 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech representation learning: Learning bidirectional encoders with single-view, multi-view, and multi-task methods
Jul 25, 2023This thesis focuses on representation learning for sequence data over time or space, aiming to improve downstream sequence prediction tasks by using the learned representations. Supervised learning has been the most dominant approach for training deep neural networks for learning good sequential representations. However, one limiting factor to scale supervised learning is the lack of enough annotated data. Motivated by this challenge, it is natural to explore representation learning methods that can utilize large amounts of unlabeled and weakly labeled data, as well as an additional data modality. I describe my broad study of representation learning for speech data. Unlike most other works that focus on a single learning setting, this thesis studies multiple settings: supervised learning with auxiliary losses, unsupervised learning, semi-supervised learning, and multi-view learning. Besides different learning problems, I also explore multiple approaches for representation learning. Though I focus on speech data, the methods described in this thesis can also be applied to other domains. Overall, the field of representation learning is developing rapidly. State-of-the-art results on speech related tasks are typically based on Transformers pre-trained with large-scale self-supervised learning, which aims to learn generic representations that can benefit multiple downstream tasks. Since 2020, large-scale pre-training has been the de facto choice to achieve good performance. This delayed thesis does not attempt to summarize and compare with the latest results on speech representation learning; instead, it presents a unique study on speech representation learning before the Transformer era, that covers multiple learning settings. Some of the findings in this thesis can still be useful today.
Calibration-Aware Margin Loss: Pushing the Accuracy-Calibration Consistency Pareto Frontier for Deep Metric Learning
Jul 08, 2023



The ability to use the same distance threshold across different test classes / distributions is highly desired for a frictionless deployment of commercial image retrieval systems. However, state-of-the-art deep metric learning losses often result in highly varied intra-class and inter-class embedding structures, making threshold calibration a non-trivial process in practice. In this paper, we propose a novel metric named Operating-Point-Incosistency-Score (OPIS) that measures the variance in the operating characteristics across different classes in a target calibration range, and demonstrate that high accuracy of a metric learning embedding model does not guarantee calibration consistency for both seen and unseen classes. We find that, in the high-accuracy regime, there exists a Pareto frontier where accuracy improvement comes at the cost of calibration consistency. To address this, we develop a novel regularization, named Calibration-Aware Margin (CAM) loss, to encourage uniformity in the representation structures across classes during training. Extensive experiments demonstrate CAM's effectiveness in improving calibration-consistency while retaining or even enhancing accuracy, outperforming state-of-the-art deep metric learning methods.
