 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEMO: Human-like Crisp Edge Detection Using Masked Edge Prediction
Mar 21, 2026Learning-based edge detection models trained with cross-entropy loss often suffer from thick edge predictions, which deviate from the crisp, single-pixel annotations typically provided by humans. While previous approaches to achieving crisp edges have focused on designing specialized loss functions or modifying network architectures, we show that a carefully designed training and inference strategy alone is sufficient to achieve human-like edge quality. In this work, we introduce the Masked Edge Prediction MOdel (MEMO), which produces both accurate and crisp edges using only cross-entropy loss. We first construct a large-scale synthetic edge dataset to pre-train MEMO, enhancing its generalization ability. Subsequent fine-tuning on downstream datasets requires only a lightweight module comprising 1.2\% additional parameters. During training, MEMO learns to predict edges under varying ratios of input masking. A key insight guiding our inference is that thick edge predictions typically exhibit a confidence gradient: high in the center and lower toward the boundaries. Leveraging this, we propose a novel progressive prediction strategy that sequentially finalizes edge predictions in order of prediction confidence, resulting in thinner and more precise contours. Our method achieves visually appealing, post-processing-free, human-like edge maps and outperforms prior methods on crispness-aware evaluations.
Towards Generalized Multimodal Homography Estimation
Mar 04, 2026Supervised and unsupervised homography estimation methods depend on image pairs tailored to specific modalities to achieve high accuracy. However, their performance deteriorates substantially when applied to unseen modalities. To address this issue, we propose a training data synthesis method that generates unaligned image pairs with ground-truth offsets from a single input image. Our approach renders the image pairs with diverse textures and colors while preserving their structural information. These synthetic data empower the trained model to achieve greater robustness and improved generalization across various domains. Additionally, we design a network to fully leverage cross-scale information and decouple color information from feature representations, thus improving estimation accuracy. Extensive experiments show that our training data synthesis method improves generalization performance. The results also confirm the effectiveness of the proposed network.
Dense-Face: Personalized Face Generation Model via Dense Annotation Prediction
Dec 24, 2024The text-to-image (T2I) personalization diffusion model can generate images of the novel concept based on the user input text caption. However, existing T2I personalized methods either require test-time fine-tuning or fail to generate images that align well with the given text caption. In this work, we propose a new T2I personalization diffusion model, Dense-Face, which can generate face images with a consistent identity as the given reference subject and align well with the text caption. Specifically, we introduce a pose-controllable adapter for the high-fidelity image generation while maintaining the text-based editing ability of the pre-trained stable diffusion (SD). Additionally, we use internal features of the SD UNet to predict dense face annotations, enabling the proposed method to gain domain knowledge in face generation. Empirically, our method achieves state-of-the-art or competitive generation performance in image-text alignment, identity preservation, and pose control.
Rethinking The Training And Evaluation of Rich-Context Layout-to-Image Generation
Sep 07, 2024Recent advancements in generative models have significantly enhanced their capacity for image generation, enabling a wide range of applications such as image editing, completion and video editing. A specialized area within generative modeling is layout-to-image (L2I) generation, where predefined layouts of objects guide the generative process. In this study, we introduce a novel regional cross-attention module tailored to enrich layout-to-image generation. This module notably improves the representation of layout regions, particularly in scenarios where existing methods struggle with highly complex and detailed textual descriptions. Moreover, while current open-vocabulary L2I methods are trained in an open-set setting, their evaluations often occur in closed-set environments. To bridge this gap, we propose two metrics to assess L2I performance in open-vocabulary scenarios. Additionally, we conduct a comprehensive user study to validate the consistency of these metrics with human preferences.
Consistent Video-to-Video Transfer Using Synthetic Dataset
Nov 01, 2023



We introduce a novel and efficient approach for text-based video-to-video editing that eliminates the need for resource-intensive per-video-per-model finetuning. At the core of our approach is a synthetic paired video dataset tailored for video-to-video transfer tasks. Inspired by Instruct Pix2Pix's image transfer via editing instruction, we adapt this paradigm to the video domain. Extending the Prompt-to-Prompt to videos, we efficiently generate paired samples, each with an input video and its edited counterpart. Alongside this, we introduce the Long Video Sampling Correction during sampling, ensuring consistent long videos across batches. Our method surpasses current methods like Tune-A-Video, heralding substantial progress in text-based video-to-video editing and suggesting exciting avenues for further exploration and deployment.
