 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
An Epistemic Human-Aware Task Planner which Anticipates Human Beliefs and Decisions
Sep 27, 2024We present a substantial extension of our Human-Aware Task Planning framework, tailored for scenarios with intermittent shared execution experiences and significant belief divergence between humans and robots, particularly due to the uncontrollable nature of humans. Our objective is to build a robot policy that accounts for uncontrollable human behaviors, thus enabling the anticipation of possible advancements achieved by the robot when the execution is not shared, e.g. when humans are briefly absent from the shared environment to complete a subtask. But, this anticipation is considered from the perspective of humans who have access to an estimated model for the robot. To this end, we propose a novel planning framework and build a solver based on AND-OR search, which integrates knowledge reasoning, including situation assessment by perspective taking. Our approach dynamically models and manages the expansion and contraction of potential advances while precisely keeping track of when (and when not) agents share the task execution experience. The planner systematically assesses the situation and ignores worlds that it has reason to think are impossible for humans. Overall, our new solver can estimate the distinct beliefs of the human and the robot along potential courses of action, enabling the synthesis of plans where the robot selects the right moment for communication, i.e. informing, or replying to an inquiry, or defers ontic actions until the execution experiences can be shared. Preliminary experiments in two domains, one novel and one adapted, demonstrate the effectiveness of the framework.
PUG: Photorealistic and Semantically Controllable Synthetic Data for Representation Learning
Aug 08, 2023



Synthetic image datasets offer unmatched advantages for designing and evaluating deep neural networks: they make it possible to (i) render as many data samples as needed, (ii) precisely control each scene and yield granular ground truth labels (and captions), (iii) precisely control distribution shifts between training and testing to isolate variables of interest for sound experimentation. Despite such promise, the use of synthetic image data is still limited -- and often played down -- mainly due to their lack of realism. Most works therefore rely on datasets of real images, which have often been scraped from public images on the internet, and may have issues with regards to privacy, bias, and copyright, while offering little control over how objects precisely appear. In this work, we present a path to democratize the use of photorealistic synthetic data: we develop a new generation of interactive environments for representation learning research, that offer both controllability and realism. We use the Unreal Engine, a powerful game engine well known in the entertainment industry, to produce PUG (Photorealistic Unreal Graphics) environments and datasets for representation learning. In this paper, we demonstrate the potential of PUG to enable more rigorous evaluations of vision models.
Multi-Task Learning Improves Performance In Deep Argument Mining Models
Jul 03, 2023The successful analysis of argumentative techniques from user-generated text is central to many downstream tasks such as political and market analysis. Recent argument mining tools use state-of-the-art deep learning methods to extract and annotate argumentative techniques from various online text corpora, however each task is treated as separate and different bespoke models are fine-tuned for each dataset. We show that different argument mining tasks share common semantic and logical structure by implementing a multi-task approach to argument mining that achieves better performance than state-of-the-art methods for the same problems. Our model builds a shared representation of the input text that is common to all tasks and exploits similarities between tasks in order to further boost performance via parameter-sharing. Our results are important for argument mining as they show that different tasks share substantial similarities and suggest a holistic approach to the extraction of argumentative techniques from text.
Objectives Matter: Understanding the Impact of Self-Supervised Objectives on Vision Transformer Representations
Apr 25, 2023Joint-embedding based learning (e.g., SimCLR, MoCo, DINO) and reconstruction-based learning (e.g., BEiT, SimMIM, MAE) are the two leading paradigms for self-supervised learning of vision transformers, but they differ substantially in their transfer performance. Here, we aim to explain these differences by analyzing the impact of these objectives on the structure and transferability of the learned representations. Our analysis reveals that reconstruction-based learning features are significantly dissimilar to joint-embedding based learning features and that models trained with similar objectives learn similar features even across architectures. These differences arise early in the network and are primarily driven by attention and normalization layers. We find that joint-embedding features yield better linear probe transfer for classification because the different objectives drive different distributions of information and invariances in the learned representation. These differences explain opposite trends in transfer performance for downstream tasks that require spatial specificity in features. Finally, we address how fine-tuning changes reconstructive representations to enable better transfer, showing that fine-tuning re-organizes the information to be more similar to pre-trained joint embedding models.
A Cookbook of Self-Supervised Learning
Apr 24, 2023



Self-supervised learning, dubbed the dark matter of intelligence, is a promising path to advance machine learning. Yet, much like cooking, training SSL methods is a delicate art with a high barrier to entry. While many components are familiar, successfully training a SSL method involves a dizzying set of choices from the pretext tasks to training hyper-parameters. Our goal is to lower the barrier to entry into SSL research by laying the foundations and latest SSL recipes in the style of a cookbook. We hope to empower the curious researcher to navigate the terrain of methods, understand the role of the various knobs, and gain the know-how required to explore how delicious SSL can be.
UNet Based Pipeline for Lung Segmentation from Chest X-Ray Images
Dec 09, 2022



