 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewFusion: Learning Composable Diffusion Models for Novel View Synthesis
Feb 05, 2024



Deep learning is providing a wealth of new approaches to the old problem of novel view synthesis, from Neural Radiance Field (NeRF) based approaches to end-to-end style architectures. Each approach offers specific strengths but also comes with specific limitations in their applicability. This work introduces ViewFusion, a state-of-the-art end-to-end generative approach to novel view synthesis with unparalleled flexibility. ViewFusion consists in simultaneously applying a diffusion denoising step to any number of input views of a scene, then combining the noise gradients obtained for each view with an (inferred) pixel-weighting mask, ensuring that for each region of the target scene only the most informative input views are taken into account. Our approach resolves several limitations of previous approaches by (1) being trainable and generalizing across multiple scenes and object classes, (2) adaptively taking in a variable number of pose-free views at both train and test time, (3) generating plausible views even in severely undetermined conditions (thanks to its generative nature) -- all while generating views of quality on par or even better than state-of-the-art methods. Limitations include not generating a 3D embedding of the scene, resulting in a relatively slow inference speed, and our method only being tested on the relatively small dataset NMR. Code is available.
Contrastive Unpaired Translation using Focal Loss for Patch Classification
Sep 25, 2021
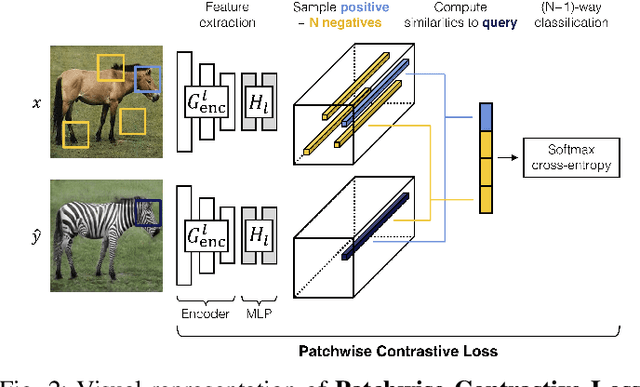
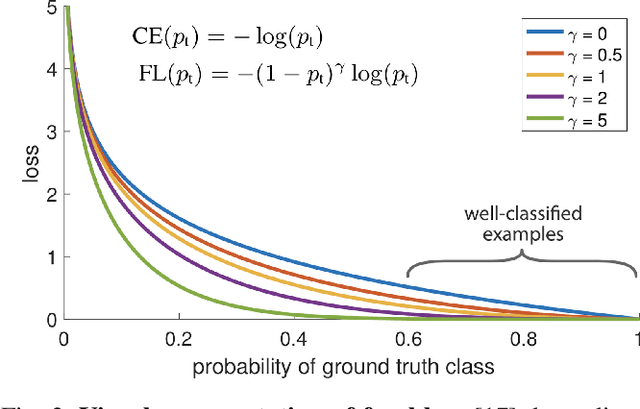
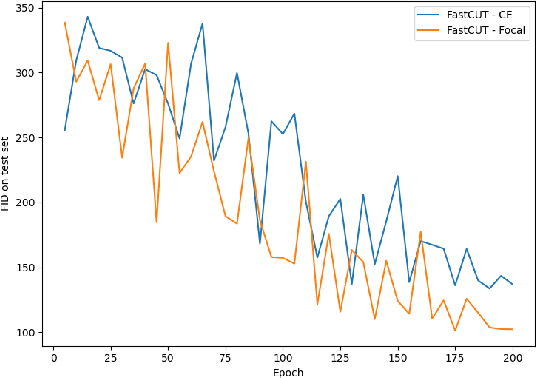
Image-to-image translation models transfer images from input domain to output domain in an endeavor to retain the original content of the image. Contrastive Unpaired Translation is one of the existing methods for solving such problems. Significant advantage of this method, compared to competitors, is the ability to train and perform well in cases where both input and output domains are only a single image. Another key thing that differentiates this method from its predecessors is the usage of image patches rather than the whole images. It also turns out that sampling negatives (patches required to calculate the loss) from the same image achieves better results than a scenario where the negatives are sampled from other images in the dataset. This type of approach encourages mapping of corresponding patches to the same location in relation to other patches (negatives) while at the same time improves the output image quality and significantly decreases memory usage as well as the time required to train the model compared to CycleGAN method used as a baseline. Through a series of experiments we show that using focal loss in place of cross-entropy loss within the PatchNCE loss can improve on the model's performance and even surpass the current state-of-the-art model for image-to-image translation.