LayoutDiffuse: Adapting Foundational Diffusion Models for Layout-to-Image Generation
Feb 16, 2023



Layout-to-image generation refers to the task of synthesizing photo-realistic images based on semantic layouts. In this paper, we propose LayoutDiffuse that adapts a foundational diffusion model pretrained on large-scale image or text-image datasets for layout-to-image generation. By adopting a novel neural adaptor based on layout attention and task-aware prompts, our method trains efficiently, generates images with both high perceptual quality and layout alignment, and needs less data. Experiments on three datasets show that our method significantly outperforms other 10 generative models based on GANs, VQ-VAE, and diffusion models.
Attack-Agnostic Adversarial Detection
Jun 01, 2022
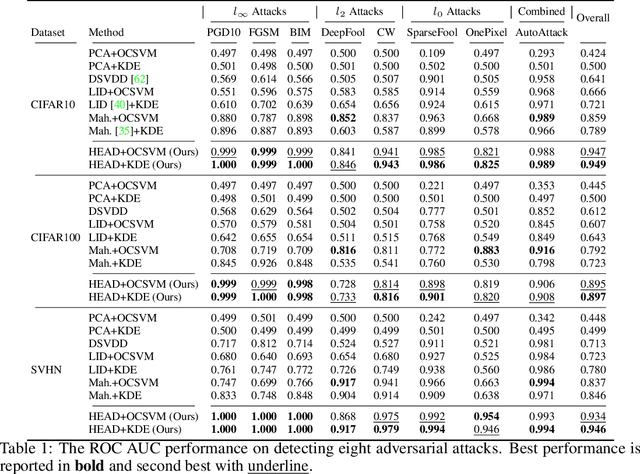
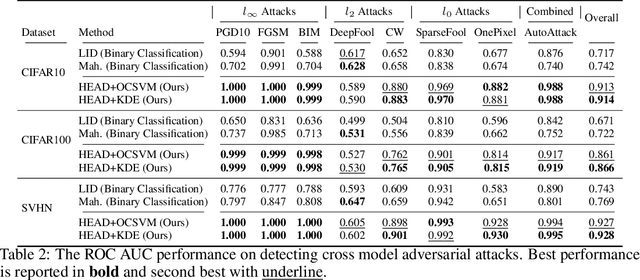

The growing number of adversarial attacks in recent years gives attackers an advantage over defenders, as defenders must train detectors after knowing the types of attacks, and many models need to be maintained to ensure good performance in detecting any upcoming attacks. We propose a way to end the tug-of-war between attackers and defenders by treating adversarial attack detection as an anomaly detection problem so that the detector is agnostic to the attack. We quantify the statistical deviation caused by adversarial perturbations in two aspects. The Least Significant Component Feature (LSCF) quantifies the deviation of adversarial examples from the statistics of benign samples and Hessian Feature (HF) reflects how adversarial examples distort the landscape of the model's optima by measuring the local loss curvature. Empirical results show that our method can achieve an overall ROC AUC of 94.9%, 89.7%, and 94.6% on CIFAR10, CIFAR100, and SVHN, respectively, and has comparable performance to adversarial detectors trained with adversarial examples on most of the attacks.
SIGN: Spatial-information Incorporated Generative Network for Generalized Zero-shot Semantic Segmentation
Aug 27, 2021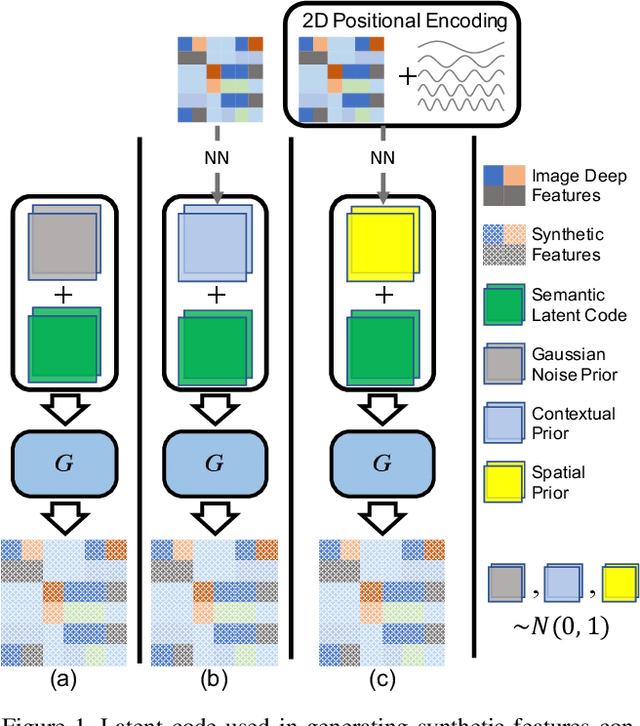
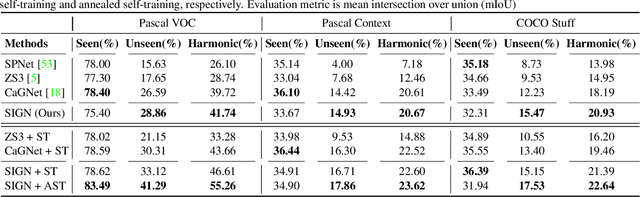
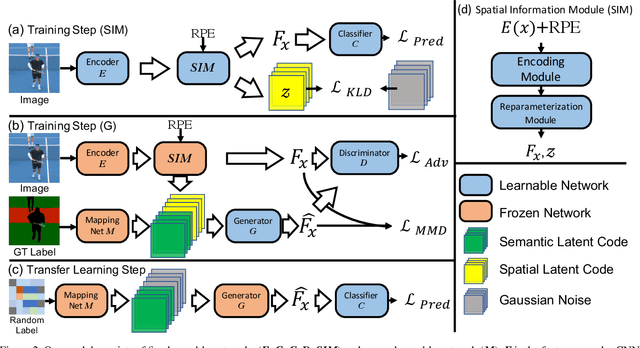
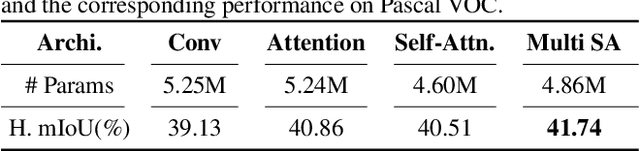
