 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlatten Graphs as Sequences: Transformers are Scalable Graph Generators
Feb 04, 2025

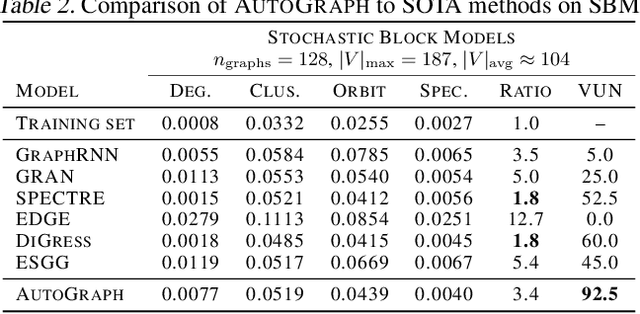

We introduce AutoGraph, a novel autoregressive framework for generating large attributed graphs using decoder-only transformers. At the core of our approach is a reversible "flattening" process that transforms graphs into random sequences. By sampling and learning from these sequences, AutoGraph enables transformers to model and generate complex graph structures in a manner akin to natural language. In contrast to diffusion models that rely on computationally intensive node features, our approach operates exclusively on these sequences. The sampling complexity and sequence length scale linearly with the number of edges, making AutoGraph highly scalable for generating large sparse graphs. Empirically, AutoGraph achieves state-of-the-art performance across diverse synthetic and molecular graph generation benchmarks, while delivering a 100-fold generation and a 3-fold training speedup compared to leading diffusion models. Additionally, it demonstrates promising transfer capabilities and supports substructure-conditioned generation without additional fine-tuning. By extending language modeling techniques to graph generation, this work paves the way for developing graph foundation models.
Towards Fast Graph Generation via Autoregressive Noisy Filtration Modeling
Feb 04, 2025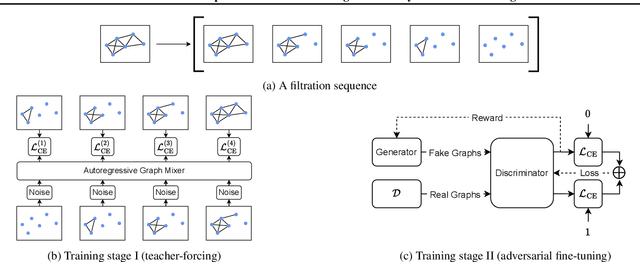


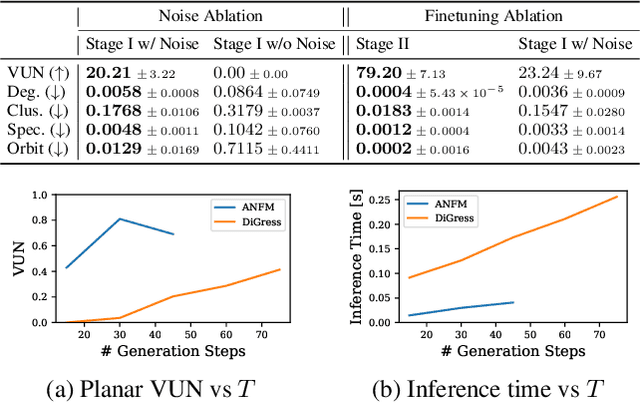
Graph generative models often face a critical trade-off between learning complex distributions and achieving fast generation speed. We introduce Autoregressive Noisy Filtration Modeling (ANFM), a novel approach that addresses both challenges. ANFM leverages filtration, a concept from topological data analysis, to transform graphs into short sequences of monotonically increasing subgraphs. This formulation extends the sequence families used in previous autoregressive models. To learn from these sequences, we propose a novel autoregressive graph mixer model. Our experiments suggest that exposure bias might represent a substantial hurdle in autoregressive graph generation and we introduce two mitigation strategies to address it: noise augmentation and a reinforcement learning approach. Incorporating these techniques leads to substantial performance gains, making ANFM competitive with state-of-the-art diffusion models across diverse synthetic and real-world datasets. Notably, ANFM produces remarkably short sequences, achieving a 100-fold speedup in generation time compared to diffusion models. This work marks a significant step toward high-throughput graph generation.
jina-embeddings-v3: Multilingual Embeddings With Task LoRA
Sep 17, 2024


