 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumans Beat Deep Networks at Recognizing Objects in Unusual Poses, Given Enough Time
Feb 06, 2024Deep learning is closing the gap with humans on several object recognition benchmarks. Here we investigate this gap in the context of challenging images where objects are seen from unusual viewpoints. We find that humans excel at recognizing objects in unusual poses, in contrast with state-of-the-art pretrained networks (EfficientNet, SWAG, ViT, SWIN, BEiT, ConvNext) which are systematically brittle in this condition. Remarkably, as we limit image exposure time, human performance degrades to the level of deep networks, suggesting that additional mental processes (requiring additional time) take place when humans identify objects in unusual poses. Finally, our analysis of error patterns of humans vs. networks reveals that even time-limited humans are dissimilar to feed-forward deep networks. We conclude that more work is needed to bring computer vision systems to the level of robustness of the human visual system. Understanding the nature of the mental processes taking place during extra viewing time may be key to attain such robustness.
ViewFusion: Learning Composable Diffusion Models for Novel View Synthesis
Feb 05, 2024



Deep learning is providing a wealth of new approaches to the old problem of novel view synthesis, from Neural Radiance Field (NeRF) based approaches to end-to-end style architectures. Each approach offers specific strengths but also comes with specific limitations in their applicability. This work introduces ViewFusion, a state-of-the-art end-to-end generative approach to novel view synthesis with unparalleled flexibility. ViewFusion consists in simultaneously applying a diffusion denoising step to any number of input views of a scene, then combining the noise gradients obtained for each view with an (inferred) pixel-weighting mask, ensuring that for each region of the target scene only the most informative input views are taken into account. Our approach resolves several limitations of previous approaches by (1) being trainable and generalizing across multiple scenes and object classes, (2) adaptively taking in a variable number of pose-free views at both train and test time, (3) generating plausible views even in severely undetermined conditions (thanks to its generative nature) -- all while generating views of quality on par or even better than state-of-the-art methods. Limitations include not generating a 3D embedding of the scene, resulting in a relatively slow inference speed, and our method only being tested on the relatively small dataset NMR. Code is available.
On the special role of class-selective neurons in early training
May 27, 2023It is commonly observed that deep networks trained for classification exhibit class-selective neurons in their early and intermediate layers. Intriguingly, recent studies have shown that these class-selective neurons can be ablated without deteriorating network function. But if class-selective neurons are not necessary, why do they exist? We attempt to answer this question in a series of experiments on ResNet-50s trained on ImageNet. We first show that class-selective neurons emerge during the first few epochs of training, before receding rapidly but not completely; this suggests that class-selective neurons found in trained networks are in fact vestigial remains of early training. With single-neuron ablation experiments, we then show that class-selective neurons are important for network function in this early phase of training. We also observe that the network is close to a linear regime in this early phase; we thus speculate that class-selective neurons appear early in training as quasi-linear shortcut solutions to the classification task. Finally, in causal experiments where we regularize against class selectivity at different points in training, we show that the presence of class-selective neurons early in training is critical to the successful training of the network; in contrast, class-selective neurons can be suppressed later in training with little effect on final accuracy. It remains to be understood by which mechanism the presence of class-selective neurons in the early phase of training contributes to the successful training of networks.
Blockwise Self-Supervised Learning at Scale
Feb 03, 2023Current state-of-the-art deep networks are all powered by backpropagation. In this paper, we explore alternatives to full backpropagation in the form of blockwise learning rules, leveraging the latest developments in self-supervised learning. We show that a blockwise pretraining procedure consisting of training independently the 4 main blocks of layers of a ResNet-50 with Barlow Twins' loss function at each block performs almost as well as end-to-end backpropagation on ImageNet: a linear probe trained on top of our blockwise pretrained model obtains a top-1 classification accuracy of 70.48%, only 1.1% below the accuracy of an end-to-end pretrained network (71.57% accuracy). We perform extensive experiments to understand the impact of different components within our method and explore a variety of adaptations of self-supervised learning to the blockwise paradigm, building an exhaustive understanding of the critical avenues for scaling local learning rules to large networks, with implications ranging from hardware design to neuroscience.