On-Device Constrained Self-Supervised Speech Representation Learning for Keyword Spotting via Knowledge Distillation
Jul 06, 2023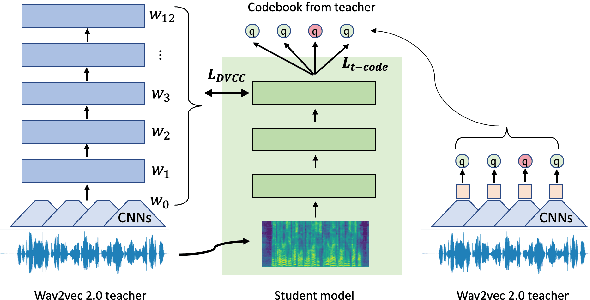

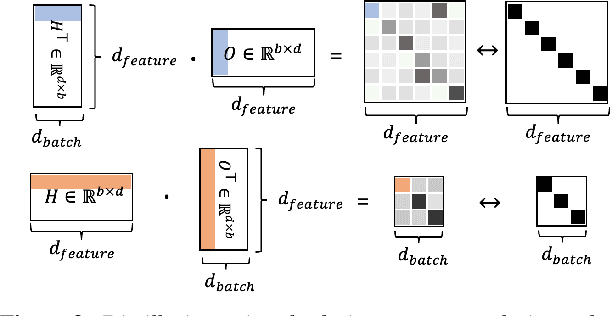
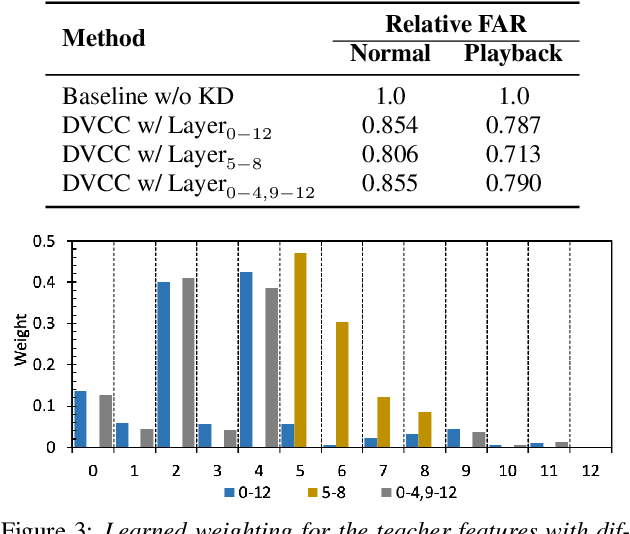
Large self-supervised models are effective feature extractors, but their application is challenging under on-device budget constraints and biased dataset collection, especially in keyword spotting. To address this, we proposed a knowledge distillation-based self-supervised speech representation learning (S3RL) architecture for on-device keyword spotting. Our approach used a teacher-student framework to transfer knowledge from a larger, more complex model to a smaller, light-weight model using dual-view cross-correlation distillation and the teacher's codebook as learning objectives. We evaluated our model's performance on an Alexa keyword spotting detection task using a 16.6k-hour in-house dataset. Our technique showed exceptional performance in normal and noisy conditions, demonstrating the efficacy of knowledge distillation methods in constructing self-supervised models for keyword spotting tasks while working within on-device resource constraints.
Learning for Open-World Calibration with Graph Neural Networks
May 19, 2023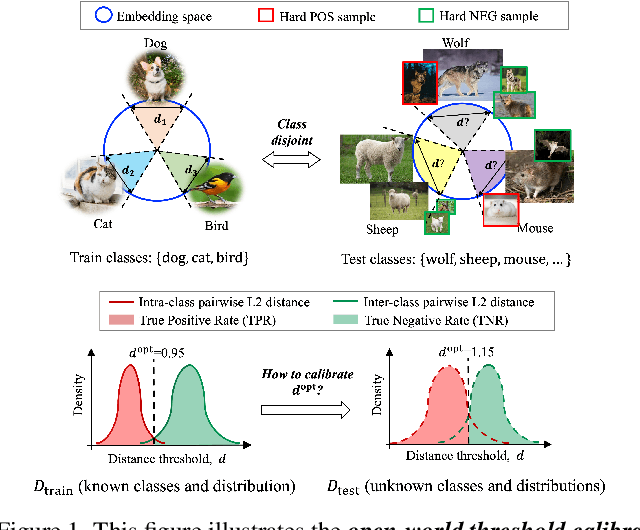
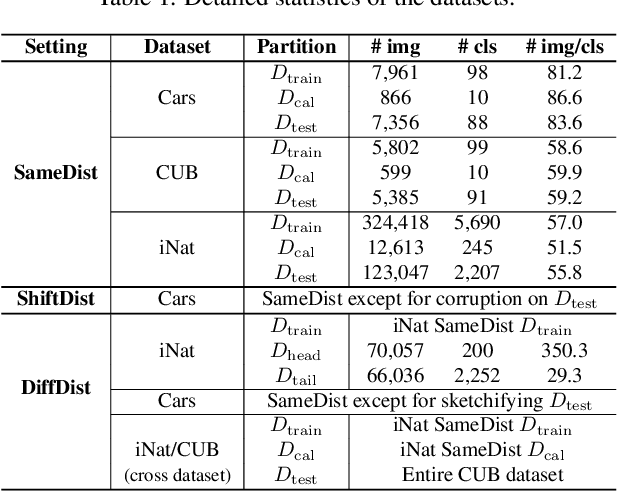
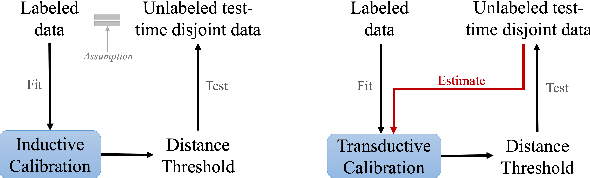

We tackle the problem of threshold calibration for open-world recognition by incorporating representation compactness measures into clustering. Unlike the open-set recognition which focuses on discovering and rejecting the unknown, open-world recognition learns robust representations that are generalizable to disjoint unknown classes at test time. Our proposed method is based on two key observations: (i) representation structures among neighbouring images in high dimensional visual embedding spaces have strong self-similarity which can be leveraged to encourage transferability to the open world, (ii) intra-class embedding structures can be modeled with the marginalized von Mises-Fisher (vMF) probability, whose correlation with the true positive rate is dataset-invariant. Motivated by these, we design a unified framework centered around a graph neural network (GNN) to jointly predict the pseudo-labels and the vMF concentrations which indicate the representation compactness. These predictions can be converted into statistical estimations for recognition accuracy, allowing more robust calibration of the distance threshold to achieve target utility for the open-world classes. Results on a variety of visual recognition benchmarks demonstrate the superiority of our method over traditional posthoc calibration methods for the open world, especially under distribution shift.