Biomedical image segmentation is one of the fastest growing fields which has seen extensive automation through the use of Artificial Intelligence. This has enabled widespread adoption of accurate techniques to expedite the screening and diagnostic processes which would otherwise take several days to finalize. In this paper, we present an end-to-end pipeline to segment lungs from chest X-ray images, training the neural network model on the Japanese Society of Radiological Technology (JSRT) dataset, using UNet to enable faster processing of initial screening for various lung disorders. The pipeline developed can be readily used by medical centers with just the provision of X-Ray images as input. The model will perform the preprocessing, and provide a segmented image as the final output. It is expected that this will drastically reduce the manual effort involved and lead to greater accessibility in resource-constrained locations.
Robust Planning for Human-Robot Joint Tasks with Explicit Reasoning on Human Mental State
Oct 17, 2022
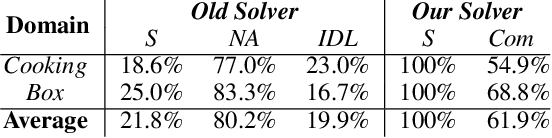
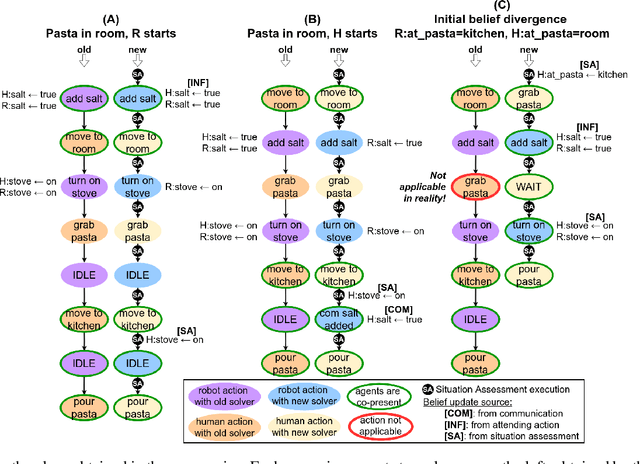
We consider the human-aware task planning problem where a human-robot team is given a shared task with a known objective to achieve. Recent approaches tackle it by modeling it as a team of independent, rational agents, where the robot plans for both agents' (shared) tasks. However, the robot knows that humans cannot be administered like artificial agents, so it emulates and predicts the human's decisions, actions, and reactions. Based on earlier approaches, we describe a novel approach to solve such problems, which models and uses execution-time observability conventions. Abstractly, this modeling is based on situation assessment, which helps our approach capture the evolution of individual agents' beliefs and anticipate belief divergences that arise in practice. It decides if and when belief alignment is needed and achieves it with communication. These changes improve the solver's performance: (a) communication is effectively used, and (b) robust for more realistic and challenging problems.
Beyond neural scaling laws: beating power law scaling via data pruning
Jun 29, 2022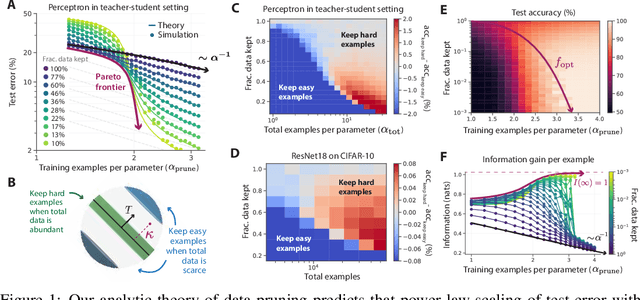

