 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Ensemble Model for Face Liveness Detection
Jan 19, 2022
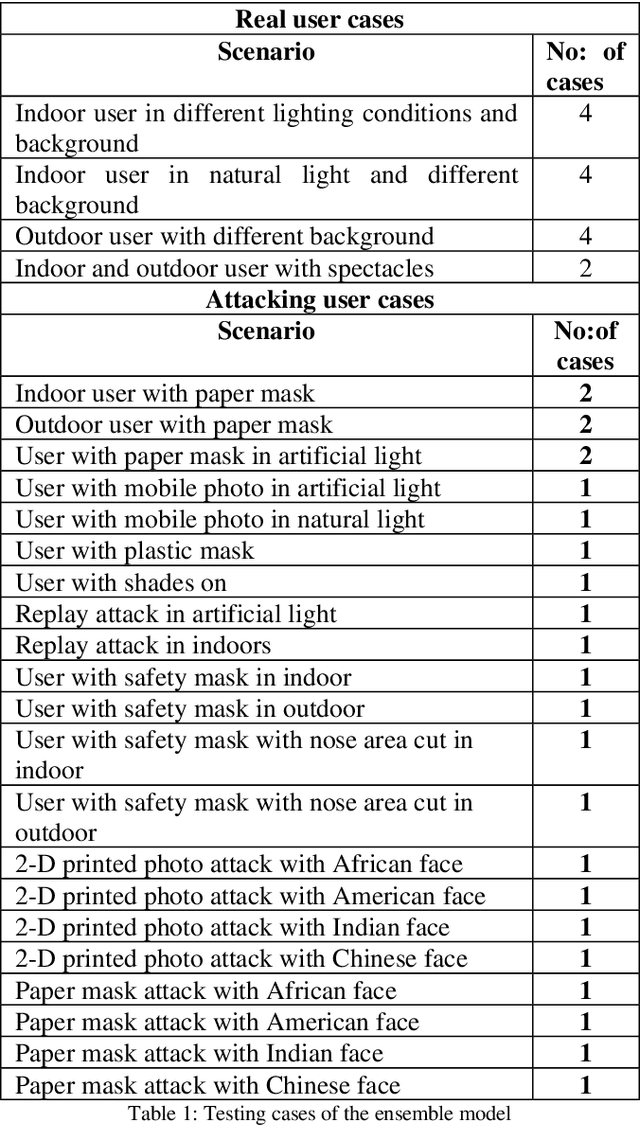
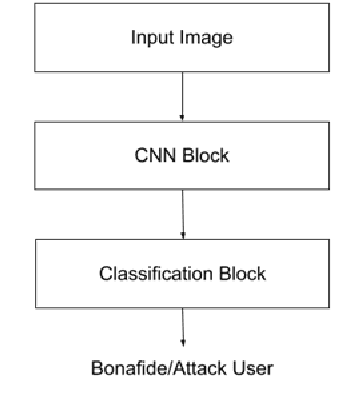
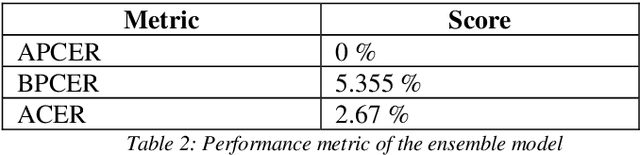
In this paper, we present a passive method to detect face presentation attack a.k.a face liveness detection using an ensemble deep learning technique. Face liveness detection is one of the key steps involved in user identity verification of customers during the online onboarding/transaction processes. During identity verification, an unauthenticated user tries to bypass the verification system by several means, for example, they can capture a user photo from social media and do an imposter attack using printouts of users faces or using a digital photo from a mobile device and even create a more sophisticated attack like video replay attack. We have tried to understand the different methods of attack and created an in-house large-scale dataset covering all the kinds of attacks to train a robust deep learning model. We propose an ensemble method where multiple features of the face and background regions are learned to predict whether the user is a bonafide or an attacker.
Towards Ophthalmologist Level Accurate Deep Learning System for OCT Screening and Diagnosis
Dec 12, 2018



In this work, we propose an advanced AI based grading system for OCT images. The proposed system is a very deep fully convolutional attentive classification network trained with end to end advanced transfer learning with online random augmentation. It uses quasi random augmentation that outputs confidence values for diseases prevalence during inference. Its a fully automated retinal OCT analysis AI system capable of pathological lesions understanding without any offline preprocessing/postprocessing step or manual feature extraction. We present a state of the art performance on the publicly available Mendeley OCT dataset.
Towards Radiologist-Level Accurate Deep Learning System for Pulmonary Screening
Jun 25, 2018



