightweight decoder that reconstructs backbone coordinates from the latent representation and mask tokens. MiAE scales well and outperforms supervised counterparts and state-of-the-art baselines on TEDBench, establishing a strong recipe for protein fold classification. To test transfer beyond AlphaFold structures, we further benchmark on a curated dataset from experimental structures of CATH v4.4. TEDBench is available at https://github.com/BorgwardtLab/TEDBench.
Learning Laplacian Positional Encodings for Heterophilous Graphs
Apr 29, 2025In this work, we theoretically demonstrate that current graph positional encodings (PEs) are not beneficial and could potentially hurt performance in tasks involving heterophilous graphs, where nodes that are close tend to have different labels. This limitation is critical as many real-world networks exhibit heterophily, and even highly homophilous graphs can contain local regions of strong heterophily. To address this limitation, we propose Learnable Laplacian Positional Encodings (LLPE), a new PE that leverages the full spectrum of the graph Laplacian, enabling them to capture graph structure on both homophilous and heterophilous graphs. Theoretically, we prove LLPE's ability to approximate a general class of graph distances and demonstrate its generalization properties. Empirically, our evaluation on 12 benchmarks demonstrates that LLPE improves accuracy across a variety of GNNs, including graph transformers, by up to 35% and 14% on synthetic and real-world graphs, respectively. Going forward, our work represents a significant step towards developing PEs that effectively capture complex structures in heterophilous graphs.
Flatten Graphs as Sequences: Transformers are Scalable Graph Generators
Feb 04, 2025

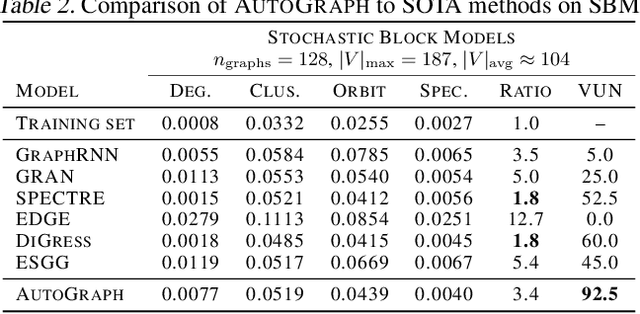

We introduce AutoGraph, a novel autoregressive framework for generating large attributed graphs using decoder-only transformers. At the core of our approach is a reversible "flattening" process that transforms graphs into random sequences. By sampling and learning from these sequences, AutoGraph enables transformers to model and generate complex graph structures in a manner akin to natural language. In contrast to diffusion models that rely on computationally intensive node features, our approach operates exclusively on these sequences. The sampling complexity and sequence length scale linearly with the number of edges, making AutoGraph highly scalable for generating large sparse graphs. Empirically, AutoGraph achieves state-of-the-art performance across diverse synthetic and molecular graph generation benchmarks, while delivering a 100-fold generation and a 3-fold training speedup compared to leading diffusion models. Additionally, it demonstrates promising transfer capabilities and supports substructure-conditioned generation without additional fine-tuning. By extending language modeling techniques to graph generation, this work paves the way for developing graph foundation models.