Weight-sharing Supernet for Searching Specialized Acoustic Event Classification Networks Across Device Constraints
Mar 18, 2023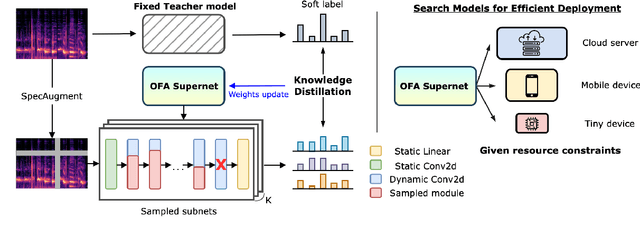



Acoustic Event Classification (AEC) has been widely used in devices such as smart speakers and mobile phones for home safety or accessibility support. As AEC models run on more and more devices with diverse computation resource constraints, it became increasingly expensive to develop models that are tuned to achieve optimal accuracy/computation trade-off for each given computation resource constraint. In this paper, we introduce a Once-For-All (OFA) Neural Architecture Search (NAS) framework for AEC. Specifically, we first train a weight-sharing supernet that supports different model architectures, followed by automatically searching for a model given specific computational resource constraints. Our experimental results showed that by just training once, the resulting model from NAS significantly outperforms both models trained individually from scratch and knowledge distillation (25.4% and 7.3% relative improvement). We also found that the benefit of weight-sharing supernet training of ultra-small models comes not only from searching but from optimization.
Federated Self-Supervised Learning for Acoustic Event Classification
Mar 22, 2022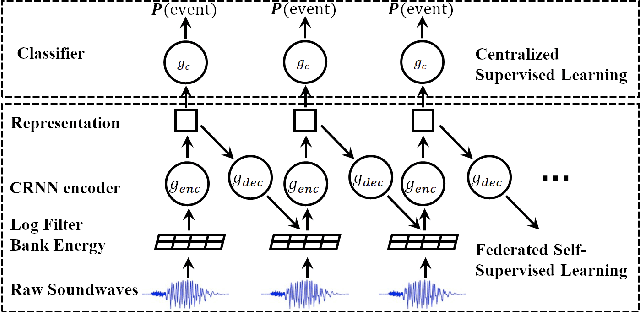

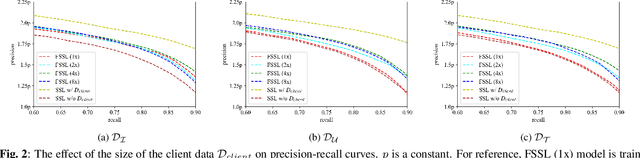
Standard acoustic event classification (AEC) solutions require large-scale collection of data from client devices for model optimization. Federated learning (FL) is a compelling framework that decouples data collection and model training to enhance customer privacy. In this work, we investigate the feasibility of applying FL to improve AEC performance while no customer data can be directly uploaded to the server. We assume no pseudo labels can be inferred from on-device user inputs, aligning with the typical use cases of AEC. We adapt self-supervised learning to the FL framework for on-device continual learning of representations, and it results in improved performance of the downstream AEC classifiers without labeled/pseudo-labeled data available. Compared to the baseline w/o FL, the proposed method improves precision up to 20.3\% relatively while maintaining the recall. Our work differs from prior work in FL in that our approach does not require user-generated learning targets, and the data we use is collected from our Beta program and is de-identified, to maximally simulate the production settings.
