 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgetorchtune: PyTorch native post-training library
May 20, 2026Modern LLMs typically require multistage training pipelines to achieve strong downstream performance, with post-training serving as the main interface for adapting open-weight models. We introduce torchtune, a PyTorch-native library designed to streamline the post-training lifecycle of LLMs, enabling efficient fine-tuning, experimentation, and deployment-oriented workflows. Unlike many existing fine-tuning frameworks, which often optimize for ease of use, specialized recipes, or hardware efficiency at the cost of transparency and extensibility, torchtune emphasizes modularity, hackability, and direct access to the underlying PyTorch components. In this paper, we present the design principles behind torchtune, describe how they are reflected in its model builders, training recipes, and distributed training stack, and evaluate the library across representative post-training settings. We compare against popular fine-tuning frameworks, including Axolotl and Unsloth, and show that torchtune provides strong performance and memory efficiency across many settings while remaining flexible enough for rapid research iteration. These results position torchtune as a practical foundation for reproducible LLMs post-training research.
Likelihood-Based Reward Designs for General LLM Reasoning
Feb 03, 2026Fine-tuning large language models (LLMs) on reasoning benchmarks via reinforcement learning requires a specific reward function, often binary, for each benchmark. This comes with two potential limitations: the need to design the reward, and the potentially sparse nature of binary rewards. Here, we systematically investigate rewards derived from the probability or log-probability of emitting the reference answer (or any other prompt continuation present in the data), which have the advantage of not relying on specific verifiers and being available at scale. Several recent works have advocated for the use of similar rewards (e.g., VeriFree, JEPO, RLPR, NOVER). We systematically compare variants of likelihood-based rewards with standard baselines, testing performance both on standard mathematical reasoning benchmarks, and on long-form answers where no external verifier is available. We find that using the log-probability of the reference answer as the reward for chain-of-thought (CoT) learning is the only option that performs well in all setups. This reward is also consistent with the next-token log-likelihood loss used during pretraining. In verifiable settings, log-probability rewards bring comparable or better success rates than reinforcing with standard binary rewards, and yield much better perplexity. In non-verifiable settings, they perform on par with SFT. On the other hand, methods based on probability, such as VeriFree, flatline on non-verifiable settings due to vanishing probabilities of getting the correct answer. Overall, this establishes log-probability rewards as a viable method for CoT fine-tuning, bridging the short, verifiable and long, non-verifiable answer settings.
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
Jan 26, 2026Can a model learn to escape its own learning plateau? Reinforcement learning methods for finetuning large reasoning models stall on datasets with low initial success rates, and thus little training signal. We investigate a fundamental question: Can a pretrained LLM leverage latent knowledge to generate an automated curriculum for problems it cannot solve? To explore this, we design SOAR: A self-improvement framework designed to surface these pedagogical signals through meta-RL. A teacher copy of the model proposes synthetic problems for a student copy, and is rewarded with its improvement on a small subset of hard problems. Critically, SOAR grounds the curriculum in measured student progress rather than intrinsic proxy rewards. Our study on the hardest subsets of mathematical benchmarks (0/128 success) reveals three core findings. First, we show that it is possible to realize bi-level meta-RL that unlocks learning under sparse, binary rewards by sharpening a latent capacity of pretrained models to generate useful stepping stones. Second, grounded rewards outperform intrinsic reward schemes used in prior LLM self-play, reliably avoiding the instability and diversity collapse modes they typically exhibit. Third, analyzing the generated questions reveals that structural quality and well-posedness are more critical for learning progress than solution correctness. Our results suggest that the ability to generate useful stepping stones does not require the preexisting ability to actually solve the hard problems, paving a principled path to escape reasoning plateaus without additional curated data.
PILAF: Optimal Human Preference Sampling for Reward Modeling
Feb 06, 2025



As large language models increasingly drive real-world applications, aligning them with human values becomes paramount. Reinforcement Learning from Human Feedback (RLHF) has emerged as a key technique, translating preference data into reward models when oracle human values remain inaccessible. In practice, RLHF mostly relies on approximate reward models, which may not consistently guide the policy toward maximizing the underlying human values. We propose Policy-Interpolated Learning for Aligned Feedback (PILAF), a novel response sampling strategy for preference labeling that explicitly aligns preference learning with maximizing the underlying oracle reward. PILAF is theoretically grounded, demonstrating optimality from both an optimization and a statistical perspective. The method is straightforward to implement and demonstrates strong performance in iterative and online RLHF settings where feedback curation is critical.