Towards Fast Graph Generation via Autoregressive Noisy Filtration Modeling
Feb 04, 2025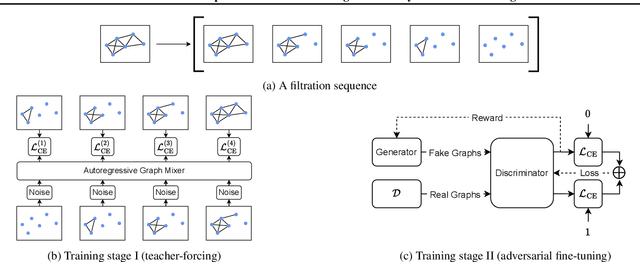


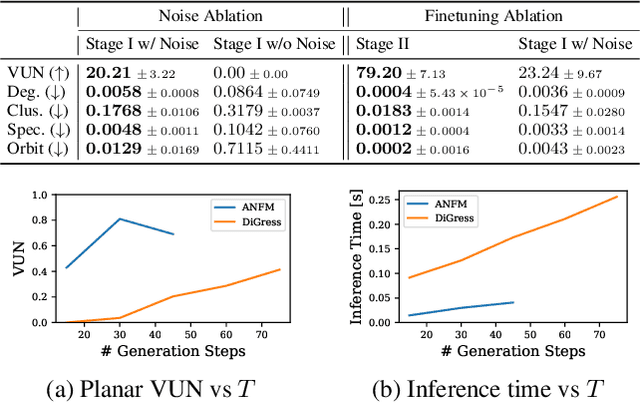
Graph generative models often face a critical trade-off between learning complex distributions and achieving fast generation speed. We introduce Autoregressive Noisy Filtration Modeling (ANFM), a novel approach that addresses both challenges. ANFM leverages filtration, a concept from topological data analysis, to transform graphs into short sequences of monotonically increasing subgraphs. This formulation extends the sequence families used in previous autoregressive models. To learn from these sequences, we propose a novel autoregressive graph mixer model. Our experiments suggest that exposure bias might represent a substantial hurdle in autoregressive graph generation and we introduce two mitigation strategies to address it: noise augmentation and a reinforcement learning approach. Incorporating these techniques leads to substantial performance gains, making ANFM competitive with state-of-the-art diffusion models across diverse synthetic and real-world datasets. Notably, ANFM produces remarkably short sequences, achieving a 100-fold speedup in generation time compared to diffusion models. This work marks a significant step toward high-throughput graph generation.
HTR-VT: Handwritten Text Recognition with Vision Transformer
Sep 13, 2024We explore the application of Vision Transformer (ViT) for handwritten text recognition. The limited availability of labeled data in this domain poses challenges for achieving high performance solely relying on ViT. Previous transformer-based models required external data or extensive pre-training on large datasets to excel. To address this limitation, we introduce a data-efficient ViT method that uses only the encoder of the standard transformer. We find that incorporating a Convolutional Neural Network (CNN) for feature extraction instead of the original patch embedding and employ Sharpness-Aware Minimization (SAM) optimizer to ensure that the model can converge towards flatter minima and yield notable enhancements. Furthermore, our introduction of the span mask technique, which masks interconnected features in the feature map, acts as an effective regularizer. Empirically, our approach competes favorably with traditional CNN-based models on small datasets like IAM and READ2016. Additionally, it establishes a new benchmark on the LAM dataset, currently the largest dataset with 19,830 training text lines. The code is publicly available at: https://github.com/YutingLi0606/HTR-VT.
Learning Long Range Dependencies on Graphs via Random Walks
Jun 05, 2024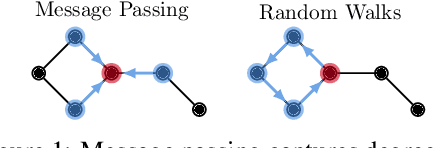
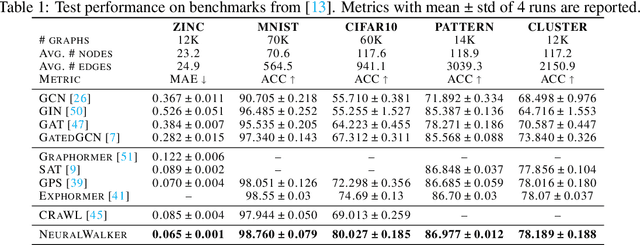
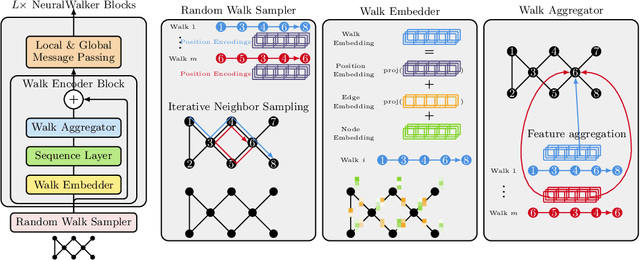
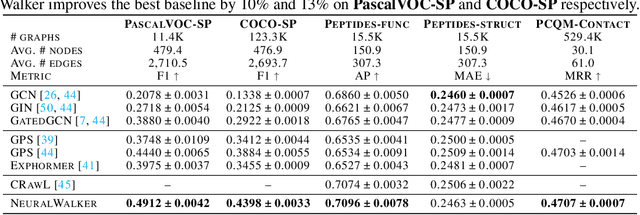
Message-passing graph neural networks (GNNs), while excelling at capturing local relationships, often struggle with long-range dependencies on graphs. Conversely, graph transformers (GTs) enable information exchange between all nodes but oversimplify the graph structure by treating them as a set of fixed-length vectors. This work proposes a novel architecture, NeuralWalker, that overcomes the limitations of both methods by combining random walks with message passing. NeuralWalker achieves this by treating random walks as sequences, allowing for the application of recent advances in sequence models in order to capture long-range dependencies within these walks. Based on this concept, we propose a framework that offers (1) more expressive graph representations through random walk sequences, (2) the ability to utilize any sequence model for capturing long-range dependencies, and (3) the flexibility by integrating various GNN and GT architectures. Our experimental evaluations demonstrate that NeuralWalker achieves significant performance improvements on 19 graph and node benchmark datasets, notably outperforming existing methods by up to 13% on the PascalVoc-SP and COCO-SP datasets. Code is available at https://github.com/BorgwardtLab/NeuralWalker.