Progress and limitations of deep networks to recognize objects in unusual poses
Jul 16, 2022
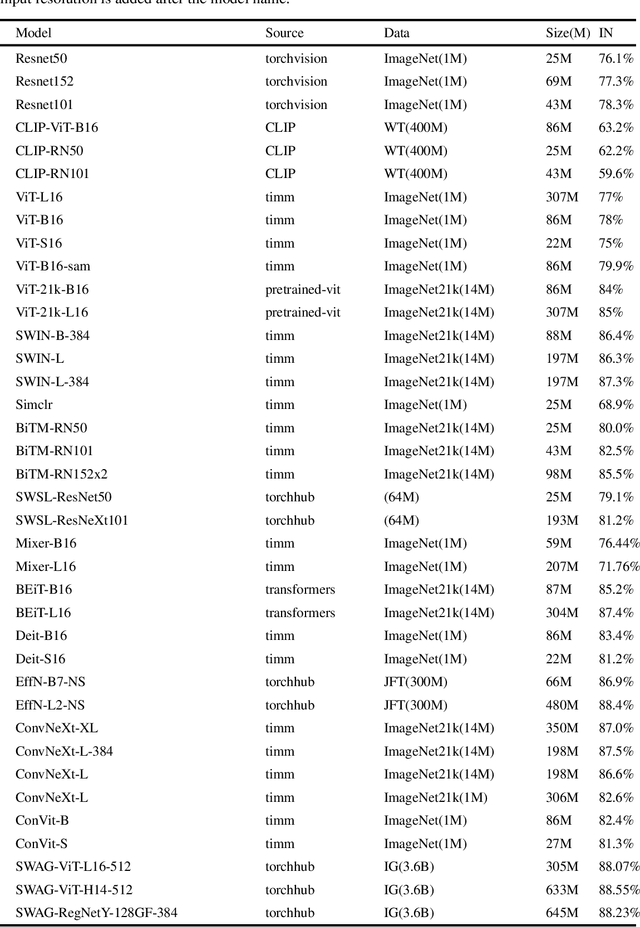


Deep networks should be robust to rare events if they are to be successfully deployed in high-stakes real-world applications (e.g., self-driving cars). Here we study the capability of deep networks to recognize objects in unusual poses. We create a synthetic dataset of images of objects in unusual orientations, and evaluate the robustness of a collection of 38 recent and competitive deep networks for image classification. We show that classifying these images is still a challenge for all networks tested, with an average accuracy drop of 29.5% compared to when the objects are presented upright. This brittleness is largely unaffected by various network design choices, such as training losses (e.g., supervised vs. self-supervised), architectures (e.g., convolutional networks vs. transformers), dataset modalities (e.g., images vs. image-text pairs), and data-augmentation schemes. However, networks trained on very large datasets substantially outperform others, with the best network tested$\unicode{x2014}$Noisy Student EfficentNet-L2 trained on JFT-300M$\unicode{x2014}$showing a relatively small accuracy drop of only 14.5% on unusual poses. Nevertheless, a visual inspection of the failures of Noisy Student reveals a remaining gap in robustness with the human visual system. Furthermore, combining multiple object transformations$\unicode{x2014}$3D-rotations and scaling$\unicode{x2014}$further degrades the performance of all networks. Altogether, our results provide another measurement of the robustness of deep networks that is important to consider when using them in the real world. Code and datasets are available at https://github.com/amro-kamal/ObjectPose.
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Mar 04, 2021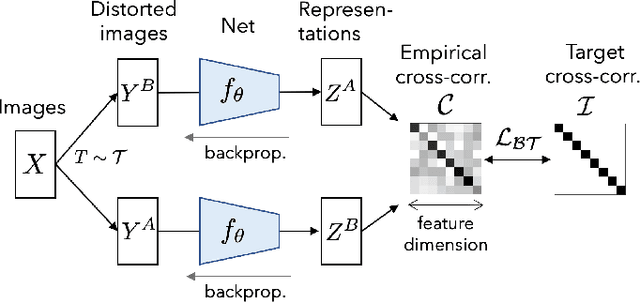
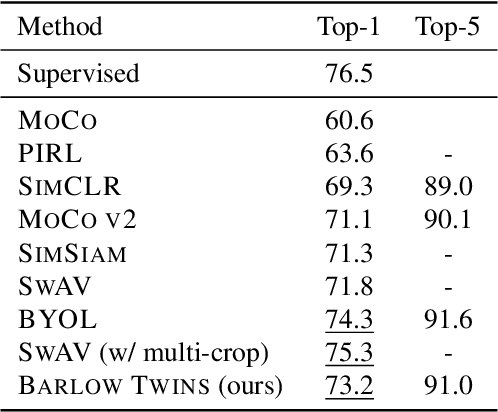