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Jul 24, 2024
Gymnasium is an open-source library providing an API for reinforcement learning environments. Its main contribution is a central abstraction for wide interoperability between benchmark environments and training algorithms. Gymnasium comes with various built-in environments and utilities to simplify researchers' work along with being supported by most training libraries. This paper outlines the main design decisions for Gymnasium, its key features, and the differences to alternative APIs.
Reward Function Design for Crowd Simulation via Reinforcement Learning
Sep 22, 2023



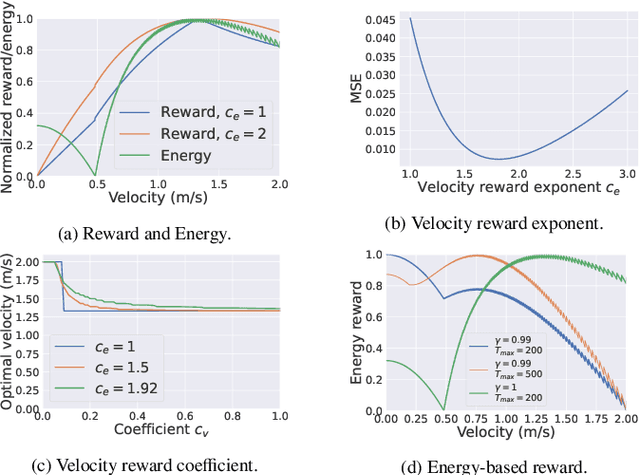
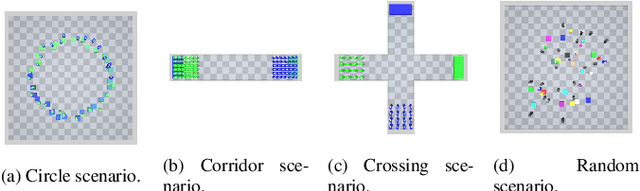
Crowd simulation is important for video-games design, since it enables to populate virtual worlds with autonomous avatars that navigate in a human-like manner. Reinforcement learning has shown great potential in simulating virtual crowds, but the design of the reward function is critical to achieving effective and efficient results. In this work, we explore the design of reward functions for reinforcement learning-based crowd simulation. We provide theoretical insights on the validity of certain reward functions according to their analytical properties, and evaluate them empirically using a range of scenarios, using the energy efficiency as the metric. Our experiments show that directly minimizing the energy usage is a viable strategy as long as it is paired with an appropriately scaled guiding potential, and enable us to study the impact of the different reward components on the behavior of the simulated crowd. Our findings can inform the development of new crowd simulation techniques, and contribute to the wider study of human-like navigation.
UGAE: A Novel Approach to Non-exponential Discounting
Feb 11, 2023



The discounting mechanism in Reinforcement Learning determines the relative importance of future and present rewards. While exponential discounting is widely used in practice, non-exponential discounting methods that align with human behavior are often desirable for creating human-like agents. However, non-exponential discounting methods cannot be directly applied in modern on-policy actor-critic algorithms. To address this issue, we propose Universal Generalized Advantage Estimation (UGAE), which allows for the computation of GAE advantage values with arbitrary discounting. Additionally, we introduce Beta-weighted discounting, a continuous interpolation between exponential and hyperbolic discounting, to increase flexibility in choosing a discounting method. To showcase the utility of UGAE, we provide an analysis of the properties of various discounting methods. We also show experimentally that agents with non-exponential discounting trained via UGAE outperform variants trained with Monte Carlo advantage estimation. Through analysis of various discounting methods and experiments, we demonstrate the superior performance of UGAE with Beta-weighted discounting over the Monte Carlo baseline on standard RL benchmarks. UGAE is simple and easily integrated into any advantage-based algorithm as a replacement for the standard recursive GAE.
