 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble Model for Face Liveness Detection
Jan 19, 2022
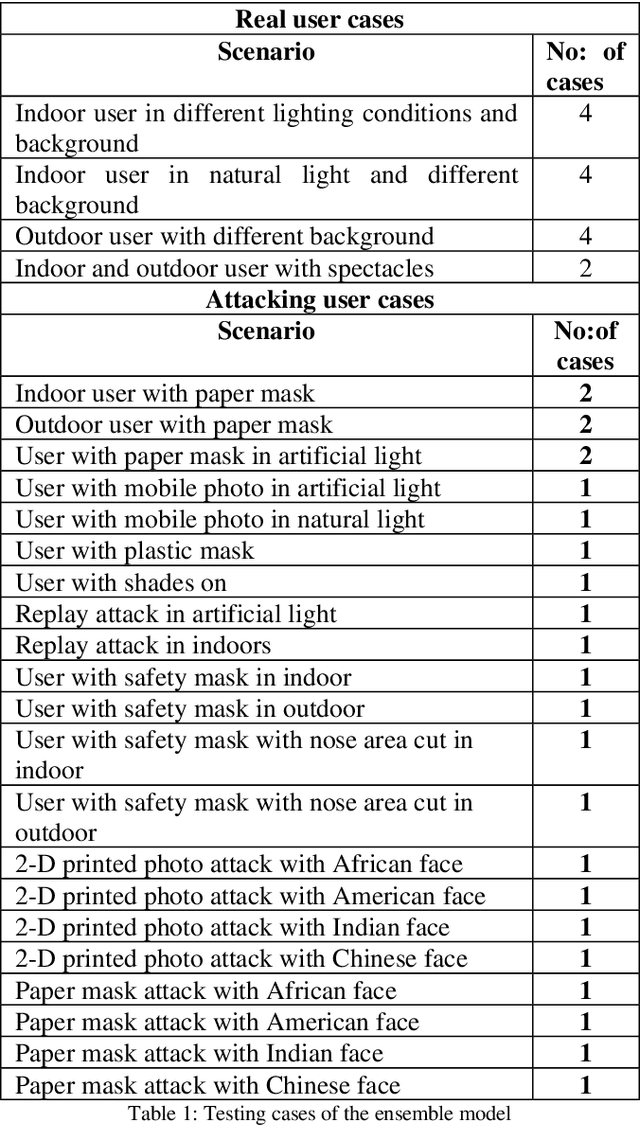
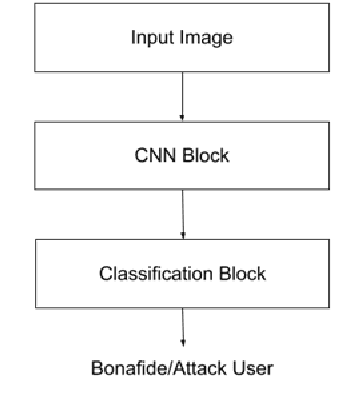
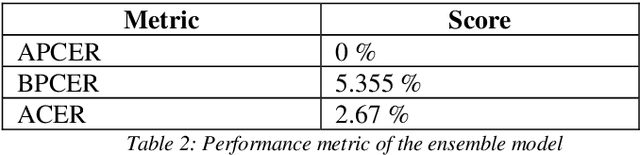
In this paper, we present a passive method to detect face presentation attack a.k.a face liveness detection using an ensemble deep learning technique. Face liveness detection is one of the key steps involved in user identity verification of customers during the online onboarding/transaction processes. During identity verification, an unauthenticated user tries to bypass the verification system by several means, for example, they can capture a user photo from social media and do an imposter attack using printouts of users faces or using a digital photo from a mobile device and even create a more sophisticated attack like video replay attack. We have tried to understand the different methods of attack and created an in-house large-scale dataset covering all the kinds of attacks to train a robust deep learning model. We propose an ensemble method where multiple features of the face and background regions are learned to predict whether the user is a bonafide or an attacker.
