 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReassessing the Validity of Spurious Correlations Benchmarks
Sep 06, 2024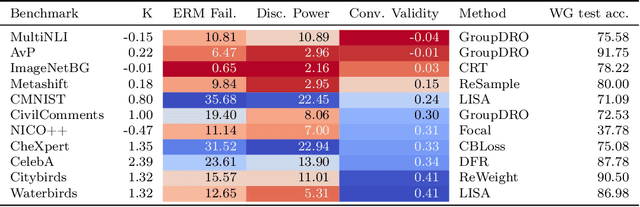
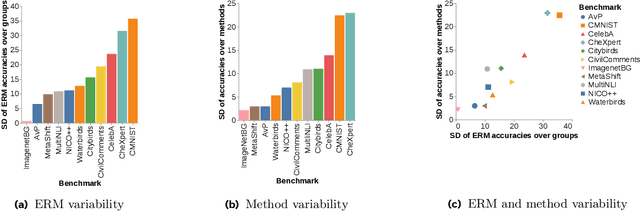
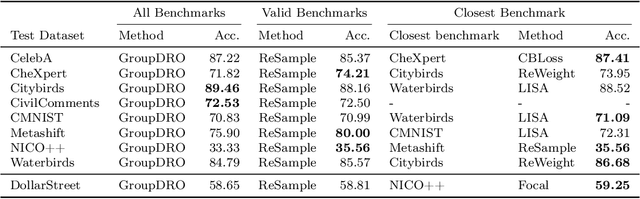
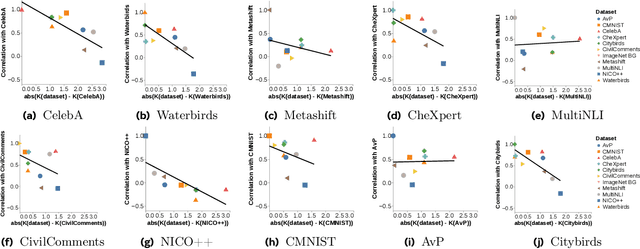
Neural networks can fail when the data contains spurious correlations. To understand this phenomenon, researchers have proposed numerous spurious correlations benchmarks upon which to evaluate mitigation methods. However, we observe that these benchmarks exhibit substantial disagreement, with the best methods on one benchmark performing poorly on another. We explore this disagreement, and examine benchmark validity by defining three desiderata that a benchmark should satisfy in order to meaningfully evaluate methods. Our results have implications for both benchmarks and mitigations: we find that certain benchmarks are not meaningful measures of method performance, and that several methods are not sufficiently robust for widespread use. We present a simple recipe for practitioners to choose methods using the most similar benchmark to their given problem.
UniBench: Visual Reasoning Requires Rethinking Vision-Language Beyond Scaling
Aug 09, 2024



Significant research efforts have been made to scale and improve vision-language model (VLM) training approaches. Yet, with an ever-growing number of benchmarks, researchers are tasked with the heavy burden of implementing each protocol, bearing a non-trivial computational cost, and making sense of how all these benchmarks translate into meaningful axes of progress. To facilitate a systematic evaluation of VLM progress, we introduce UniBench: a unified implementation of 50+ VLM benchmarks spanning a comprehensive range of carefully categorized capabilities from object recognition to spatial awareness, counting, and much more. We showcase the utility of UniBench for measuring progress by evaluating nearly 60 publicly available vision-language models, trained on scales of up to 12.8B samples. We find that while scaling training data or model size can boost many vision-language model capabilities, scaling offers little benefit for reasoning or relations. Surprisingly, we also discover today's best VLMs struggle on simple digit recognition and counting tasks, e.g. MNIST, which much simpler networks can solve. Where scale falls short, we find that more precise interventions, such as data quality or tailored-learning objectives offer more promise. For practitioners, we also offer guidance on selecting a suitable VLM for a given application. Finally, we release an easy-to-run UniBench code-base with the full set of 50+ benchmarks and comparisons across 59 models as well as a distilled, representative set of benchmarks that runs in 5 minutes on a single GPU.
$\mathbb{X}$-Sample Contrastive Loss: Improving Contrastive Learning with Sample Similarity Graphs
Jul 25, 2024



