 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration-Aware Margin Loss: Pushing the Accuracy-Calibration Consistency Pareto Frontier for Deep Metric Learning
Jul 08, 2023



The ability to use the same distance threshold across different test classes / distributions is highly desired for a frictionless deployment of commercial image retrieval systems. However, state-of-the-art deep metric learning losses often result in highly varied intra-class and inter-class embedding structures, making threshold calibration a non-trivial process in practice. In this paper, we propose a novel metric named Operating-Point-Incosistency-Score (OPIS) that measures the variance in the operating characteristics across different classes in a target calibration range, and demonstrate that high accuracy of a metric learning embedding model does not guarantee calibration consistency for both seen and unseen classes. We find that, in the high-accuracy regime, there exists a Pareto frontier where accuracy improvement comes at the cost of calibration consistency. To address this, we develop a novel regularization, named Calibration-Aware Margin (CAM) loss, to encourage uniformity in the representation structures across classes during training. Extensive experiments demonstrate CAM's effectiveness in improving calibration-consistency while retaining or even enhancing accuracy, outperforming state-of-the-art deep metric learning methods.
Scale-Aware Attention Network for Crowd Counting
Jan 17, 2019
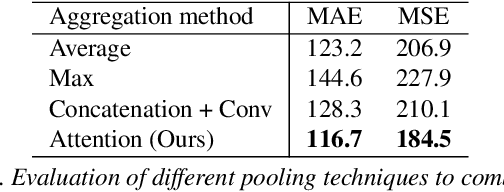
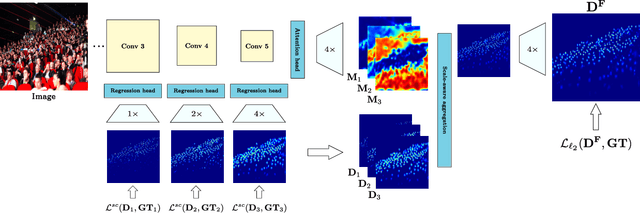
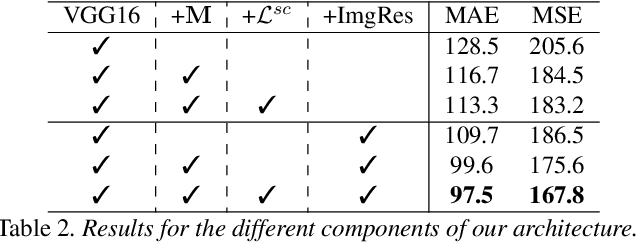
In crowd counting datasets, people appear at different scales, depending on their distance to the camera. To address this issue, we propose a novel multi-branch scale-aware attention network that exploits the hierarchical structure of convolutional neural networks and generates, in a single forward pass, multi-scale density predictions from different layers of the architecture. To aggregate these maps into our final prediction, we present a new soft attention mechanism that learns a set of gating masks. Furthermore, we introduce a scale-aware loss function to regularize the training of different branches and guide them to specialize on a particular scale. As this new training requires ground-truth annotations for the size of each head, we also propose a simple, yet effective technique to estimate it automatically. Finally, we present an ablation study on each of these components and compare our approach against the literature on 4 crowd counting datasets: UCF-QNRF, ShanghaiTech A & B and UCF_CC_50. Without bells and whistles, our approach achieves state-of-the-art on all these datasets. We observe a remarkable improvement on the UCF-QNRF (25%) and a significant one on the others (around 10%).