 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture of Raytraced Experts
Jul 16, 2025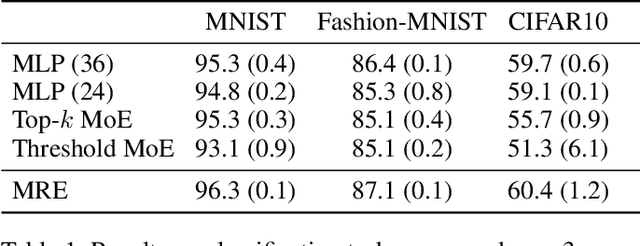
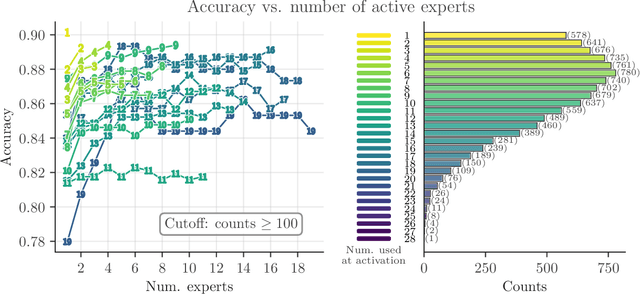
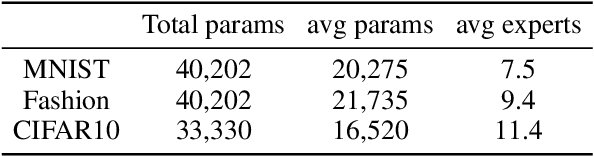
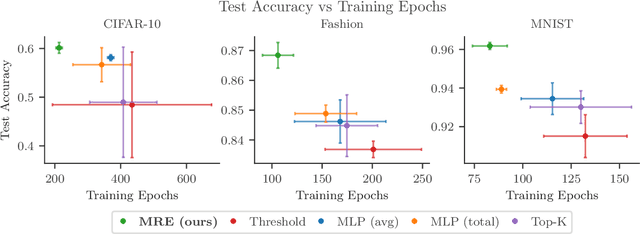
We introduce a Mixture of Raytraced Experts, a stacked Mixture of Experts (MoE) architecture which can dynamically select sequences of experts, producing computational graphs of variable width and depth. Existing MoE architectures generally require a fixed amount of computation for a given sample. Our approach, in contrast, yields predictions with increasing accuracy as the computation cycles through the experts' sequence. We train our model by iteratively sampling from a set of candidate experts, unfolding the sequence akin to how Recurrent Neural Networks are trained. Our method does not require load-balancing mechanisms, and preliminary experiments show a reduction in training epochs of 10\% to 40\% with a comparable/higher accuracy. These results point to new research directions in the field of MoEs, allowing the design of potentially faster and more expressive models. The code is available at https://github.com/nutig/RayTracing
On the Ability of Deep Networks to Learn Symmetries from Data: A Neural Kernel Theory
Dec 16, 2024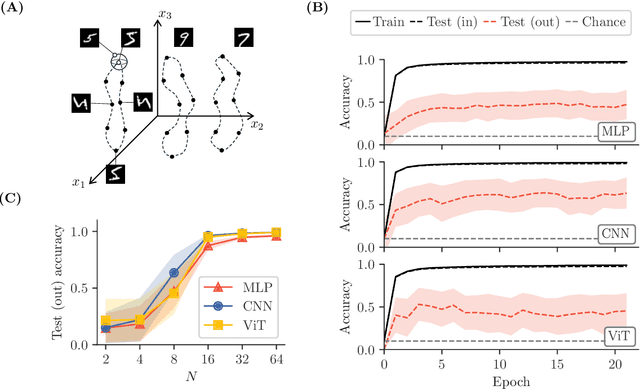
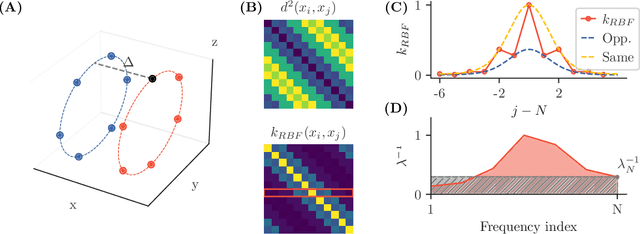
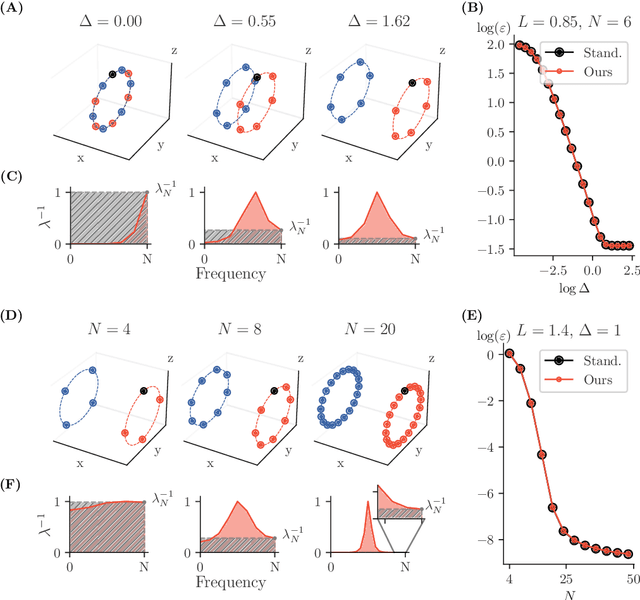
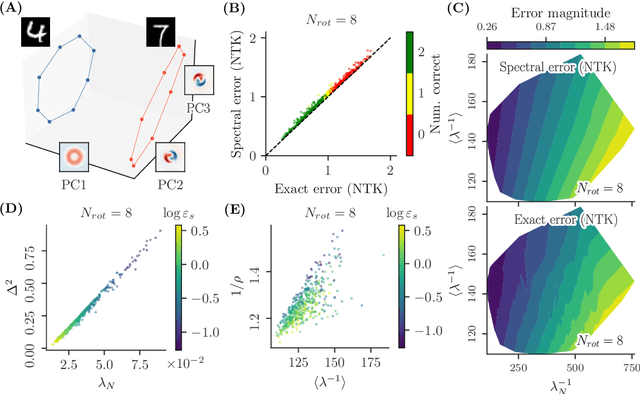
Symmetries (transformations by group actions) are present in many datasets, and leveraging them holds significant promise for improving predictions in machine learning. In this work, we aim to understand when and how deep networks can learn symmetries from data. We focus on a supervised classification paradigm where data symmetries are only partially observed during training: some classes include all transformations of a cyclic group, while others include only a subset. We ask: can deep networks generalize symmetry invariance to the partially sampled classes? In the infinite-width limit, where kernel analogies apply, we derive a neural kernel theory of symmetry learning to address this question. The group-cyclic nature of the dataset allows us to analyze the spectrum of neural kernels in the Fourier domain; here we find a simple characterization of the generalization error as a function of the interaction between class separation (signal) and class-orbit density (noise). We observe that generalization can only be successful when the local structure of the data prevails over its non-local, symmetric, structure, in the kernel space defined by the architecture. This occurs when (1) classes are sufficiently distinct and (2) class orbits are sufficiently dense. Our framework also applies to equivariant architectures (e.g., CNNs), and recovers their success in the special case where the architecture matches the inherent symmetry of the data. Empirically, our theory reproduces the generalization failure of finite-width networks (MLP, CNN, ViT) trained on partially observed versions of rotated-MNIST. We conclude that conventional networks trained with supervision lack a mechanism to learn symmetries that have not been explicitly embedded in their architecture a priori. Our framework could be extended to guide the design of architectures and training procedures able to learn symmetries from data.