In this work, we propose advanced pneumonia and Tuberculosis grading system for X-ray images. The proposed system is a very deep fully convolutional classification network with online augmentation that outputs confidence values for diseases prevalence. Its a fully automated system capable of disease feature understanding without any offline preprocessing step or manual feature extraction. We have achieved state- of-the- art performance on the public databases such as ChestXray-14, Mendeley, Shenzhen Hospital X-ray and Belarus X-ray set.
Rethinking Convolutional Semantic Segmentation Learning
Oct 22, 2017



Deep convolutional semantic segmentation (DCSS) learning doesn't converge to an optimal local minimum with random parameters initializations; a pre-trained model on the same domain becomes necessary to achieve convergence.In this work, we propose a joint cooperative end-to-end learning method for DCSS. It addresses many drawbacks with existing deep semantic segmentation learning; the proposed approach simultaneously learn both segmentation and classification; taking away the essential need of the pre-trained model for learning convergence. We present an improved inception based architecture with partial attention gating (PAG) over encoder information. The PAG also adds to achieve faster convergence and better accuracy for segmentation task. We will show the effectiveness of this learning on a diabetic retinopathy classification and segmentation dataset.
Deep Learning: Generalization Requires Deep Compositional Feature Space Design
Jul 08, 2017



Generalization error defines the discriminability and the representation power of a deep model. In this work, we claim that feature space design using deep compositional function plays a significant role in generalization along with explicit and implicit regularizations. Our claims are being established with several image classification experiments. We show that the information loss due to convolution and max pooling can be marginalized with the compositional design, improving generalization performance. Also, we will show that learning rate decay acts as an implicit regularizer in deep model training.
Gated Siamese Convolutional Neural Network Architecture for Human Re-Identification
Sep 26, 2016

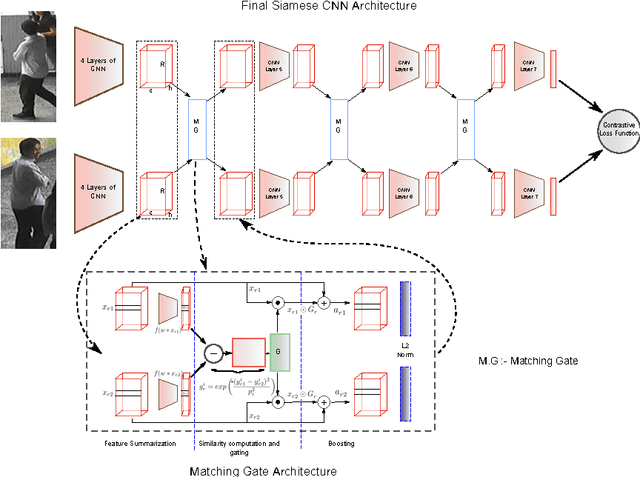
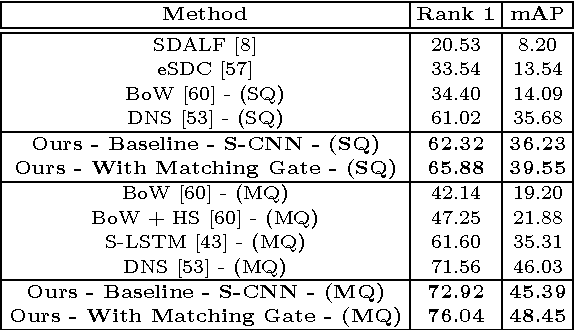
Matching pedestrians across multiple camera views, known as human re-identification, is a challenging research problem that has numerous applications in visual surveillance. With the resurgence of Convolutional Neural Networks (CNNs), several end-to-end deep Siamese CNN architectures have been proposed for human re-identification with the objective of projecting the images of similar pairs (i.e. same identity) to be closer to each other and those of dissimilar pairs to be distant from each other. However, current networks extract fixed representations for each image regardless of other images which are paired with it and the comparison with other images is done only at the final level. In this setting, the network is at risk of failing to extract finer local patterns that may be essential to distinguish positive pairs from hard negative pairs. In this paper, we propose a gating function to selectively emphasize such fine common local patterns by comparing the mid-level features across pairs of images. This produces flexible representations for the same image according to the images they are paired with. We conduct experiments on the CUHK03, Market-1501 and VIPeR datasets and demonstrate improved performance compared to a baseline Siamese CNN architecture.
Traffic Sign Classification Using Deep Inception Based Convolutional Networks
Jul 17, 2016