Learning good representations involves capturing the diverse ways in which data samples relate. Contrastive loss - an objective matching related samples - underlies methods from self-supervised to multimodal learning. Contrastive losses, however, can be viewed more broadly as modifying a similarity graph to indicate how samples should relate in the embedding space. This view reveals a shortcoming in contrastive learning: the similarity graph is binary, as only one sample is the related positive sample. Crucially, similarities \textit{across} samples are ignored. Based on this observation, we revise the standard contrastive loss to explicitly encode how a sample relates to others. We experiment with this new objective, called $\mathbb{X}$-Sample Contrastive, to train vision models based on similarities in class or text caption descriptions. Our study spans three scales: ImageNet-1k with 1 million, CC3M with 3 million, and CC12M with 12 million samples. The representations learned via our objective outperform both contrastive self-supervised and vision-language models trained on the same data across a range of tasks. When training on CC12M, we outperform CLIP by $0.6\%$ on both ImageNet and ImageNet Real. Our objective appears to work particularly well in lower-data regimes, with gains over CLIP of $16.8\%$ on ImageNet and $18.1\%$ on ImageNet Real when training with CC3M. Finally, our objective seems to encourage the model to learn representations that separate objects from their attributes and backgrounds, with gains of $3.3$-$5.6$\% over CLIP on ImageNet9. We hope the proposed solution takes a small step towards developing richer learning objectives for understanding sample relations in foundation models.
The Factorization Curse: Which Tokens You Predict Underlie the Reversal Curse and More
Jun 07, 2024



Today's best language models still struggle with hallucinations: factually incorrect generations, which impede their ability to reliably retrieve information seen during training. The reversal curse, where models cannot recall information when probed in a different order than was encountered during training, exemplifies this in information retrieval. We reframe the reversal curse as a factorization curse - a failure of models to learn the same joint distribution under different factorizations. Through a series of controlled experiments with increasing levels of realism including WikiReversal, a setting we introduce to closely simulate a knowledge intensive finetuning task, we find that the factorization curse is an inherent failure of the next-token prediction objective used in popular large language models. Moreover, we demonstrate reliable information retrieval cannot be solved with scale, reversed tokens, or even naive bidirectional-attention training. Consequently, various approaches to finetuning on specialized data would necessarily provide mixed results on downstream tasks, unless the model has already seen the right sequence of tokens. Across five tasks of varying levels of complexity, our results uncover a promising path forward: factorization-agnostic objectives can significantly mitigate the reversal curse and hint at improved knowledge storage and planning capabilities.
An Introduction to Vision-Language Modeling
May 27, 2024


Following the recent popularity of Large Language Models (LLMs), several attempts have been made to extend them to the visual domain. From having a visual assistant that could guide us through unfamiliar environments to generative models that produce images using only a high-level text description, the vision-language model (VLM) applications will significantly impact our relationship with technology. However, there are many challenges that need to be addressed to improve the reliability of those models. While language is discrete, vision evolves in a much higher dimensional space in which concepts cannot always be easily discretized. To better understand the mechanics behind mapping vision to language, we present this introduction to VLMs which we hope will help anyone who would like to enter the field. First, we introduce what VLMs are, how they work, and how to train them. Then, we present and discuss approaches to evaluate VLMs. Although this work primarily focuses on mapping images to language, we also discuss extending VLMs to videos.
Embracing Diversity: Interpretable Zero-shot classification beyond one vector per class
Apr 25, 2024



Vision-language models enable open-world classification of objects without the need for any retraining. While this zero-shot paradigm marks a significant advance, even today's best models exhibit skewed performance when objects are dissimilar from their typical depiction. Real world objects such as pears appear in a variety of forms -- from diced to whole, on a table or in a bowl -- yet standard VLM classifiers map all instances of a class to a \it{single vector based on the class label}. We argue that to represent this rich diversity within a class, zero-shot classification should move beyond a single vector. We propose a method to encode and account for diversity within a class using inferred attributes, still in the zero-shot setting without retraining. We find our method consistently outperforms standard zero-shot classification over a large suite of datasets encompassing hierarchies, diverse object states, and real-world geographic diversity, as well finer-grained datasets where intra-class diversity may be less prevalent. Importantly, our method is inherently interpretable, offering faithful explanations for each inference to facilitate model debugging and enhance transparency. We also find our method scales efficiently to a large number of attributes to account for diversity -- leading to more accurate predictions for atypical instances. Finally, we characterize a principled trade-off between overall and worst class accuracy, which can be tuned via a hyperparameter of our method. We hope this work spurs further research into the promise of zero-shot classification beyond a single class vector for capturing diversity in the world, and building transparent AI systems without compromising performance.
Self-Supervised Disentanglement by Leveraging Structure in Data Augmentations
Nov 15, 2023