A Comparative study of Hyper-Parameter Optimization Tools
Jan 17, 2022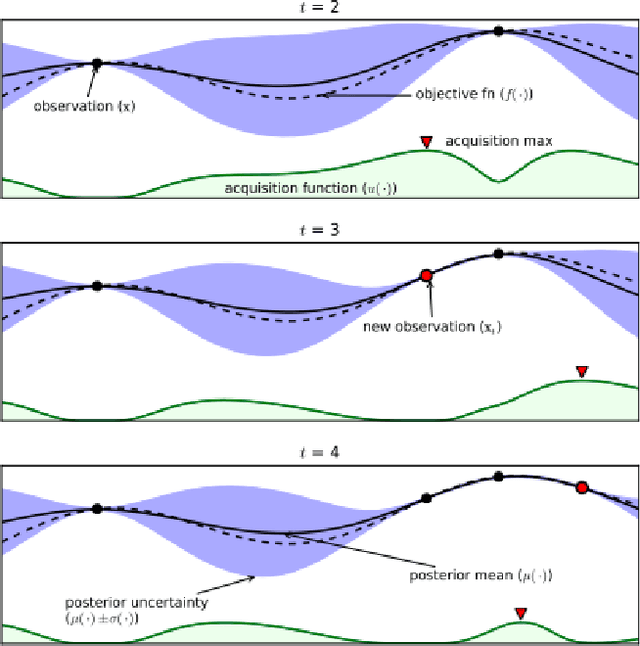
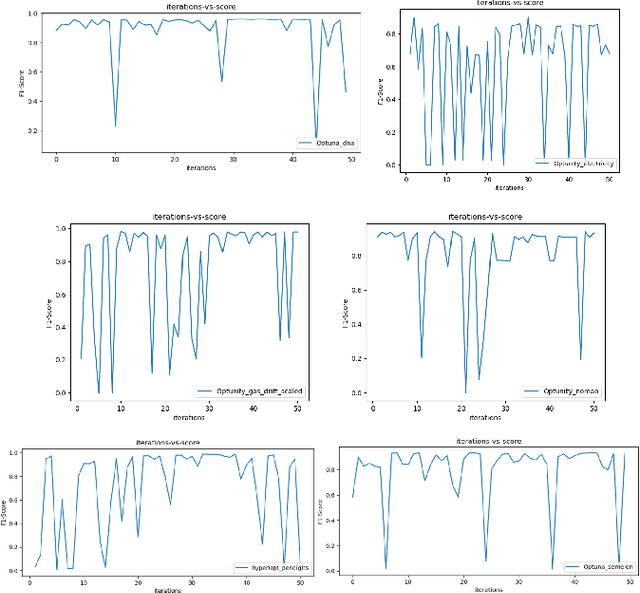
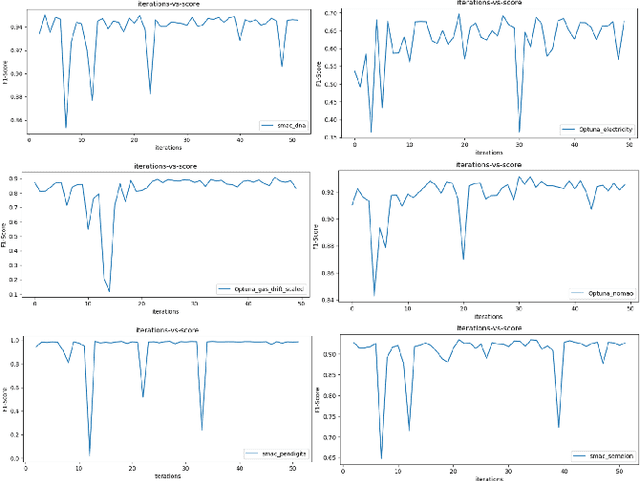
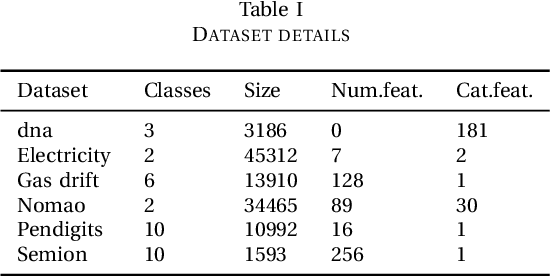
Most of the machine learning models have associated hyper-parameters along with their parameters. While the algorithm gives the solution for parameters, its utility for model performance is highly dependent on the choice of hyperparameters. For a robust performance of a model, it is necessary to find out the right hyper-parameter combination. Hyper-parameter optimization (HPO) is a systematic process that helps in finding the right values for them. The conventional methods for this purpose are grid search and random search and both methods create issues in industrial-scale applications. Hence a set of strategies have been recently proposed based on Bayesian optimization and evolutionary algorithm principles that help in runtime issues in a production environment and robust performance. In this paper, we compare the performance of four python libraries, namely Optuna, Hyper-opt, Optunity, and sequential model-based algorithm configuration (SMAC) that has been proposed for hyper-parameter optimization. The performance of these tools is tested using two benchmarks. The first one is to solve a combined algorithm selection and