Multi-Task Self-Supervised Pre-Training for Music Classification
Feb 05, 2021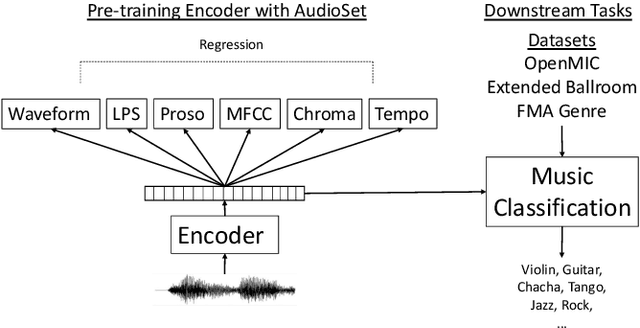
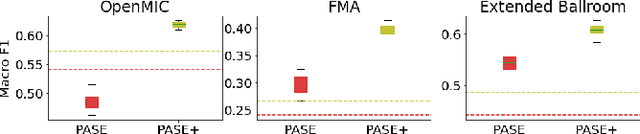
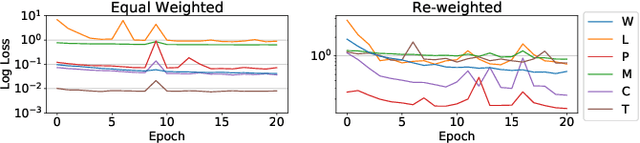
Deep learning is very data hungry, and supervised learning especially requires massive labeled data to work well. Machine listening research often suffers from limited labeled data problem, as human annotations are costly to acquire, and annotations for audio are time consuming and less intuitive. Besides, models learned from labeled dataset often embed biases specific to that particular dataset. Therefore, unsupervised learning techniques become popular approaches in solving machine listening problems. Particularly, a self-supervised learning technique utilizing reconstructions of multiple hand-crafted audio features has shown promising results when it is applied to speech domain such as emotion recognition and automatic speech recognition (ASR). In this paper, we apply self-supervised and multi-task learning methods for pre-training music encoders, and explore various design choices including encoder architectures, weighting mechanisms to combine losses from multiple tasks, and worker selections of pretext tasks. We investigate how these design choices interact with various downstream music classification tasks. We find that using various music specific workers altogether with weighting mechanisms to balance the losses during pre-training helps improve and generalize to the downstream tasks.
Towards Disentangled Representations for Human Retargeting by Multi-view Learning
Dec 12, 2019
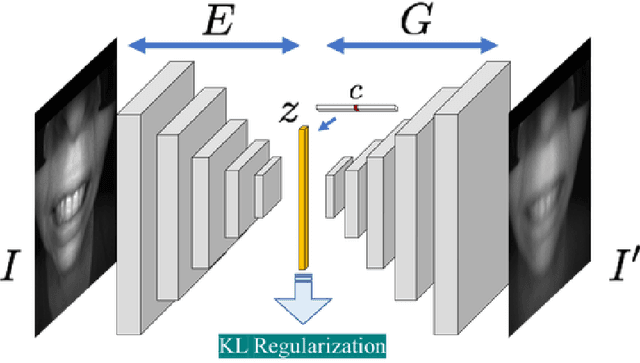

We study the problem of learning disentangled representations for data across multiple domains and its applications in human retargeting. Our goal is to map an input image to an identity-invariant latent representation that captures intrinsic factors such as expressions and poses. To this end, we present a novel multi-view learning approach that leverages various data sources such as images, keypoints, and poses. Our model consists of multiple id-conditioned VAEs for different views of the data. During training, we encourage the latent embeddings to be consistent across these views. Our observation is that auxiliary data like keypoints and poses contain critical, id-agnostic semantic information, and it is easier to train a disentangling CVAE on these simpler views to separate such semantics from other id-specific attributes. We show that training multi-view CVAEs and encourage latent-consistency guides the image encoding to preserve the semantics of expressions and poses, leading to improved disentangled representations and better human retargeting results.