Understanding reinforcement learned crowds
Sep 19, 2022
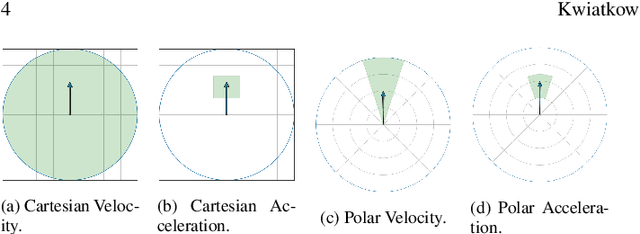
Simulating trajectories of virtual crowds is a commonly encountered task in Computer Graphics. Several recent works have applied Reinforcement Learning methods to animate virtual agents, however they often make different design choices when it comes to the fundamental simulation setup. Each of these choices comes with a reasonable justification for its use, so it is not obvious what is their real impact, and how they affect the results. In this work, we analyze some of these arbitrary choices in terms of their impact on the learning performance, as well as the quality of the resulting simulation measured in terms of the energy efficiency. We perform a theoretical analysis of the properties of the reward function design, and empirically evaluate the impact of using certain observation and action spaces on a variety of scenarios, with the reward function and energy usage as metrics. We show that directly using the neighboring agents' information as observation generally outperforms the more widely used raycasting. Similarly, using nonholonomic controls with egocentric observations tends to produce more efficient behaviors than holonomic controls with absolute observations. Each of these choices has a significant, and potentially nontrivial impact on the results, and so researchers should be mindful about choosing and reporting them in their work.
A Survey on Reinforcement Learning Methods in Character Animation
Mar 07, 2022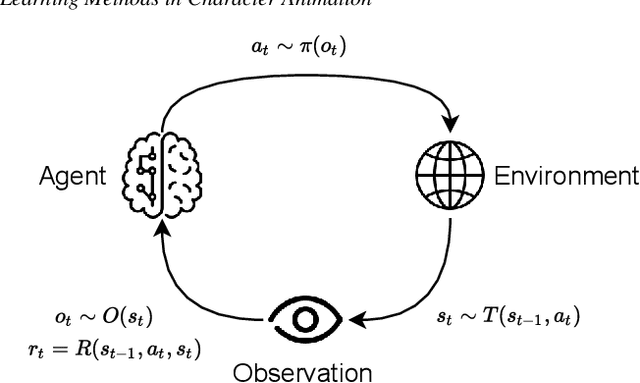
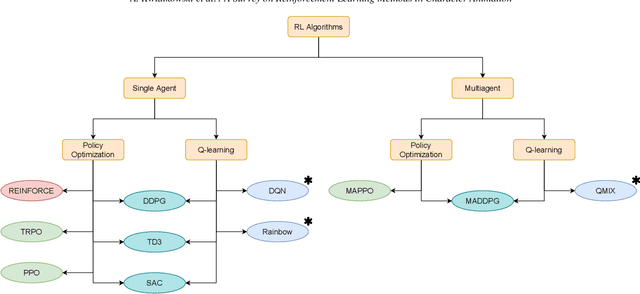
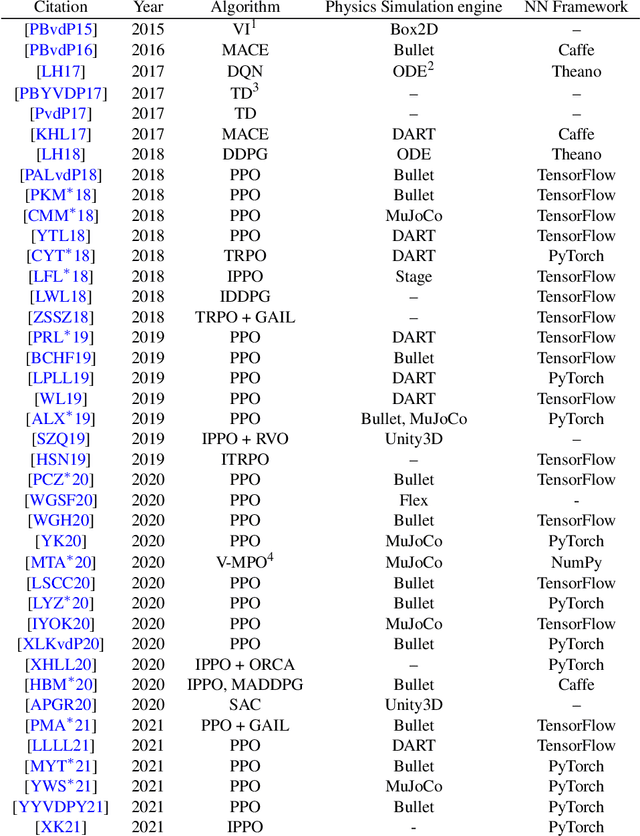
Reinforcement Learning is an area of Machine Learning focused on how agents can be trained to make sequential decisions, and achieve a particular goal within an arbitrary environment. While learning, they repeatedly take actions based on their observation of the environment, and receive appropriate rewards which define the objective. This experience is then used to progressively improve the policy controlling the agent's behavior, typically represented