Unlike conventional zero-shot classification, zero-shot semantic segmentation predicts a class label at the pixel level instead of the image level. When solving zero-shot semantic segmentation problems, the need for pixel-level prediction with surrounding context motivates us to incorporate spatial information using positional encoding. We improve standard positional encoding by introducing the concept of Relative Positional Encoding, which integrates spatial information at the feature level and can handle arbitrary image sizes. Furthermore, while self-training is widely used in zero-shot semantic segmentation to generate pseudo-labels, we propose a new knowledge-distillation-inspired self-training strategy, namely Annealed Self-Training, which can automatically assign different importance to pseudo-labels to improve performance. We systematically study the proposed Relative Positional Encoding and Annealed Self-Training in a comprehensive experimental evaluation, and our empirical results confirm the effectiveness of our method on three benchmark datasets.
Style-Aware Normalized Loss for Improving Arbitrary Style Transfer
Apr 18, 2021
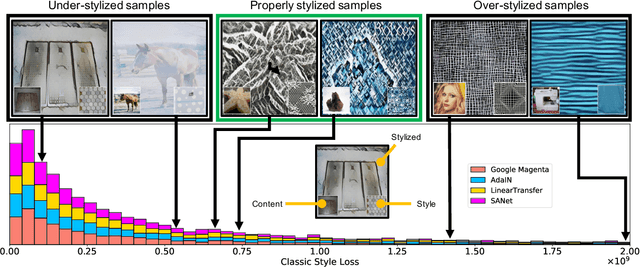
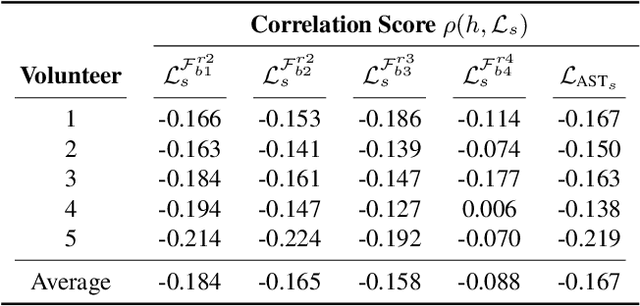
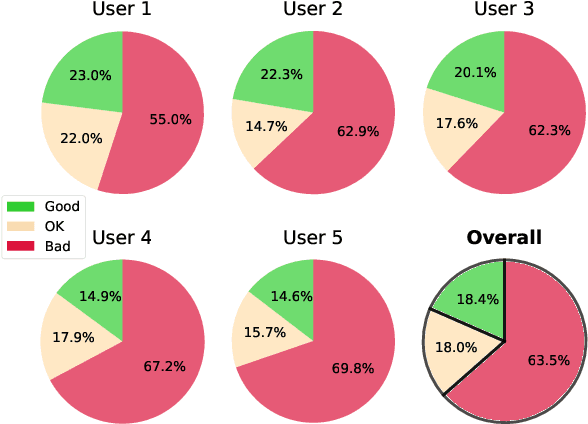
Neural Style Transfer (NST) has quickly evolved from single-style to infinite-style models, also known as Arbitrary Style Transfer (AST). Although appealing results have been widely reported in literature, our empirical studies on four well-known AST approaches (GoogleMagenta, AdaIN, LinearTransfer, and SANet) show that more than 50% of the time, AST stylized images are not acceptable to human users, typically due to under- or over-stylization. We systematically study the cause of this imbalanced style transferability (IST) and propose a simple yet effective solution to mitigate this issue. Our studies show that the IST issue is related to the conventional AST style loss, and reveal that the root cause is the equal weightage of training samples irrespective of the properties of their corresponding style images, which biases the model towards certain styles. Through investigation of the theoretical bounds of the AST style loss, we propose a new loss that largely overcomes IST. Theoretical analysis and experimental results validate the effectiveness of our loss, with over 80% relative improvement in style deception rate and 98% relatively higher preference in human evaluation.