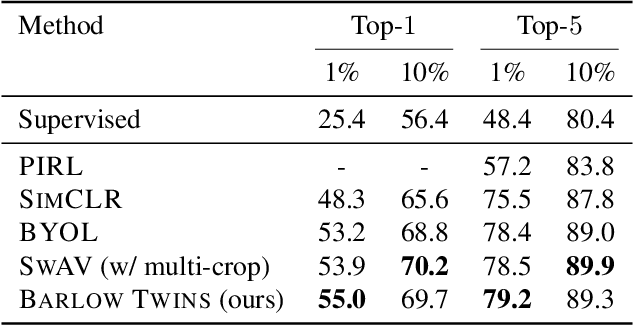
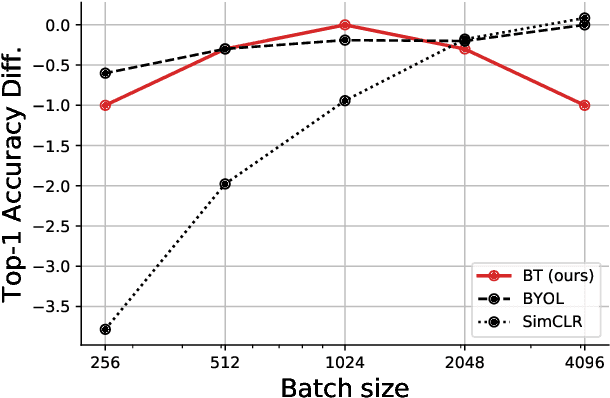
Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn representations which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant representations. Most current methods avoid such collapsed solutions by careful implementation details. We propose an objective function that naturally avoids such collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the representation vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow's redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. It allows the use of very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.
Addressing the Topological Defects of Disentanglement via Distributed Operators
Feb 10, 2021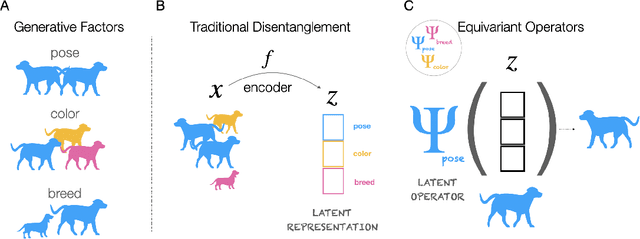
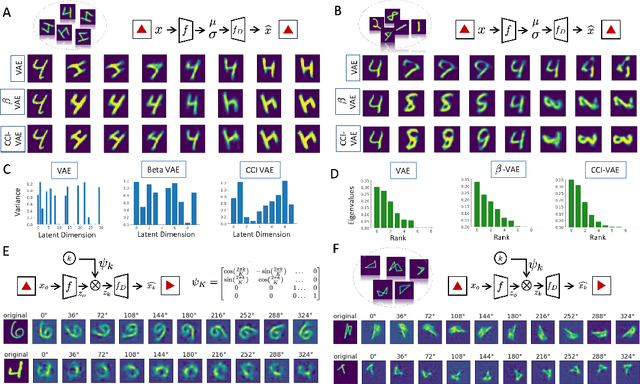
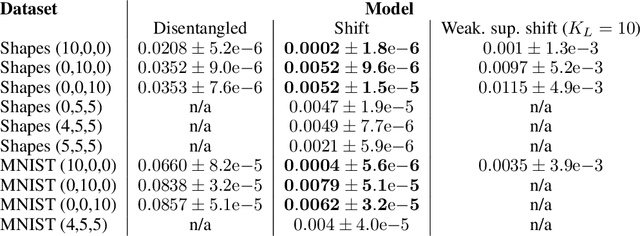
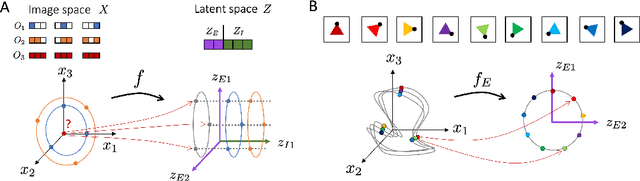
A core challenge in Machine Learning is to learn to disentangle natural factors of variation in data (e.g. object shape vs. pose). A popular approach to disentanglement consists in learning to map each of these factors to distinct subspaces of a model's latent representation. However, this approach has shown limited empirical success to date. Here, we show that, for a broad family of transformations acting on images--encompassing simple affine transformations such as rotations and translations--this approach to disentanglement introduces topological defects (i.e. discontinuities in the encoder). Motivated by classical results from group representation theory, we study an alternative, more flexible approach to disentanglement which relies on distributed latent operators, potentially acting on the entire latent space. We theoretically and empirically demonstrate the effectiveness of this approach to disentangle affine transformations. Our work lays a theoretical foundation for the recent success of a new generation of models using distributed operators for disentanglement.