 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos 3: Omnimodal World Models for Physical AI
Jun 01, 2026We introduce Cosmos 3, a family of omnimodal world models designed to jointly process and generate language, image, video, audio, and action sequences within a unified mixture-of-transformers architecture. By supporting highly flexible input-output configurations, Cosmos 3 seamlessly unifies critical modalities for Physical AI -- effectively subsuming vision-language models, video generators, world simulators, and world-action models into a single framework. Our evaluation demonstrates that Cosmos 3 establishes a new state-of-the-art across a diverse suite of understanding and generation tasks, demonstrating omnimodal world models as scalable, general-purpose backbones for embodied agents. Our post-trained Cosmos 3 models were ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis, and the best policy model by RoboArena at the time the technical report was written. To accelerate open research and deployment in Physical AI, we make our code, model checkpoints, curated synthetic datasets, and evaluation benchmark available under the Linux Foundation's OpenMDW-1.1 https://openmdw.ai/license/1-1/ License at https://github.com/nvidia/cosmos}{github.com/nvidia/cosmos and https://huggingface.co/collections/nvidia/cosmos3 . The project website is available at https://research.nvidia.com/labs/cosmos-lab/cosmos3 .
VideoSAM: Open-World Video Segmentation
Oct 11, 2024



Video segmentation is essential for advancing robotics and autonomous driving, particularly in open-world settings where continuous perception and object association across video frames are critical. While the Segment Anything Model (SAM) has excelled in static image segmentation, extending its capabilities to video segmentation poses significant challenges. We tackle two major hurdles: a) SAM's embedding limitations in associating objects across frames, and b) granularity inconsistencies in object segmentation. To this end, we introduce VideoSAM, an end-to-end framework designed to address these challenges by improving object tracking and segmentation consistency in dynamic environments. VideoSAM integrates an agglomerated backbone, RADIO, enabling object association through similarity metrics and introduces Cycle-ack-Pairs Propagation with a memory mechanism for stable object tracking. Additionally, we incorporate an autoregressive object-token mechanism within the SAM decoder to maintain consistent granularity across frames. Our method is extensively evaluated on the UVO and BURST benchmarks, and robotic videos from RoboTAP, demonstrating its effectiveness and robustness in real-world scenarios. All codes will be available.
Rethinking The Training And Evaluation of Rich-Context Layout-to-Image Generation
Sep 07, 2024Recent advancements in generative models have significantly enhanced their capacity for image generation, enabling a wide range of applications such as image editing, completion and video editing. A specialized area within generative modeling is layout-to-image (L2I) generation, where predefined layouts of objects guide the generative process. In this study, we introduce a novel regional cross-attention module tailored to enrich layout-to-image generation. This module notably improves the representation of layout regions, particularly in scenarios where existing methods struggle with highly complex and detailed textual descriptions. Moreover, while current open-vocabulary L2I methods are trained in an open-set setting, their evaluations often occur in closed-set environments. To bridge this gap, we propose two metrics to assess L2I performance in open-vocabulary scenarios. Additionally, we conduct a comprehensive user study to validate the consistency of these metrics with human preferences.
GQE: Generalized Query Expansion for Enhanced Text-Video Retrieval
Aug 14, 2024In the rapidly expanding domain of web video content, the task of text-video retrieval has become increasingly critical, bridging the semantic gap between textual queries and video data. This paper introduces a novel data-centric approach, Generalized Query Expansion (GQE), to address the inherent information imbalance between text and video, enhancing the effectiveness of text-video retrieval systems. Unlike traditional model-centric methods that focus on designing intricate cross-modal interaction mechanisms, GQE aims to expand the text queries associated with videos both during training and testing phases. By adaptively segmenting videos into short clips and employing zero-shot captioning, GQE enriches the training dataset with comprehensive scene descriptions, effectively bridging the data imbalance gap. Furthermore, during retrieval, GQE utilizes Large Language Models (LLM) to generate a diverse set of queries and a query selection module to filter these queries based on relevance and diversity, thus optimizing retrieval performance while reducing computational overhead. Our contributions include a detailed examination of the information imbalance challenge, a novel approach to query expansion in video-text datasets, and the introduction of a query selection strategy that enhances retrieval accuracy without increasing computational costs. GQE achieves state-of-the-art performance on several benchmarks, including MSR-VTT, MSVD, LSMDC, and VATEX, demonstrating the effectiveness of addressing text-video retrieval from a data-centric perspective.
Adaptive Slot Attention: Object Discovery with Dynamic Slot Number
Jun 13, 2024
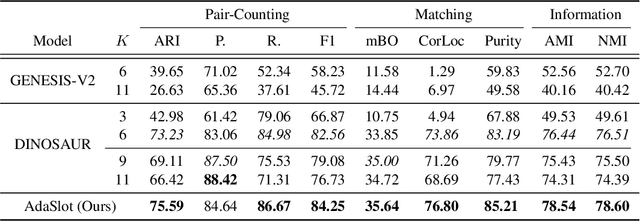