Recurrent Convolutional Strategies for Face Manipulation Detection in Videos
May 16, 2019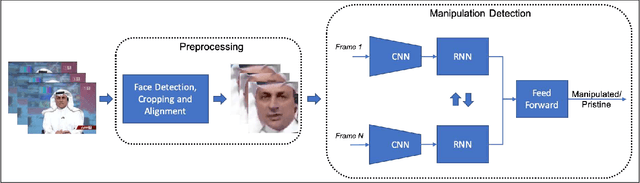
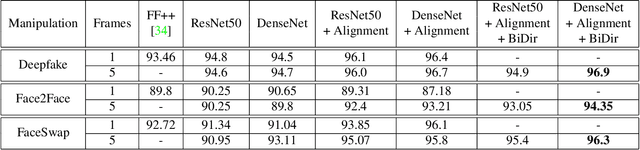
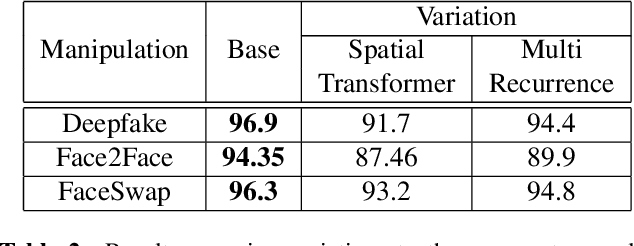
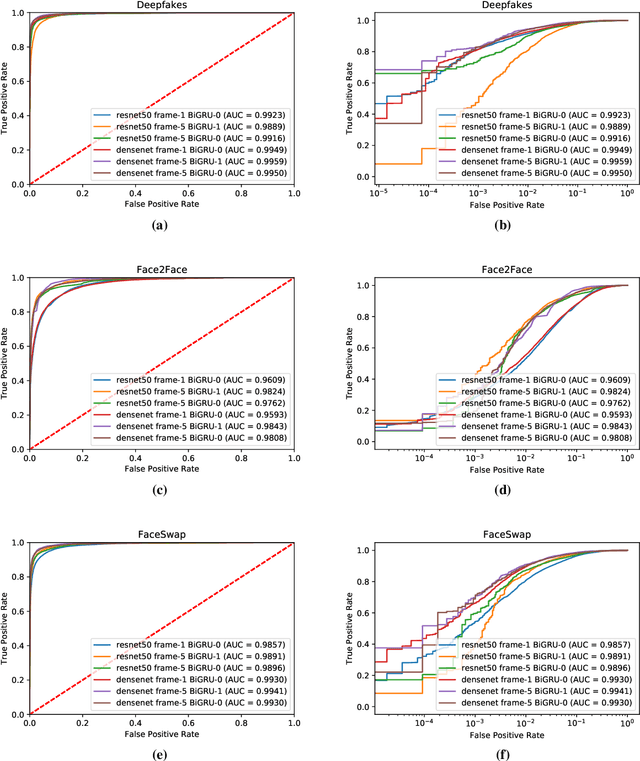
The spread of misinformation through synthetically generated yet realistic images and videos has become a significant problem, calling for robust manipulation detection methods. Despite the predominant effort of detecting face manipulation in still images, less attention has been paid to the identification of tampered faces in videos by taking advantage of the temporal information present in the stream. Recurrent convolutional models are a class of deep learning models which have proven effective at exploiting the temporal information from image streams across domains. We thereby distill the best strategy for combining variations in these models along with domain specific face preprocessing techniques through extensive experimentation to obtain state-of-the-art performance on publicly available video-based facial manipulation benchmarks. Specifically, we attempt to detect Deepfake, Face2Face and FaceSwap tampered faces in video streams. Evaluation is performed on the recently introduced FaceForensics++ dataset, improving the previous state-of-the-art by up to 4.55% in accuracy.