 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Driver Monitoring Systems on Edge AI Device
Apr 04, 2023



As road accident cases are increasing due to the inattention of the driver, automated driver monitoring systems (DMS) have gained an increase in acceptance. In this report, we present a real-time DMS system that runs on a hardware-accelerator-based edge device. The system consists of an InfraRed camera to record the driver footage and an edge device to process the data. To successfully port the deep learning models to run on the edge device taking full advantage of the hardware accelerators, model surgery was performed. The final DMS system achieves 63 frames per second (FPS) on the TI-TDA4VM edge device.
Understanding the impact of mistakes on background regions in crowd counting
Mar 30, 2020
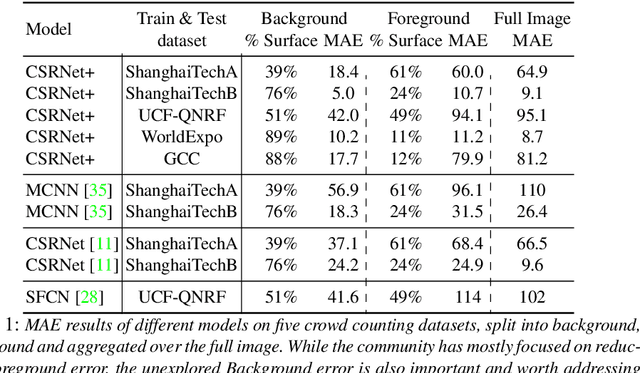

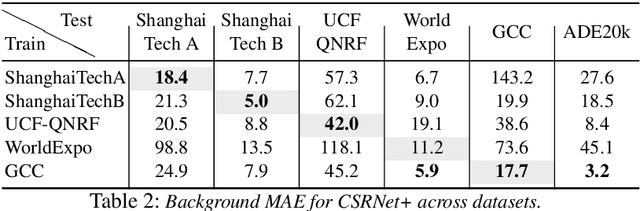
Every crowd counting researcher has likely observed their model output wrong positive predictions on image regions not containing any person. But how often do these mistakes happen? Are our models negatively affected by this? In this paper we analyze this problem in depth. In order to understand its magnitude, we present an extensive analysis on five of the most important crowd counting datasets. We present this analysis in two parts. First, we quantify the number of mistakes made by popular crowd counting approaches. Our results show that (i) mistakes on background are substantial and they are responsible for 18-49% of the total error, (ii) models do not generalize well to different kinds of backgrounds and perform poorly on completely background images, and (iii) models make many more mistakes than those captured by the standard Mean Absolute Error (MAE) metric, as counting on background compensates considerably for misses on foreground. And second, we quantify the performance change gained by helping the model better deal with this problem. We enrich a typical crowd counting network with a segmentation branch trained to suppress background predictions. This simple addition (i) reduces background error by 10-83%, (ii) reduces foreground error by up to 26% and (iii) improves overall crowd counting performance up to 20%. When compared against the literature, this simple technique achieves very competitive results on all datasets, on par with the state-of-the-art, showing the importance of tackling the background problem.
Scale-Aware Attention Network for Crowd Counting
Jan 17, 2019
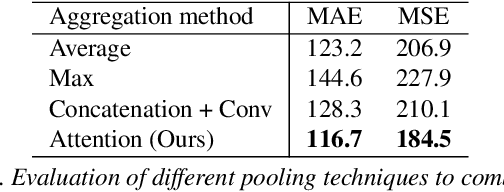
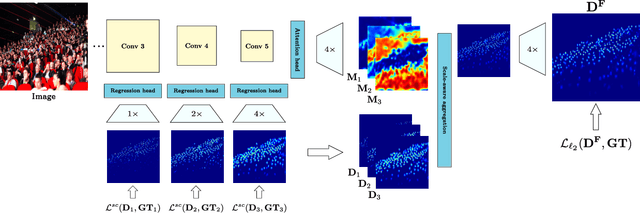
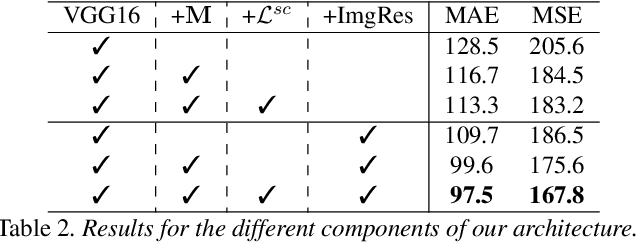
In crowd counting datasets, people appear at different scales, depending on their distance to the camera. To address this issue, we propose a novel multi-branch scale-aware attention network that exploits the hierarchical structure of convolutional neural networks and generates, in a single forward pass, multi-scale density predictions from different layers of the architecture. To aggregate these maps into our final prediction, we present a new soft attention mechanism that learns a set of gating masks. Furthermore, we introduce a scale-aware loss function to regularize the training of different branches and guide them to specialize on a particular scale. As this new training requires ground-truth annotations for the size of each head, we also propose a simple, yet effective technique to estimate it automatically. Finally, we present an ablation study on each of these components and compare our approach against the literature on 4 crowd counting datasets: UCF-QNRF, ShanghaiTech A & B and UCF_CC_50. Without bells and whistles, our approach achieves state-of-the-art on all these datasets. We observe a remarkable improvement on the UCF-QNRF (25%) and a significant one on the others (around 10%).