SURE: SUrvey REcipes for building reliable and robust deep networks
Mar 01, 2024



In this paper, we revisit techniques for uncertainty estimation within deep neural networks and consolidate a suite of techniques to enhance their reliability. Our investigation reveals that an integrated application of diverse techniques--spanning model regularization, classifier and optimization--substantially improves the accuracy of uncertainty predictions in image classification tasks. The synergistic effect of these techniques culminates in our novel SURE approach. We rigorously evaluate SURE against the benchmark of failure prediction, a critical testbed for uncertainty estimation efficacy. Our results showcase a consistently better performance than models that individually deploy each technique, across various datasets and model architectures. When applied to real-world challenges, such as data corruption, label noise, and long-tailed class distribution, SURE exhibits remarkable robustness, delivering results that are superior or on par with current state-of-the-art specialized methods. Particularly on Animal-10N and Food-101N for learning with noisy labels, SURE achieves state-of-the-art performance without any task-specific adjustments. This work not only sets a new benchmark for robust uncertainty estimation but also paves the way for its application in diverse, real-world scenarios where reliability is paramount. Our code is available at \url{https://yutingli0606.github.io/SURE/}.
Endowing Protein Language Models with Structural Knowledge
Jan 26, 2024Understanding the relationships between protein sequence, structure and function is a long-standing biological challenge with manifold implications from drug design to our understanding of evolution. Recently, protein language models have emerged as the preferred method for this challenge, thanks to their ability to harness large sequence databases. Yet, their reliance on expansive sequence data and parameter sets limits their flexibility and practicality in real-world scenarios. Concurrently, the recent surge in computationally predicted protein structures unlocks new opportunities in protein representation learning. While promising, the computational burden carried by such complex data still hinders widely-adopted practical applications. To address these limitations, we introduce a novel framework that enhances protein language models by integrating protein structural data. Drawing from recent advances in graph transformers, our approach refines the self-attention mechanisms of pretrained language transformers by integrating structural information with structure extractor modules. This refined model, termed Protein Structure Transformer (PST), is further pretrained on a small protein structure database, using the same masked language modeling objective as traditional protein language models. Empirical evaluations of PST demonstrate its superior parameter efficiency relative to protein language models, despite being pretrained on a dataset comprising only 542K structures. Notably, PST consistently outperforms the state-of-the-art foundation model for protein sequences, ESM-2, setting a new benchmark in protein function prediction. Our findings underscore the potential of integrating structural information into protein language models, paving the way for more effective and efficient protein modeling Code and pretrained models are available at https://github.com/BorgwardtLab/PST.
