 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEdit Knowledge, Not Just Facts via Multi-Step Reasoning over Background Stories
Feb 02, 2026Enabling artificial intelligence systems, particularly large language models, to integrate new knowledge and flexibly apply it during reasoning remains a central challenge. Existing knowledge editing approaches emphasize atomic facts, improving factual recall but often failing to integrate new information into a coherent framework usable across contexts. In this work, we argue that knowledge internalization is fundamentally a reasoning problem rather than a memorization problem. Consequently, a model should be trained in situations where the new information is instrumental to solving a task, combined with pre-existing knowledge, and exercised through multi-step reasoning. Based on this insight, we propose a training strategy based on three principles. First, new knowledge is introduced as a coherent background story that contextualizes novel facts and explains their relation to existing knowledge. Second, models are trained using self-generated multi-hop questions that require multi-step reasoning involving the new information. Third, training is done using knowledge distillation, forcing a student model to internalize the teacher's reasoning behavior without access to the novel information. Experiments show that models trained with this strategy effectively leverage newly acquired knowledge during reasoning and achieve remarkable performance on challenging questions that require combining multiple new facts.
Memento No More: Coaching AI Agents to Master Multiple Tasks via Hints Internalization
Feb 03, 2025As the general capabilities of artificial intelligence (AI) agents continue to evolve, their ability to learn to master multiple complex tasks through experience remains a key challenge. Current LLM agents, particularly those based on proprietary language models, typically rely on prompts to incorporate knowledge about the target tasks. This approach does not allow the agent to internalize this information and instead relies on ever-expanding prompts to sustain its functionality in diverse scenarios. This resembles a system of notes used by a person affected by anterograde amnesia, the inability to form new memories. In this paper, we propose a novel method to train AI agents to incorporate knowledge and skills for multiple tasks without the need for either cumbersome note systems or prior high-quality demonstration data. Our approach employs an iterative process where the agent collects new experiences, receives corrective feedback from humans in the form of hints, and integrates this feedback into its weights via a context distillation training procedure. We demonstrate the efficacy of our approach by implementing it in a Llama-3-based agent which, after only a few rounds of feedback, outperforms advanced models GPT-4o and DeepSeek-V3 in a taskset requiring correct sequencing of information retrieval, tool use, and question answering.
Knowledge Injection via Prompt Distillation
Dec 19, 2024


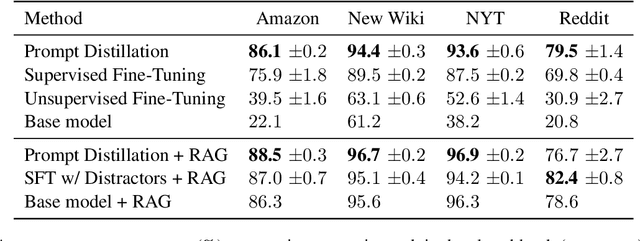
In many practical applications, large language models (LLMs) need to incorporate new knowledge not present in their pre-training data. The primary methods for this are fine-tuning and retrieval-augmented generation (RAG). Although RAG has emerged as the industry standard for knowledge injection, fine-tuning has not yet achieved comparable success. In this paper, we propose a new fine-tuning technique for learning new knowledge and show that it can reach the performance of RAG. The proposed method is based on the self-distillation approach, which we call prompt distillation. First, we generate question-answer pairs about the new knowledge. Then, we fine-tune a student model on the question-answer pairs to imitate the output distributions of a teacher model, which additionally receives the new knowledge in its prompt. The student model is identical to the teacher, except it is equipped with a LoRA adapter. This training procedure facilitates distilling the new knowledge from the teacher's prompt into the student's weights.
Diffusion models as probabilistic neural operators for recovering unobserved states of dynamical systems
May 11, 2024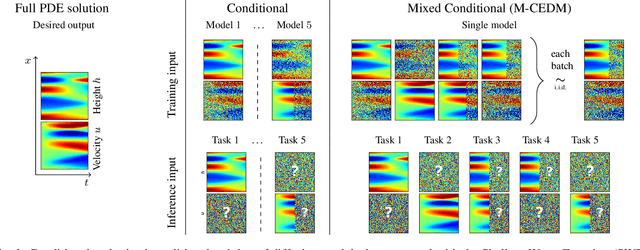
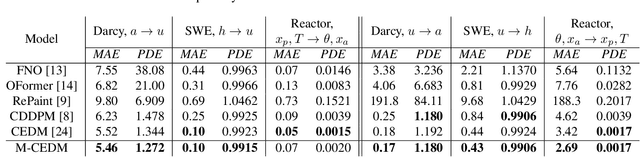
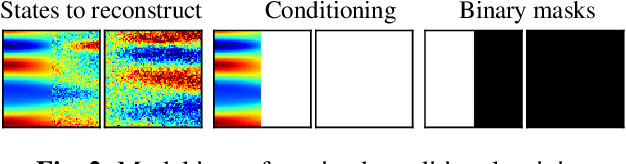
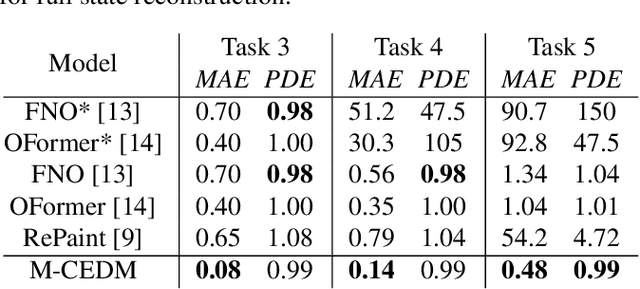
This paper explores the efficacy of diffusion-based generative models as neural operators for partial differential equations (PDEs). Neural operators are neural networks that learn a mapping from the parameter space to the solution space of PDEs from data, and they can also solve the inverse problem of estimating the parameter from the solution. Diffusion models excel in many domains, but their potential as neural operators has not been thoroughly explored. In this work, we show that diffusion-based generative models exhibit many properties favourable for neural operators, and they can effectively generate the solution of a PDE conditionally on the parameter or recover the unobserved parts of the system. We propose to train a single model adaptable to multiple tasks, by alternating between the tasks during training. In our experiments with multiple realistic dynamical systems, diffusion models outperform other neural operators. Furthermore, we demonstrate how the probabilistic diffusion model can elegantly deal with systems which are only partially identifiable, by producing samples corresponding to the different possible solutions.
ViewFusion: Learning Composable Diffusion Models for Novel View Synthesis
Feb 05, 2024