Dependency-aware Attention Control for Unconstrained Face Recognition with Image Sets
Jul 05, 2019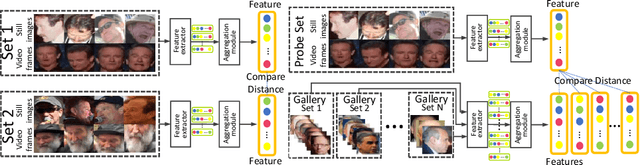
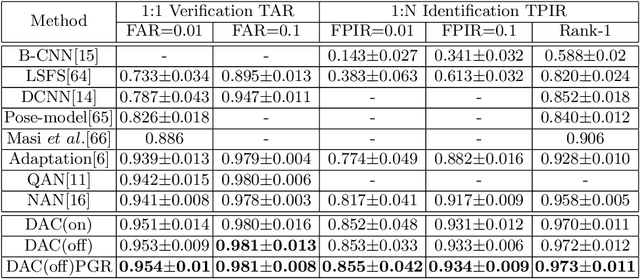

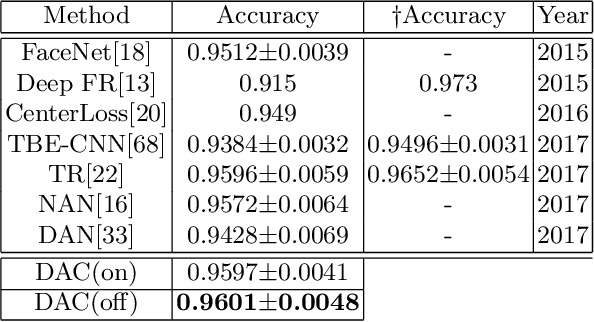
This paper targets the problem of image set-based face verification and identification. Unlike traditional single media (an image or video) setting, we encounter a set of heterogeneous contents containing orderless images and videos. The importance of each image is usually considered either equal or based on their independent quality assessment. How to model the relationship of orderless images within a set remains a challenge. We address this problem by formulating it as a Markov Decision Process (MDP) in the latent space. Specifically, we first present a dependency-aware attention control (DAC) network, which resorts to actor-critic reinforcement learning for sequential attention decision of each image embedding to fully exploit the rich correlation cues among the unordered images. Moreover, we introduce its sample-efficient variant with off-policy experience replay to speed up the learning process. The pose-guided representation scheme can further boost the performance at the extremes of the pose variation.
Variational Sequential Labelers for Semi-Supervised Learning
Jun 23, 2019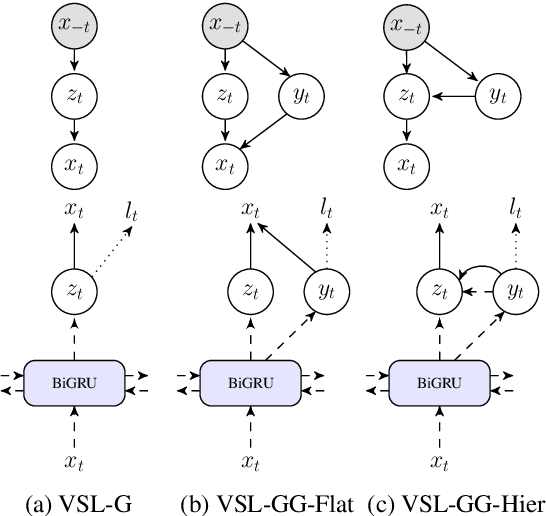


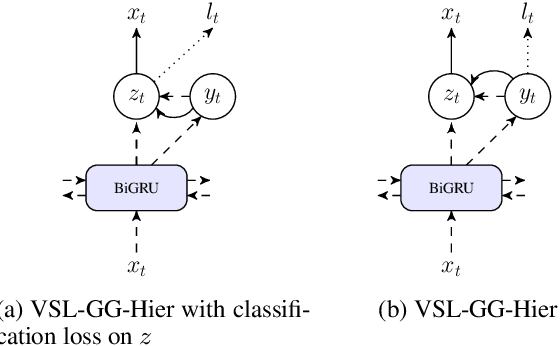
We introduce a family of multitask variational methods for semi-supervised sequence labeling. Our model family consists of a latent-variable generative model and a discriminative labeler. The generative models use latent variables to define the conditional probability of a word given its context, drawing inspiration from word prediction objectives commonly used in learning word embeddings. The labeler helps inject discriminative information into the latent space. We explore several latent variable configurations, including ones with hierarchical structure, which enables the model to account for both label-specific and word-specific information. Our models consistently outperform standard sequential baselines on 8 sequence labeling datasets, and improve further with unlabeled data.