Humans Beat Deep Networks at Recognizing Objects in Unusual Poses, Given Enough Time
Feb 06, 2024Deep learning is closing the gap with humans on several object recognition benchmarks. Here we investigate this gap in the context of challenging images where objects are seen from unusual viewpoints. We find that humans excel at recognizing objects in unusual poses, in contrast with state-of-the-art pretrained networks (EfficientNet, SWAG, ViT, SWIN, BEiT, ConvNext) which are systematically brittle in this condition. Remarkably, as we limit image exposure time, human performance degrades to the level of deep networks, suggesting that additional mental processes (requiring additional time) take place when humans identify objects in unusual poses. Finally, our analysis of error patterns of humans vs. networks reveals that even time-limited humans are dissimilar to feed-forward deep networks. We conclude that more work is needed to bring computer vision systems to the level of robustness of the human visual system. Understanding the nature of the mental processes taking place during extra viewing time may be key to attain such robustness.
ViewFusion: Learning Composable Diffusion Models for Novel View Synthesis
Feb 05, 2024



Deep learning is providing a wealth of new approaches to the old problem of novel view synthesis, from Neural Radiance Field (NeRF) based approaches to end-to-end style architectures. Each approach offers specific strengths but also comes with specific limitations in their applicability. This work introduces ViewFusion, a state-of-the-art end-to-end generative approach to novel view synthesis with unparalleled flexibility. ViewFusion consists in simultaneously applying a diffusion denoising step to any number of input views of a scene, then combining the noise gradients obtained for each view with an (inferred) pixel-weighting mask, ensuring that for each region of the target scene only the most informative input views are taken into account. Our approach resolves several limitations of previous approaches by (1) being trainable and generalizing across multiple scenes and object classes, (2) adaptively taking in a variable number of pose-free views at both train and test time, (3) generating plausible views even in severely undetermined conditions (thanks to its generative nature) -- all while generating views of quality on par or even better than state-of-the-art methods. Limitations include not generating a 3D embedding of the scene, resulting in a relatively slow inference speed, and our method only being tested on the relatively small dataset NMR. Code is available.