Gated Siamese Convolutional Neural Network Architecture for Human Re-Identification
Sep 26, 2016

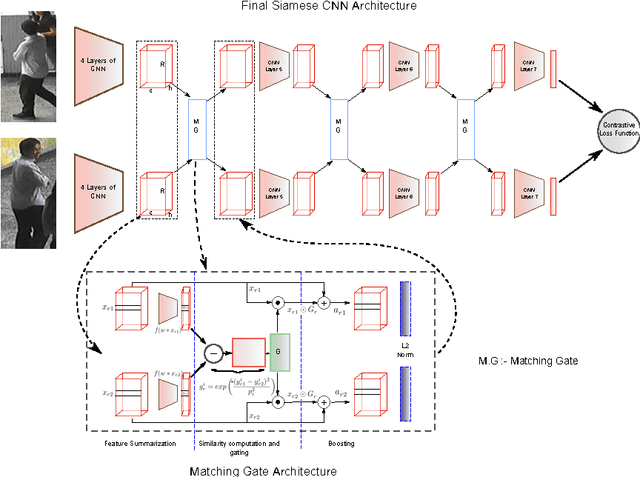
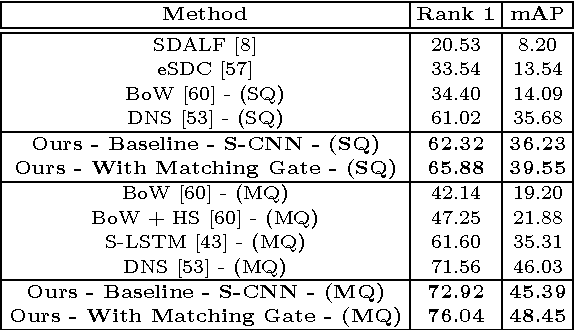
Matching pedestrians across multiple camera views, known as human re-identification, is a challenging research problem that has numerous applications in visual surveillance. With the resurgence of Convolutional Neural Networks (CNNs), several end-to-end deep Siamese CNN architectures have been proposed for human re-identification with the objective of projecting the images of similar pairs (i.e. same identity) to be closer to each other and those of dissimilar pairs to be distant from each other. However, current networks extract fixed representations for each image regardless of other images which are paired with it and the comparison with other images is done only at the final level. In this setting, the network is at risk of failing to extract finer local patterns that may be essential to distinguish positive pairs from hard negative pairs. In this paper, we propose a gating function to selectively emphasize such fine common local patterns by comparing the mid-level features across pairs of images. This produces flexible representations for the same image according to the images they are paired with. We conduct experiments on the CUHK03, Market-1501 and VIPeR datasets and demonstrate improved performance compared to a baseline Siamese CNN architecture.