hyper-parameter optimization (CASH) problem The second one is the NeurIPS black-box optimization challenge in which a multilayer perception (MLP) architecture has to be chosen from a set of related architecture constraints and hyper-parameters. The benchmarking is done with six real-world datasets. From the experiments, we found that Optuna has better performance for CASH problem and HyperOpt for MLP problem.
An efficient scheme based on graph centrality to select nodes for training for effective learning
May 19, 2021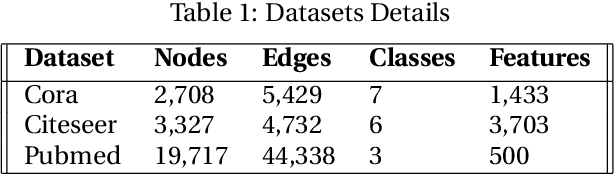
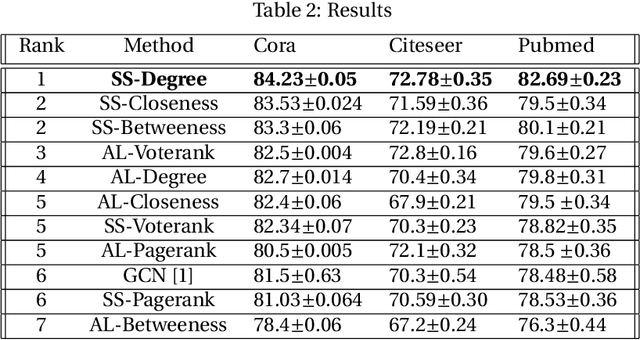
The process of selecting points for training a machine learning model is often a challenging task. Many times, we will have a lot of data, but for training, we require the labels and labeling is often costly. So we need to select the points for training in an efficient manner so that the model trained on the points selected will be better than the ones trained on any other training set. We propose a novel method to select the nodes in graph datasets using the concept of graph centrality. Two methods are proposed - one using a smart selection strategy, where the model is required to be trained only once and another using active learning method. We have tested this idea on three popular graph datasets - Cora, Citeseer and Pubmed- and the results are found to be encouraging.