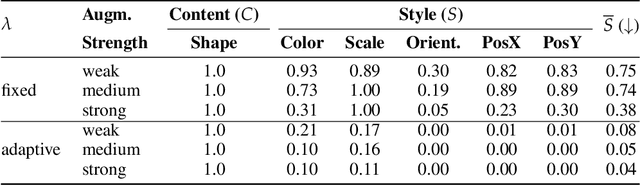

Self-supervised representation learning often uses data augmentations to induce some invariance to "style" attributes of the data. However, with downstream tasks generally unknown at training time, it is difficult to deduce a priori which attributes of the data are indeed "style" and can be safely discarded. To address this, we introduce a more principled approach that seeks to disentangle style features rather than discard them. The key idea is to add multiple style embedding spaces where: (i) each is invariant to all-but-one augmentation; and (ii) joint entropy is maximized. We formalize our structured data-augmentation procedure from a causal latent-variable-model perspective, and prove identifiability of both content and (multiple blocks of) style variables. We empirically demonstrate the benefits of our approach on synthetic datasets and then present promising but limited results on ImageNet.
Discovering environments with XRM
Sep 28, 2023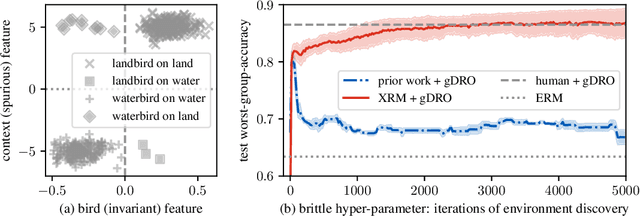
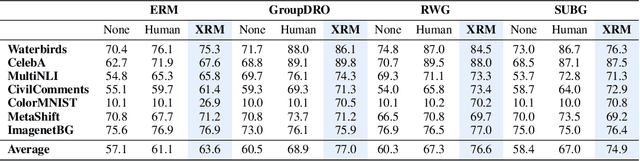
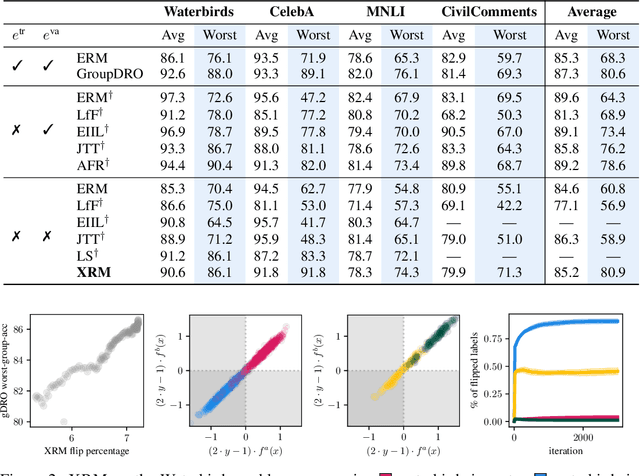

Successful out-of-distribution generalization requires environment annotations. Unfortunately, these are resource-intensive to obtain, and their relevance to model performance is limited by the expectations and perceptual biases of human annotators. Therefore, to enable robust AI systems across applications, we must develop algorithms to automatically discover environments inducing broad generalization. Current proposals, which divide examples based on their training error, suffer from one fundamental problem. These methods add hyper-parameters and early-stopping criteria that are impossible to tune without a validation set with human-annotated environments, the very information subject to discovery. In this paper, we propose Cross-Risk-Minimization (XRM) to address this issue. XRM trains two twin networks, each learning from one random half of the training data, while imitating confident held-out mistakes made by its sibling. XRM provides a recipe for hyper-parameter tuning, does not require early-stopping, and can discover environments for all training and validation data. Domain generalization algorithms built on top of XRM environments achieve oracle worst-group-accuracy, solving a long-standing problem in out-of-distribution generalization.
PUG: Photorealistic and Semantically Controllable Synthetic Data for Representation Learning
Aug 08, 2023