A Siamese Long Short-Term Memory Architecture for Human Re-Identification
Jul 28, 2016

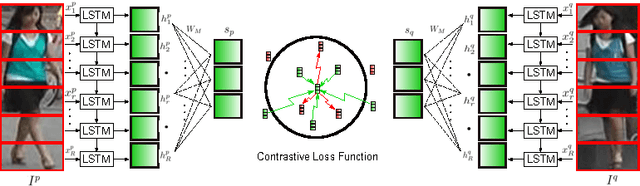
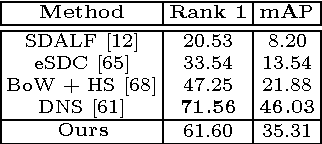
Matching pedestrians across multiple camera views known as human re-identification (re-identification) is a challenging problem in visual surveillance. In the existing works concentrating on feature extraction, representations are formed locally and independent of other regions. We present a novel siamese Long Short-Term Memory (LSTM) architecture that can process image regions sequentially and enhance the discriminative capability of local feature representation by leveraging contextual information. The feedback connections and internal gating mechanism of the LSTM cells enable our model to memorize the spatial dependencies and selectively propagate relevant contextual information through the network. We demonstrate improved performance compared to the baseline algorithm with no LSTM units and promising results compared to state-of-the-art methods on Market-1501, CUHK03 and VIPeR datasets. Visualization of the internal mechanism of LSTM cells shows meaningful patterns can be learned by our method.
Hierarchical Invariant Feature Learning with Marginalization for Person Re-Identification
Nov 30, 2015
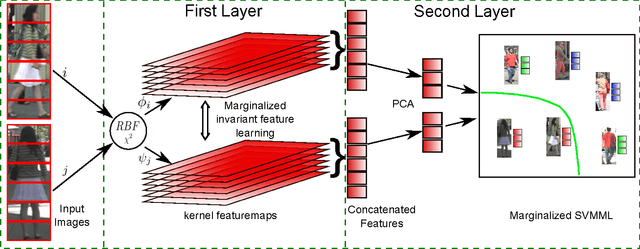


This paper addresses the problem of matching pedestrians across multiple camera views, known as person re-identification. Variations in lighting conditions, environment and pose changes across camera views make re-identification a challenging problem. Previous methods address these challenges by designing specific features or by learning a distance function. We propose a hierarchical feature learning framework that learns invariant representations from labeled image pairs. A mapping is learned such that the extracted features are invariant for images belonging to same individual across views. To learn robust representations and to achieve better generalization to unseen data, the system has to be trained with a large amount of data. Critically, most