Object-centric learning (OCL) extracts the representation of objects with slots, offering an exceptional blend of flexibility and interpretability for abstracting low-level perceptual features. A widely adopted method within OCL is slot attention, which utilizes attention mechanisms to iteratively refine slot representations. However, a major drawback of most object-centric models, including slot attention, is their reliance on predefining the number of slots. This not only necessitates prior knowledge of the dataset but also overlooks the inherent variability in the number of objects present in each instance. To overcome this fundamental limitation, we present a novel complexity-aware object auto-encoder framework. Within this framework, we introduce an adaptive slot attention (AdaSlot) mechanism that dynamically determines the optimal number of slots based on the content of the data. This is achieved by proposing a discrete slot sampling module that is responsible for selecting an appropriate number of slots from a candidate list. Furthermore, we introduce a masked slot decoder that suppresses unselected slots during the decoding process. Our framework, tested extensively on object discovery tasks with various datasets, shows performance matching or exceeding top fixed-slot models. Moreover, our analysis substantiates that our method exhibits the capability to dynamically adapt the slot number according to each instance's complexity, offering the potential for further exploration in slot attention research. Project will be available at https://kfan21.github.io/AdaSlot/
Hallucination of Multimodal Large Language Models: A Survey
Apr 29, 2024



This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
Consistent Video-to-Video Transfer Using Synthetic Dataset
Nov 01, 2023



We introduce a novel and efficient approach for text-based video-to-video editing that eliminates the need for resource-intensive per-video-per-model finetuning. At the core of our approach is a synthetic paired video dataset tailored for video-to-video transfer tasks. Inspired by Instruct Pix2Pix's image transfer via editing instruction, we adapt this paradigm to the video domain. Extending the Prompt-to-Prompt to videos, we efficiently generate paired samples, each with an input video and its edited counterpart. Alongside this, we introduce the Long Video Sampling Correction during sampling, ensuring consistent long videos across batches. Our method surpasses current methods like Tune-A-Video, heralding substantial progress in text-based video-to-video editing and suggesting exciting avenues for further exploration and deployment.
Rethinking Amodal Video Segmentation from Learning Supervised Signals with Object-centric Representation
Sep 23, 2023