In this work, we propose a novel deep network for traffic sign classification that achieves outstanding performance on GTSRB surpassing all previous methods. Our deep network consists of spatial transformer layers and a modified version of inception module specifically designed for capturing local and global features together. This features adoption allows our network to classify precisely intraclass samples even under deformations. Use of spatial transformer layer makes this network more robust to deformations such as translation, rotation, scaling of input images. Unlike existing approaches that are developed with hand-crafted features, multiple deep networks with huge parameters and data augmentations, our method addresses the concern of exploding parameters and augmentations. We have achieved the state-of-the-art performance of 99.81\% on GTSRB dataset.
Improved Microaneurysm Detection using Deep Neural Networks
Jul 17, 2016



In this work, we propose a novel microaneurysm (MA) detection for early diabetic retinopathy screening using color fundus images. Since MA usually the first lesions to appear as an indicator of diabetic retinopathy, accurate detection of MA is necessary for treatment. Each pixel of the image is classified as either MA or non-MA using a deep neural network with dropout training procedure using maxout activation function. No preprocessing step or manual feature extraction is required. Substantial improvements over standard MA detection method based on the pipeline of preprocessing, feature extraction, classification followed by post processing is achieved. The presented method is evaluated in publicly available Retinopathy Online Challenge (ROC) and Diaretdb1v2 database and achieved state-of-the-art accuracy.
An Unsupervised Method for Detection and Validation of The Optic Disc and The Fovea
Jan 25, 2016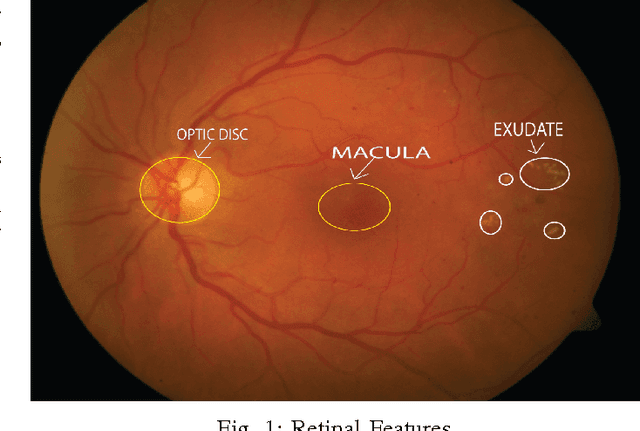