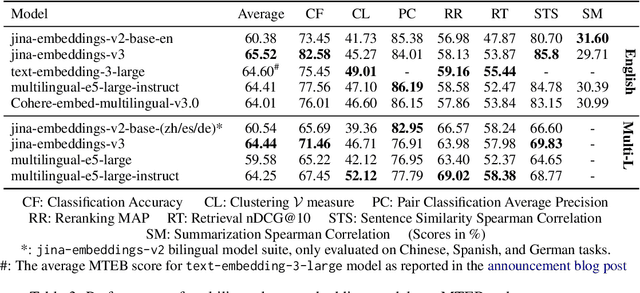
We introduce jina-embeddings-v3, a novel text embedding model with 570 million parameters, achieves state-of-the-art performance on multilingual data and long-context retrieval tasks, supporting context lengths of up to 8192 tokens. The model includes a set of task-specific Low-Rank Adaptation (LoRA) adapters to generate high-quality embeddings for query-document retrieval, clustering, classification, and text matching. Additionally, Matryoshka Representation Learning is integrated into the training process, allowing flexible truncation of embedding dimensions without compromising performance. Evaluation on the MTEB benchmark shows that jina-embeddings-v3 outperforms the latest proprietary embeddings from OpenAI and Cohere on English tasks, while achieving superior performance compared to multilingual-e5-large-instruct across all multilingual tasks.
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Jul 24, 2024Gymnasium is an open-source library providing an API for reinforcement learning environments. Its main contribution is a central abstraction for wide interoperability between benchmark environments and training algorithms. Gymnasium comes with various built-in environments and utilities to simplify researchers' work along with being supported by most training libraries. This paper outlines the main design decisions for Gymnasium, its key features, and the differences to alternative APIs.
Attention Normalization Impacts Cardinality Generalization in Slot Attention
Jul 04, 2024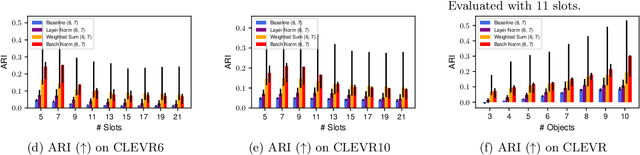
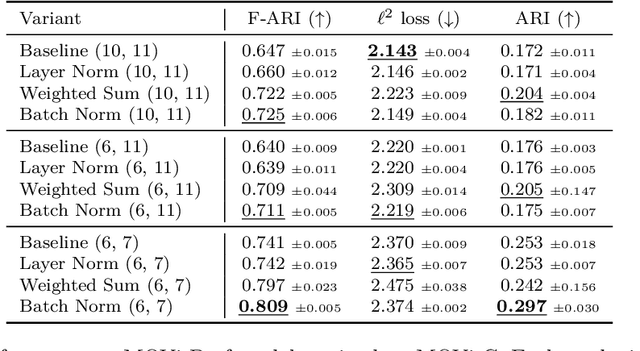
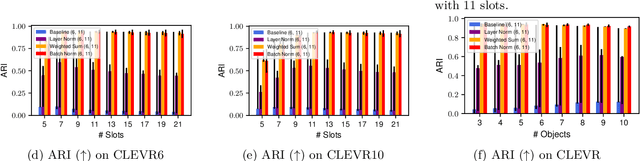
Object-centric scene decompositions are important representations for downstream tasks in fields such as computer vision and robotics. The recently proposed Slot Attention module, already leveraged by several derivative works for image segmentation and object tracking in videos, is a deep learning component which performs unsupervised object-centric scene decomposition on input images. It is based on an attention architecture, in which latent slot vectors, which hold compressed information on objects, attend to localized perceptual features from the input image. In this paper, we show that design decisions on normalizing the aggregated values in the attention architecture have considerable impact on the capabilities of Slot Attention to generalize to a higher number of slots and objects as seen during training. We argue that the original Slot Attention normalization scheme discards information on the prior assignment probability of pixels to slots, which impairs its generalization capabilities. Based on these findings, we propose and investigate alternative normalization approaches which increase the generalization capabilities of Slot Attention to varying slot and object counts, resulting in performance gains on the task of unsupervised image segmentation.
Multi-Task Contrastive Learning for 8192-Token Bilingual Text Embeddings
Feb 26, 2024



We introduce a novel suite of state-of-the-art bilingual text embedding models that are designed to support English and another target language. These models are capable of processing lengthy text inputs with up to 8192 tokens, making them highly versatile for a range of natural language processing tasks such as text retrieval, clustering, and semantic textual similarity (STS) calculations. By focusing on bilingual models and introducing a unique multi-task learning objective, we have significantly improved the model performance on STS tasks, which outperforms the capabilities of existing multilingual models in both target language understanding and cross-lingual evaluation tasks. Moreover, our bilingual models are more efficient, requiring fewer parameters and less memory due to their smaller vocabulary needs. Furthermore, we have expanded the Massive Text Embedding Benchmark (MTEB) to include benchmarks for German and Spanish embedding models. This integration aims to stimulate further research and advancement in text embedding technologies for these languages.
Learning Temporally Extended Skills in Continuous Domains as Symbolic Actions for Planning
Jul 11, 2022
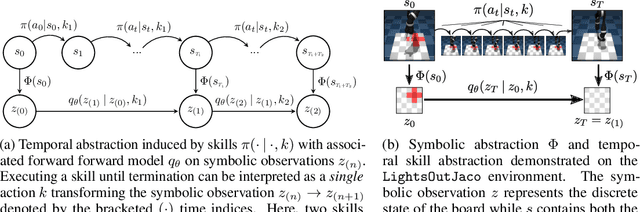
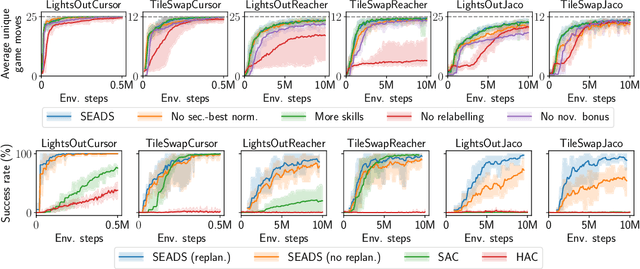
Problems which require both long-horizon planning and continuous control capabilities pose significant challenges to existing reinforcement learning agents. In this paper we introduce a novel hierarchical reinforcement learning agent which links temporally extended skills for continuous control with a forward model in a symbolic discrete abstraction of the environment's state for planning. We term our agent SEADS for Symbolic Effect-Aware Diverse Skills. We formulate an objective and corresponding algorithm which leads to unsupervised learning of a diverse set of skills through intrinsic motivation given a known state abstraction. The skills are jointly learned with the symbolic forward model which captures the effect of skill execution in the state abstraction. After training, we can leverage the skills as symbolic actions using the forward model for long-horizon planning and subsequently execute the plan using the learned continuous-action control skills. The proposed algorithm learns skills and forward models that can be used to solve complex tasks which require both continuous control and long-horizon planning capabilities with high success rate. It compares favorably with other flat and hierarchical reinforcement learning baseline agents and is successfully demonstrated with a real robot.