Neighborhood Preserving Kernels for Attributed Graphs
Oct 13, 2020
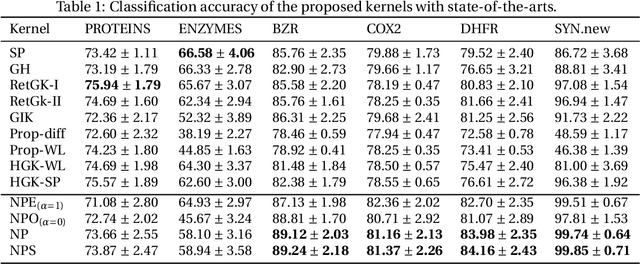
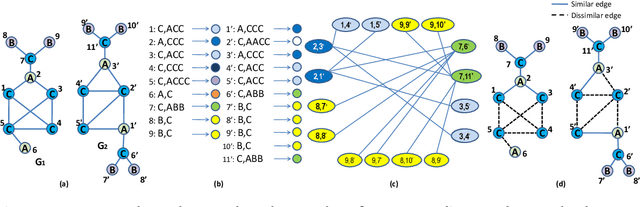
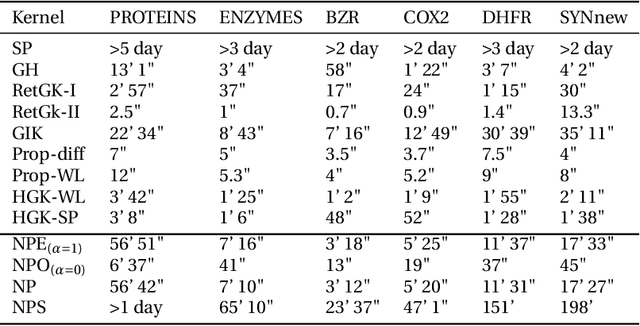
We describe the design of a reproducing kernel suitable for attributed graphs, in which the similarity between the two graphs is defined based on the neighborhood information of the graph nodes with the aid of a product graph formulation. We represent the proposed kernel as the weighted sum of two other kernels of which one is an R-convolution kernel that processes the attribute information of the graph and the other is an optimal assignment kernel that processes label information. They are formulated in such a way that the edges processed as part of the kernel computation have the same neighborhood properties and hence the kernel proposed makes a well-defined correspondence between regions processed in graphs. These concepts are also extended to the case of the shortest paths. We identified the state-of-the-art kernels that can be mapped to such a neighborhood preserving framework. We found that the kernel value of the argument graphs in each iteration of the Weisfeiler-Lehman color refinement algorithm can be obtained recursively from the product graph formulated in our method. By incorporating the proposed kernel on support vector machines we analyzed the real-world data sets and it has shown superior performance in comparison with that of the other state-of-the-art graph kernels.
Framework for Designing Filters of Spectral Graph Convolutional Neural Networks in the Context of Regularization Theory
Sep 29, 2020
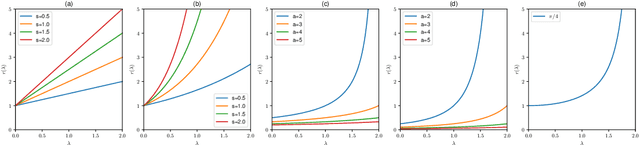

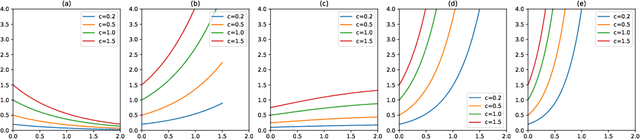
Graph convolutional neural networks (GCNNs) have been widely used in graph learning. It has been observed that the smoothness functional on graphs can be defined in terms of the graph Laplacian. This fact points out in the direction of using Laplacian in deriving regularization operators on graphs and its consequent use with spectral GCNN filter designs. In this work, we explore the regularization properties of graph Laplacian and proposed a generalized framework for regularized filter designs in spectral GCNNs. We found that the filters used in many state-of-the-art GCNNs can be derived as a special case of the framework we developed. We designed new filters that are associated with well-defined regularization behavior and tested their performance on semi-supervised node classification tasks. Their performance was found to be superior to that of the other state-of-the-art techniques.