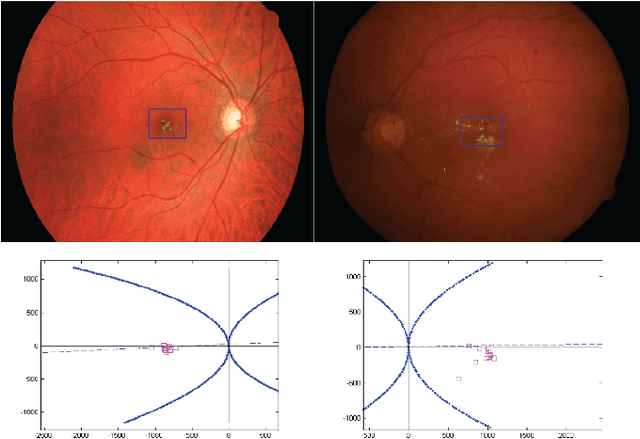
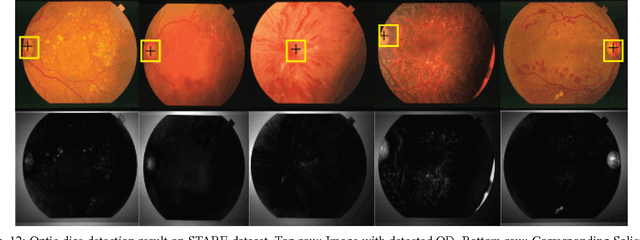
In this work, we have presented a novel method for detection of retinal image features, the optic disc and the fovea, from colour fundus photographs of dilated eyes for Computer-aided Diagnosis(CAD) system. A saliency map based method was used to detect the optic disc followed by an unsupervised probabilistic Latent Semantic Analysis for detection validation. The validation concept is based on distinct vessels structures in the optic disc. By using the clinical information of standard location of the fovea with respect to the optic disc, the macula region is estimated. Accuracy of 100\% detection is achieved for the optic disc and the macula on MESSIDOR and DIARETDB1 and 98.8\% detection accuracy on STARE dataset.
A Gaussian Scale Space Approach For Exudates Detection, Classification And Severity Prediction
May 04, 2015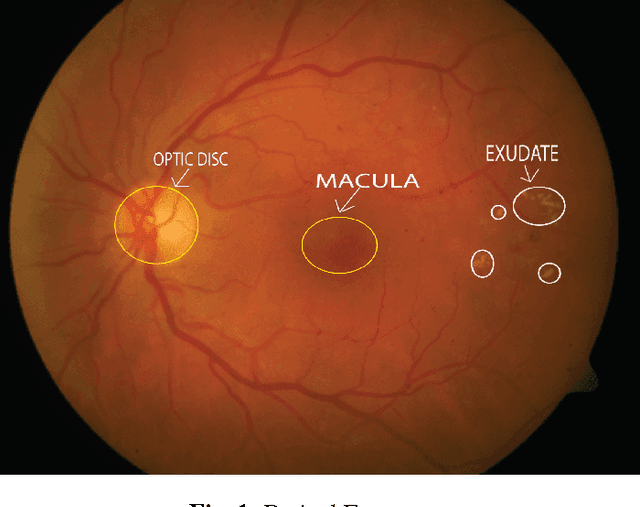
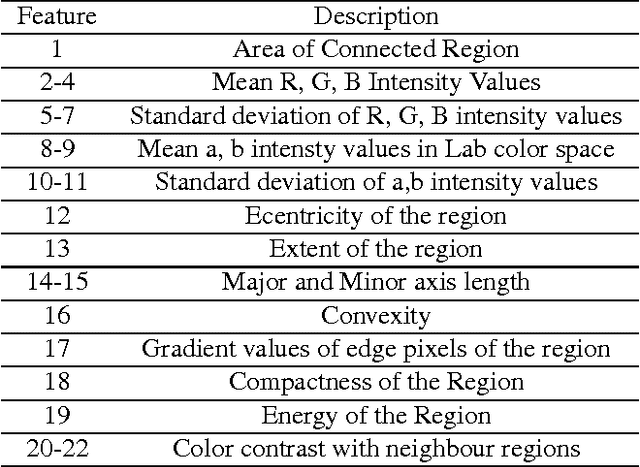
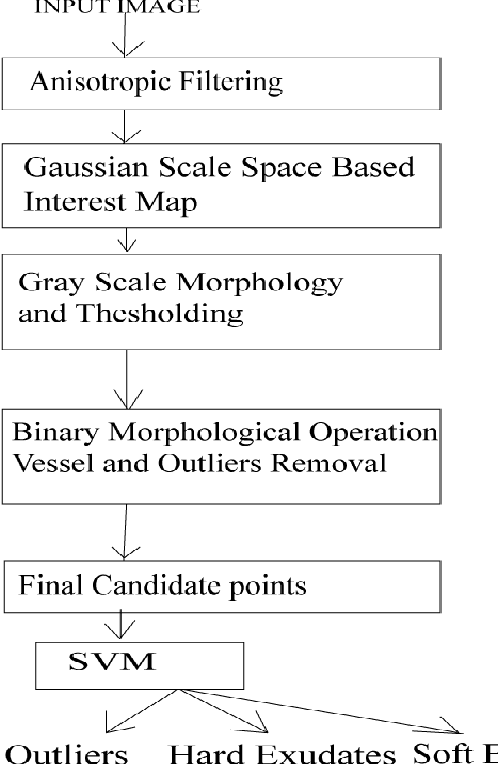

In the context of Computer Aided Diagnosis system for diabetic retinopathy, we present a novel method for detection of exudates and their classification for disease severity prediction. The method is based on Gaussian scale space based interest map and mathematical morphology. It makes use of support vector machine for classification and location information of the optic disc and the macula region for severity prediction. It can efficiently handle luminance variation and it is suitable for varied sized exudates. The method has been probed in publicly available DIARETDB1V2 and e-ophthaEX databases. For exudate detection the proposed method achieved a sensitivity of 96.54% and prediction of 98.35% in DIARETDB1V2 database.