of the person re-identification datasets are small. Manually augmenting the dataset by partial corruption of input data introduces additional computational burden as it requires several training epochs to converge. We propose a hierarchical network which incorporates a marginalization technique that can reap the benefits of training on large datasets without explicit augmentation. We compare our approach with several baseline algorithms as well as popular linear and non-linear metric learning algorithms and demonstrate improved performance on challenging publicly available datasets, VIPeR, CUHK01, CAVIAR4REID and iLIDS. Our approach also achieves the stateof-the-art results on these datasets.
Learning Invariant Color Features for Person Re-Identification
Oct 09, 2014
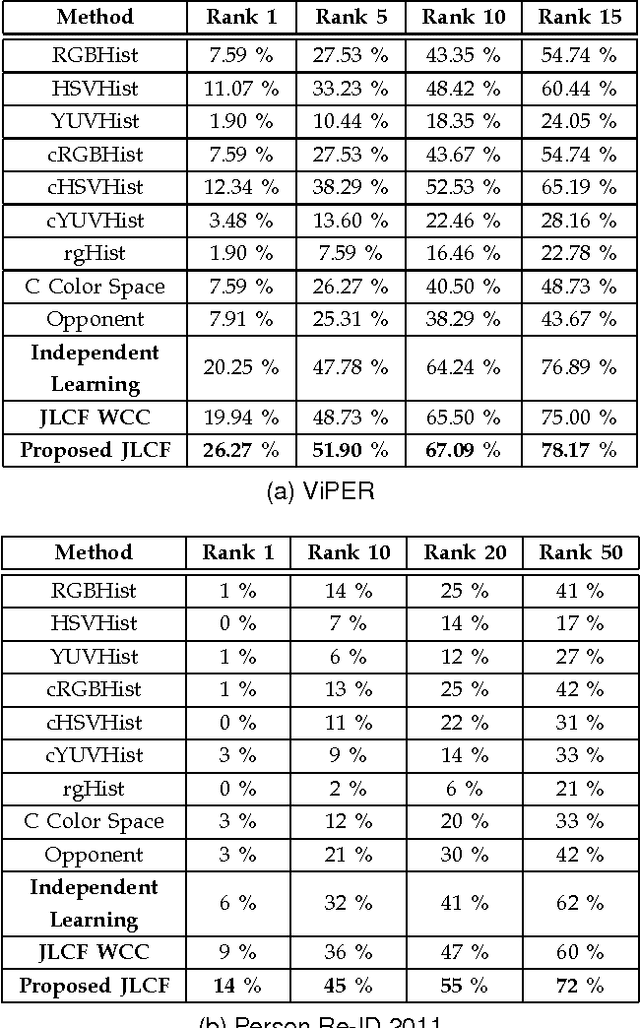
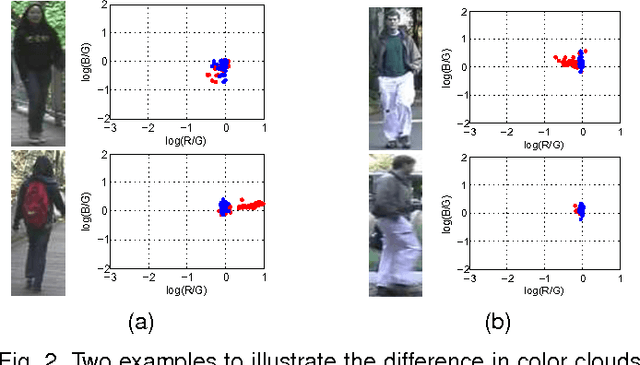
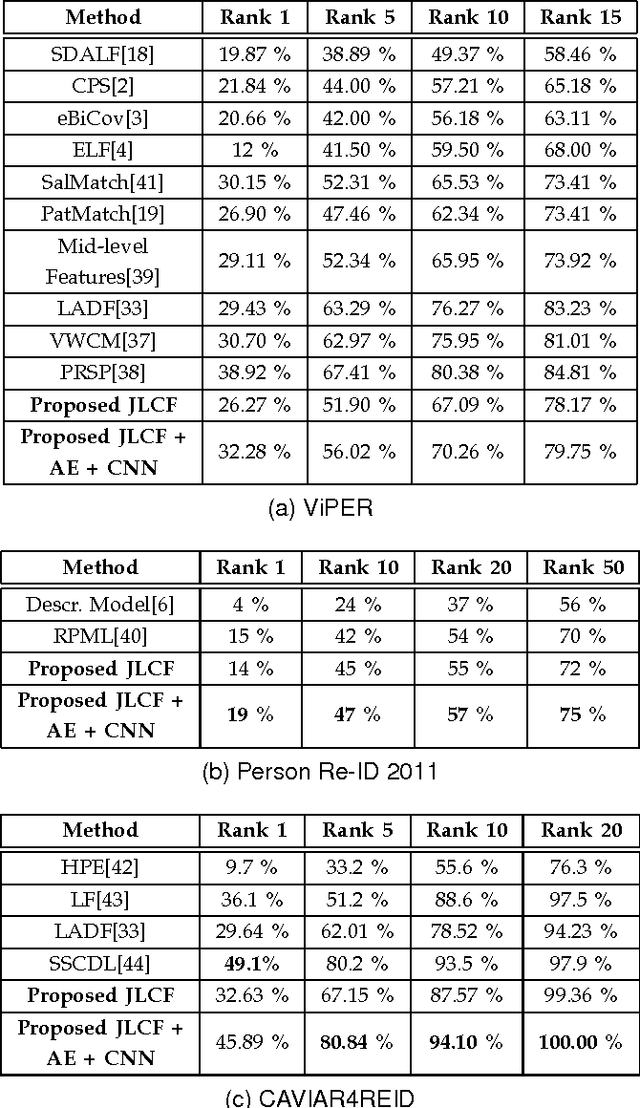
Matching people across multiple camera views known as person re-identification, is a challenging problem due to the change in visual appearance caused by varying lighting conditions. The perceived color of the subject appears to be different with respect to illumination. Previous works use color as it is or address these challenges by designing color spaces focusing on a specific cue. In this paper, we propose a data driven approach for learning color patterns from pixels sampled from images across two camera views. The intuition behind this work is that, even though pixel values of same color would be different across views, they should be encoded with the same values. We model color feature generation as a learning problem by jointly learning a linear transformation and a dictionary to encode pixel values. We also analyze different photometric invariant color spaces. Using color as the only cue, we compare our approach with all the photometric invariant color spaces and show superior performance over all of them. Combining with other learned low-level and high-level features, we obtain promising results in ViPER, Person Re-ID 2011 and CAVIAR4REID datasets.