Deep learning is providing a wealth of new approaches to the old problem of novel view synthesis, from Neural Radiance Field (NeRF) based approaches to end-to-end style architectures. Each approach offers specific strengths but also comes with specific limitations in their applicability. This work introduces ViewFusion, a state-of-the-art end-to-end generative approach to novel view synthesis with unparalleled flexibility. ViewFusion consists in simultaneously applying a diffusion denoising step to any number of input views of a scene, then combining the noise gradients obtained for each view with an (inferred) pixel-weighting mask, ensuring that for each region of the target scene only the most informative input views are taken into account. Our approach resolves several limitations of previous approaches by (1) being trainable and generalizing across multiple scenes and object classes, (2) adaptively taking in a variable number of pose-free views at both train and test time, (3) generating plausible views even in severely undetermined conditions (thanks to its generative nature) -- all while generating views of quality on par or even better than state-of-the-art methods. Limitations include not generating a 3D embedding of the scene, resulting in a relatively slow inference speed, and our method only being tested on the relatively small dataset NMR. Code is available.
Hybrid Search for Efficient Planning with Completeness Guarantees
Oct 19, 2023



Solving complex planning problems has been a long-standing challenge in computer science. Learning-based subgoal search methods have shown promise in tackling these problems, but they often suffer from a lack of completeness guarantees, meaning that they may fail to find a solution even if one exists. In this paper, we propose an efficient approach to augment a subgoal search method to achieve completeness in discrete action spaces. Specifically, we augment the high-level search with low-level actions to execute a multi-level (hybrid) search, which we call complete subgoal search. This solution achieves the best of both worlds: the practical efficiency of high-level search and the completeness of low-level search. We apply the proposed search method to a recently proposed subgoal search algorithm and evaluate the algorithm trained on offline data on complex planning problems. We demonstrate that our complete subgoal search not only guarantees completeness but can even improve performance in terms of search expansions for instances that the high-level could solve without low-level augmentations. Our approach makes it possible to apply subgoal-level planning for systems where completeness is a critical requirement.
Suicidal Pedestrian: Generation of Safety-Critical Scenarios for Autonomous Vehicles
Sep 01, 2023