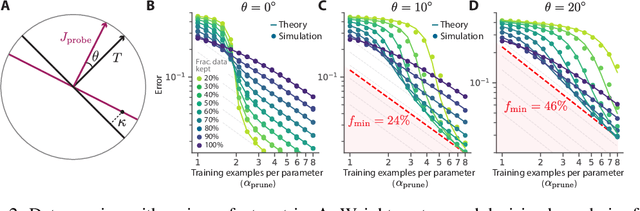

Widely observed neural scaling laws, in which error falls off as a power of the training set size, model size, or both, have driven substantial performance improvements in deep learning. However, these improvements through scaling alone require considerable costs in compute and energy. Here we focus on the scaling of error with dataset size and show how both in theory and practice we can break beyond power law scaling and reduce it to exponential scaling instead if we have access to a high-quality data pruning metric that ranks the order in which training examples should be discarded to achieve any pruned dataset size. We then test this new exponential scaling prediction with pruned dataset size empirically, and indeed observe better than power law scaling performance on ResNets trained on CIFAR-10, SVHN, and ImageNet. Given the importance of finding high-quality pruning metrics, we perform the first large-scale benchmarking study of ten different data pruning metrics on ImageNet. We find most existing high performing metrics scale poorly to ImageNet, while the best are computationally intensive and require labels for every image. We therefore developed a new simple, cheap and scalable self-supervised pruning metric that demonstrates comparable performance to the best supervised metrics. Overall, our work suggests that the discovery of good data-pruning metrics may provide a viable path forward to substantially improved neural scaling laws, thereby reducing the resource costs of modern deep learning.
An Ensemble Model for Face Liveness Detection
Jan 19, 2022
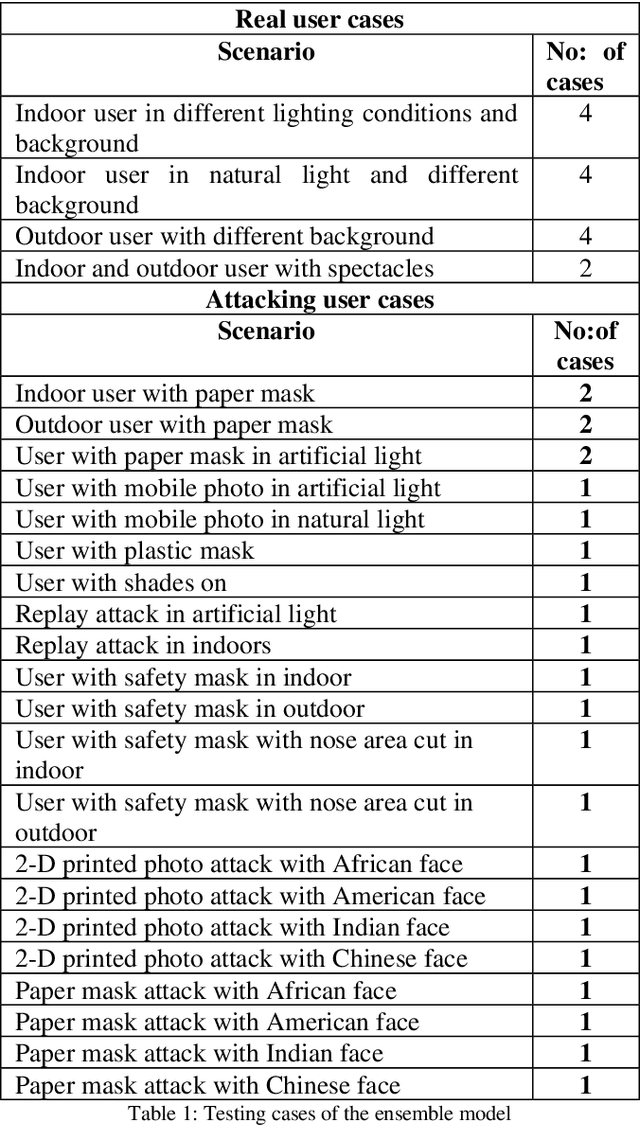
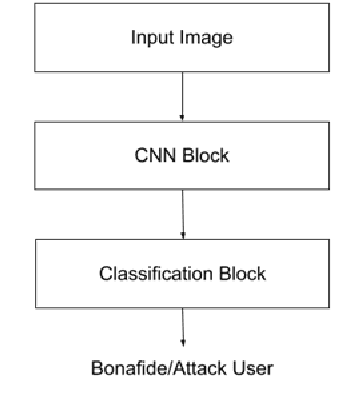
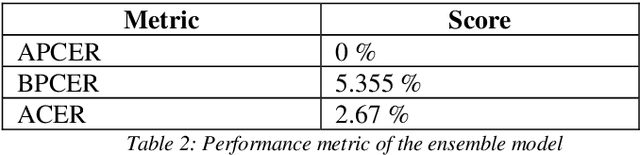
In this paper, we present a passive method to detect face presentation attack a.k.a face liveness detection using an ensemble deep learning technique. Face liveness detection is one of the key steps involved in user identity verification of customers during the online onboarding/transaction processes. During identity verification, an unauthenticated user tries to bypass the verification system by several means, for example, they can capture a user photo from social media and do an imposter attack using printouts of users faces or using a digital photo from a mobile device and even create a more sophisticated attack like video replay attack. We have tried to understand the different methods of attack and created an in-house large-scale dataset covering all the kinds of attacks to train a robust deep learning model. We propose an ensemble method where multiple features of the face and background regions are learned to predict whether the user is a bonafide or an attacker.