Synthetic image datasets offer unmatched advantages for designing and evaluating deep neural networks: they make it possible to (i) render as many data samples as needed, (ii) precisely control each scene and yield granular ground truth labels (and captions), (iii) precisely control distribution shifts between training and testing to isolate variables of interest for sound experimentation. Despite such promise, the use of synthetic image data is still limited -- and often played down -- mainly due to their lack of realism. Most works therefore rely on datasets of real images, which have often been scraped from public images on the internet, and may have issues with regards to privacy, bias, and copyright, while offering little control over how objects precisely appear. In this work, we present a path to democratize the use of photorealistic synthetic data: we develop a new generation of interactive environments for representation learning research, that offer both controllability and realism. We use the Unreal Engine, a powerful game engine well known in the entertainment industry, to produce PUG (Photorealistic Unreal Graphics) environments and datasets for representation learning. In this paper, we demonstrate the potential of PUG to enable more rigorous evaluations of vision models.
Does Progress On Object Recognition Benchmarks Improve Real-World Generalization?
Jul 24, 2023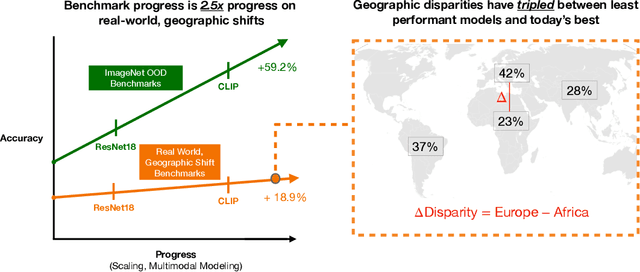

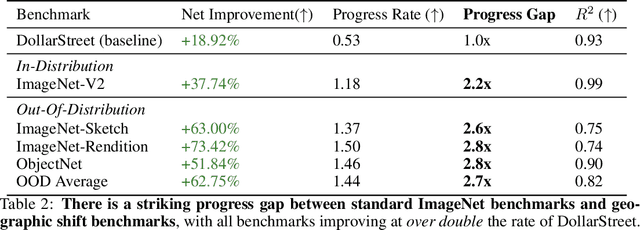
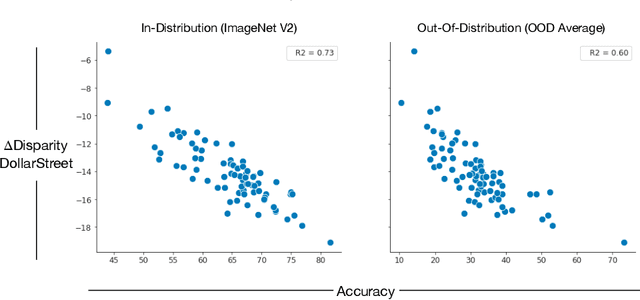
For more than a decade, researchers have measured progress in object recognition on ImageNet-based generalization benchmarks such as ImageNet-A, -C, and -R. Recent advances in foundation models, trained on orders of magnitude more data, have begun to saturate these standard benchmarks, but remain brittle in practice. This suggests standard benchmarks, which tend to focus on predefined or synthetic changes, may not be sufficient for measuring real world generalization. Consequently, we propose studying generalization across geography as a more realistic measure of progress using two datasets of objects from households across the globe. We conduct an extensive empirical evaluation of progress across nearly 100 vision models up to most recent foundation models. We first identify a progress gap between standard benchmarks and real-world, geographical shifts: progress on ImageNet results in up to 2.5x more progress on standard generalization benchmarks than real-world distribution shifts. Second, we study model generalization across geographies by measuring the disparities in performance across regions, a more fine-grained measure of real world generalization. We observe all models have large geographic disparities, even foundation CLIP models, with differences of 7-20% in accuracy between regions. Counter to modern intuition, we discover progress on standard benchmarks fails to improve geographic disparities and often exacerbates them: geographic disparities between the least performant models and today's best models have more than tripled. Our results suggest scaling alone is insufficient for consistent robustness to real-world distribution shifts. Finally, we highlight in early experiments how simple last layer retraining on more representative, curated data can complement scaling as a promising direction of future work, reducing geographic disparity on both benchmarks by over two-thirds.