Developing reliable autonomous driving algorithms poses challenges in testing, particularly when it comes to safety-critical traffic scenarios involving pedestrians. An open question is how to simulate rare events, not necessarily found in autonomous driving datasets or scripted simulations, but which can occur in testing, and, in the end may lead to severe pedestrian related accidents. This paper presents a method for designing a suicidal pedestrian agent within the CARLA simulator, enabling the automatic generation of traffic scenarios for testing safety of autonomous vehicles (AVs) in dangerous situations with pedestrians. The pedestrian is modeled as a reinforcement learning (RL) agent with two custom reward functions that allow the agent to either arbitrarily or with high velocity to collide with the AV. Instead of significantly constraining the initial locations and the pedestrian behavior, we allow the pedestrian and autonomous car to be placed anywhere in the environment and the pedestrian to roam freely to generate diverse scenarios. To assess the performance of the suicidal pedestrian and the target vehicle during testing, we propose three collision-oriented evaluation metrics. Experimental results involving two state-of-the-art autonomous driving algorithms trained end-to-end with imitation learning from sensor data demonstrate the effectiveness of the suicidal pedestrian in identifying decision errors made by autonomous vehicles controlled by the algorithms.
Improved Compositional Generalization by Generating Demonstrations for Meta-Learning
May 22, 2023

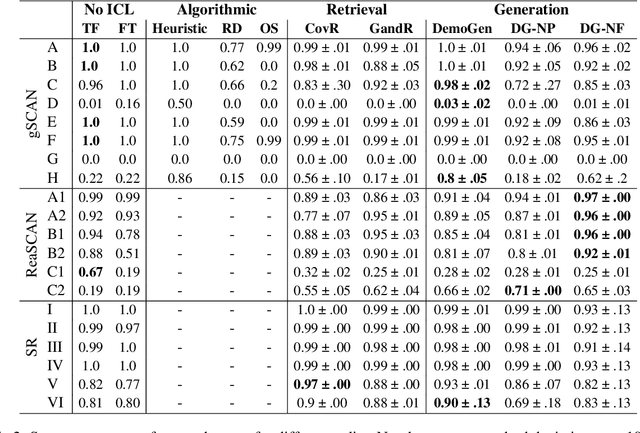
Meta-learning and few-shot prompting are viable methods to induce certain types of compositional behaviour. However, these methods can be very sensitive to the choice of support examples used. Choosing good supports from the training data for a given test query is already a difficult problem, but in some cases solving this may not even be enough. We consider a grounded language learning problem (gSCAN) where good support examples for certain test splits might not even exist in the training data, or would be infeasible to search for. We design an agent which instead generates possible supports which are relevant to the test query and current state of the world, then uses these supports via meta-learning to solve the test query. We show substantially improved performance on a previously unsolved compositional behaviour split without a loss of performance on other splits. Further experiments show that in this case, searching for relevant demonstrations even with an oracle function is not sufficient to attain good performance when using meta-learning.
Hierarchical Imitation Learning with Vector Quantized Models
Jan 30, 2023



The ability to plan actions on multiple levels of abstraction enables intelligent agents to solve complex tasks effectively. However, learning the models for both low and high-level planning from demonstrations has proven challenging, especially with higher-dimensional inputs. To address this issue, we propose to use reinforcement learning to identify subgoals in expert trajectories by associating the magnitude of the rewards with the predictability of low-level actions given the state and the chosen subgoal. We build a vector-quantized generative model for the identified subgoals to perform subgoal-level planning. In experiments, the algorithm excels at solving complex, long-horizon decision-making problems outperforming state-of-the-art. Because of its ability to plan, our algorithm can find better trajectories than the ones in the training set
Adaptive Behavior Cloning Regularization for Stable Offline-to-Online Reinforcement Learning
Oct 25, 2022Offline reinforcement learning, by learning from a fixed dataset, makes it possible to learn agent behaviors without interacting with the environment. However, depending on the quality of the offline dataset, such pre-trained agents may have limited performance and would further need to be fine-tuned online by interacting with the environment. During online fine-tuning, the performance of the pre-trained agent may collapse quickly due to the sudden distribution shift from offline to online data. While constraints enforced by offline RL methods such as a behaviour cloning loss prevent this to an extent, these constraints also significantly slow down online fine-tuning by forcing the agent to stay close to the behavior policy. We propose to adaptively weigh the behavior cloning loss during online fine-tuning based on the agent's performance and training stability. Moreover, we use a randomized ensemble of Q functions to further increase the sample efficiency of online fine-tuning by performing a large number of learning updates. Experiments show that the proposed method yields state-of-the-art offline-to-online reinforcement learning performance on the popular D4RL benchmark. Code is available: \url{https://github.com/zhaoyi11/adaptive_bc}.