Video amodal segmentation is a particularly challenging task in computer vision, which requires to deduce the full shape of an object from the visible parts of it. Recently, some studies have achieved promising performance by using motion flow to integrate information across frames under a self-supervised setting. However, motion flow has a clear limitation by the two factors of moving cameras and object deformation. This paper presents a rethinking to previous works. We particularly leverage the supervised signals with object-centric representation in \textit{real-world scenarios}. The underlying idea is the supervision signal of the specific object and the features from different views can mutually benefit the deduction of the full mask in any specific frame. We thus propose an Efficient object-centric Representation amodal Segmentation (EoRaS). Specially, beyond solely relying on supervision signals, we design a translation module to project image features into the Bird's-Eye View (BEV), which introduces 3D information to improve current feature quality. Furthermore, we propose a multi-view fusion layer based temporal module which is equipped with a set of object slots and interacts with features from different views by attention mechanism to fulfill sufficient object representation completion. As a result, the full mask of the object can be decoded from image features updated by object slots. Extensive experiments on both real-world and synthetic benchmarks demonstrate the superiority of our proposed method, achieving state-of-the-art performance. Our code will be released at \url{https://github.com/kfan21/EoRaS}.
Unsupervised Open-Vocabulary Object Localization in Videos
Sep 18, 2023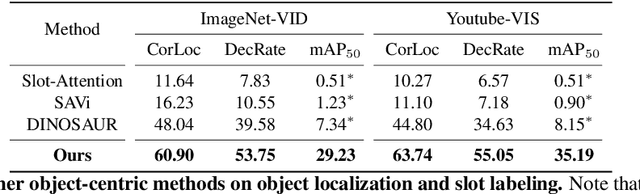
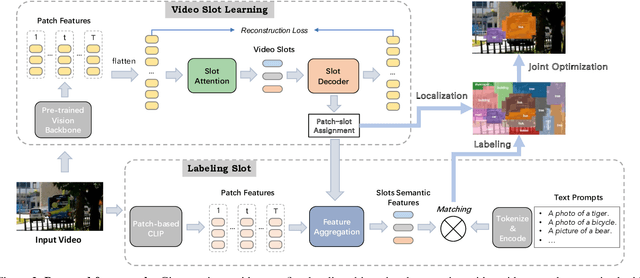
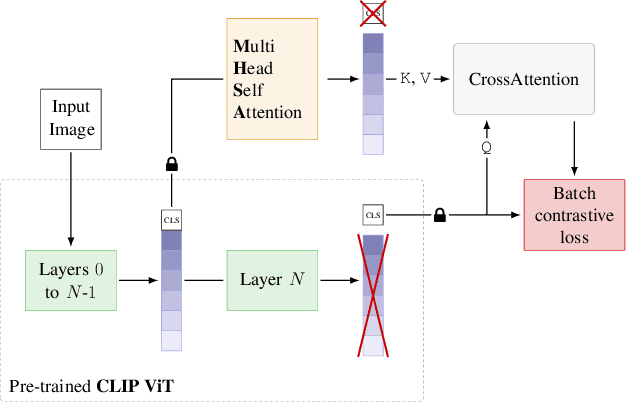
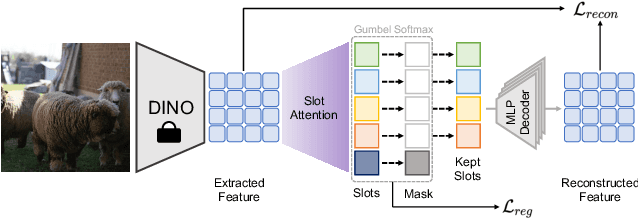
In this paper, we show that recent advances in video representation learning and pre-trained vision-language models allow for substantial improvements in self-supervised video object localization. We propose a method that first localizes objects in videos via a slot attention approach and then assigns text to the obtained slots. The latter is achieved by an unsupervised way to read localized semantic information from the pre-trained CLIP model. The resulting video object localization is entirely unsupervised apart from the implicit annotation contained in CLIP, and it is effectively the first unsupervised approach that yields good results on regular video benchmarks.
Object-Centric Multiple Object Tracking
Sep 05, 2023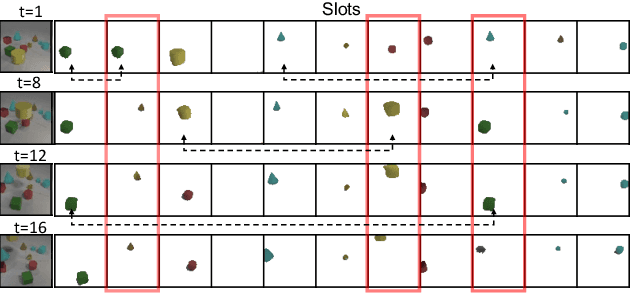
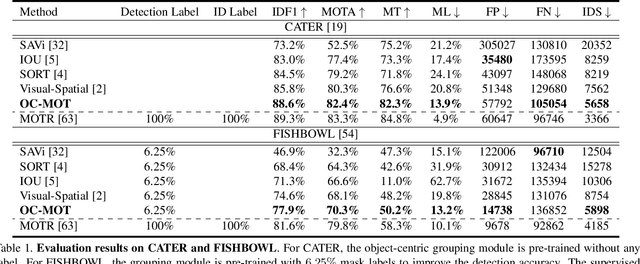
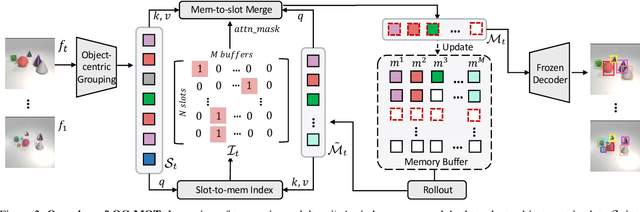
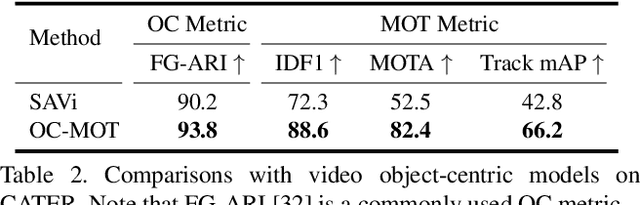
Unsupervised object-centric learning methods allow the partitioning of scenes into entities without additional localization information and are excellent candidates for reducing the annotation burden of multiple-object tracking (MOT) pipelines. Unfortunately, they lack two key properties: objects are often split into parts and are not consistently tracked over time. In fact, state-of-the-art models achieve pixel-level accuracy and temporal consistency by relying on supervised object detection with additional ID labels for the association through time. This paper proposes a video object-centric model for MOT. It consists of an index-merge module that adapts the object-centric slots into detection outputs and an object memory module that builds complete object prototypes to handle occlusions. Benefited from object-centric learning, we only require sparse detection labels (0%-6.25%) for object localization and feature binding. Relying on our self-supervised Expectation-Maximization-inspired loss for object association, our approach requires no ID labels. Our experiments significantly narrow the gap between the existing object-centric model and the fully supervised state-of-the-art and outperform several unsupervised trackers.