by a neural network. This trained module can then be reused for similar problems, which makes this approach promising for the animation of autonomous, yet reactive characters in simulators, video games or virtual reality environments. This paper surveys the modern Deep Reinforcement Learning methods and discusses their possible applications in Character Animation, from skeletal control of a single, physically-based character to navigation controllers for individual agents and virtual crowds. It also describes the practical side of training DRL systems, comparing the different frameworks available to build such agents.
Behaviour-conditioned policies for cooperative reinforcement learning tasks
Oct 04, 2021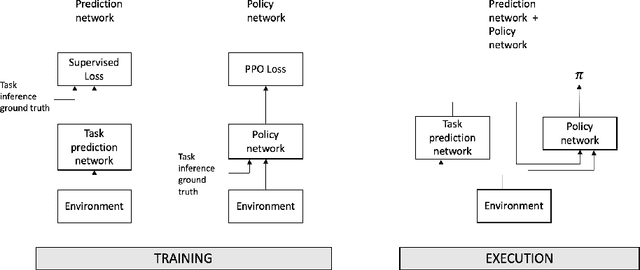

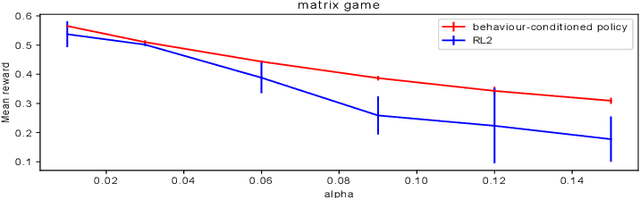
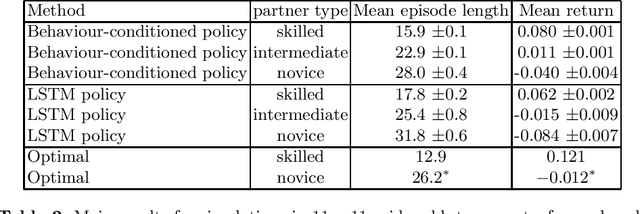
The cooperation among AI systems, and between AI systems and humans is becoming increasingly important. In various real-world tasks, an agent needs to cooperate with unknown partner agent types. This requires the agent to assess the behaviour of the partner agent during a cooperative task and to adjust its own policy to support the cooperation. Deep reinforcement learning models can be trained to deliver the required functionality but are known to suffer from sample inefficiency and slow learning. However, adapting to a partner agent behaviour during the ongoing task requires ability to assess the partner agent type quickly. We suggest a method, where we synthetically produce populations of agents with different behavioural patterns together with ground truth data of their behaviour, and use this data for training a meta-learner. We additionally suggest an agent architecture, which can efficiently use the generated data and gain the meta-learning capability. When an agent is equipped with such a meta-learner, it is capable of quickly adapting to cooperation with unknown partner agent types in new situations. This method can be used to automatically form a task distribution for meta-training from emerging behaviours that arise, for example, through self-play.