Fisher Information Embedding for Node and Graph Learning
May 12, 2023
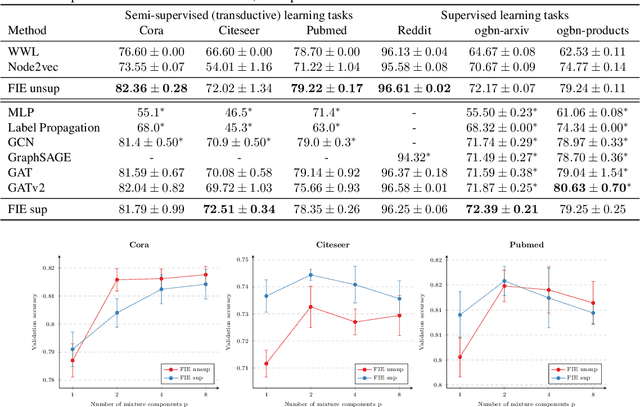
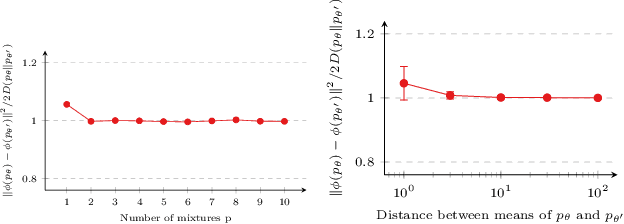
Attention-based graph neural networks (GNNs), such as graph attention networks (GATs), have become popular neural architectures for processing graph-structured data and learning node embeddings. Despite their empirical success, these models rely on labeled data and the theoretical properties of these models have yet to be fully understood. In this work, we propose a novel attention-based node embedding framework for graphs. Our framework builds upon a hierarchical kernel for multisets of subgraphs around nodes (e.g. neighborhoods) and each kernel leverages the geometry of a smooth statistical manifold to compare pairs of multisets, by "projecting" the multisets onto the manifold. By explicitly computing node embeddings with a manifold of Gaussian mixtures, our method leads to a new attention mechanism for neighborhood aggregation. We provide theoretical insights into genralizability and expressivity of our embeddings, contributing to a deeper understanding of attention-based GNNs. We propose efficient unsupervised and supervised methods for learning the embeddings, with the unsupervised method not requiring any labeled data. Through experiments on several node classification benchmarks, we demonstrate that our proposed method outperforms existing attention-based graph models like GATs. Our code is available at https://github.com/BorgwardtLab/fisher_information_embedding.
Unsupervised Manifold Alignment with Joint Multidimensional Scaling
Jul 06, 2022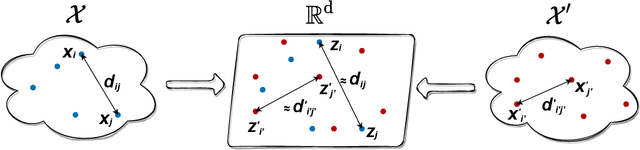
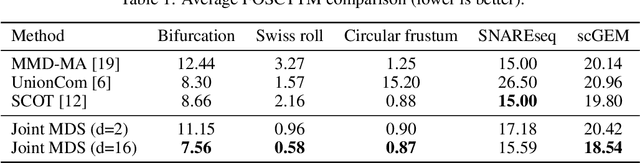
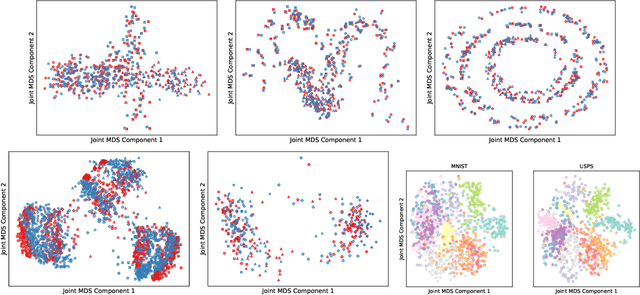

We introduce Joint Multidimensional Scaling, a novel approach for unsupervised manifold alignment, which maps datasets from two different domains, without any known correspondences between data instances across the datasets, to a common low-dimensional Euclidean space. Our approach integrates Multidimensional Scaling (MDS) and Wasserstein Procrustes analysis into a joint optimization problem to simultaneously generate isometric embeddings of data and learn correspondences between instances from two different datasets, while only requiring intra-dataset pairwise dissimilarities as input. This unique characteristic makes our approach applicable to datasets without access to the input features, such as solving the inexact graph matching problem. We propose an alternating optimization scheme to solve the problem that can fully benefit from the optimization techniques for MDS and Wasserstein Procrustes. We demonstrate the effectiveness of our approach in several applications, including joint visualization of two datasets, unsupervised heterogeneous domain adaptation, graph matching, and protein structure alignment.