 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashionNTM: Multi-turn Fashion Image Retrieval via Cascaded Memory
Aug 20, 2023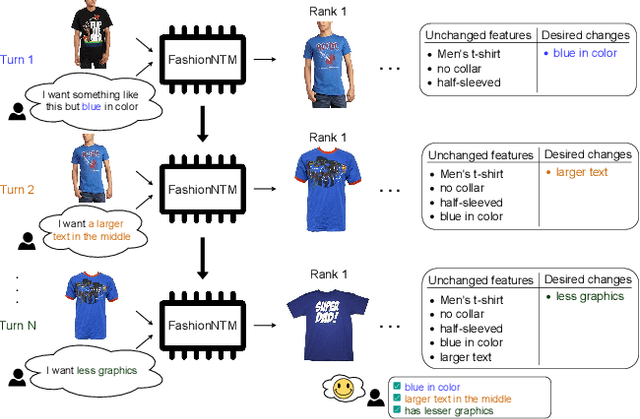
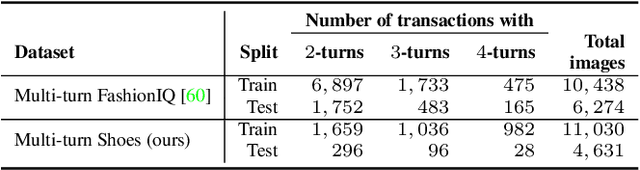
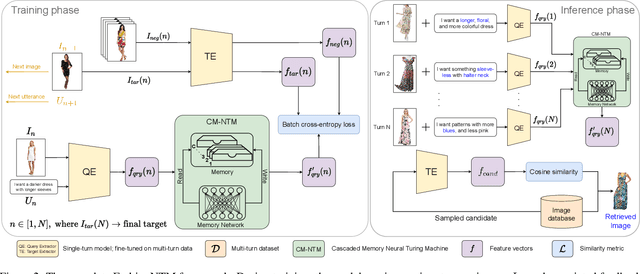
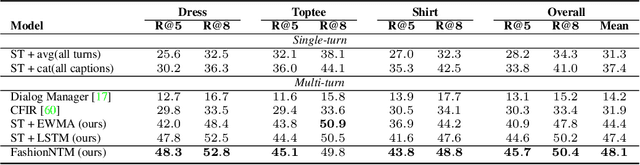
Multi-turn textual feedback-based fashion image retrieval focuses on a real-world setting, where users can iteratively provide information to refine retrieval results until they find an item that fits all their requirements. In this work, we present a novel memory-based method, called FashionNTM, for such a multi-turn system. Our framework incorporates a new Cascaded Memory Neural Turing Machine (CM-NTM) approach for implicit state management, thereby learning to integrate information across all past turns to retrieve new images, for a given turn. Unlike vanilla Neural Turing Machine (NTM), our CM-NTM operates on multiple inputs, which interact with their respective memories via individual read and write heads, to learn complex relationships. Extensive evaluation results show that our proposed method outperforms the previous state-of-the-art algorithm by 50.5%, on Multi-turn FashionIQ -- the only existing multi-turn fashion dataset currently, in addition to having a relative improvement of 12.6% on Multi-turn Shoes -- an extension of the single-turn Shoes dataset that we created in this work. Further analysis of the model in a real-world interactive setting demonstrates two important capabilities of our model -- memory retention across turns, and agnosticity to turn order for non-contradictory feedback. Finally, user study results show that images retrieved by FashionNTM were favored by 83.1% over other multi-turn models. Project page: https://sites.google.com/eng.ucsd.edu/fashionntm
Style-Aware Normalized Loss for Improving Arbitrary Style Transfer
Apr 18, 2021
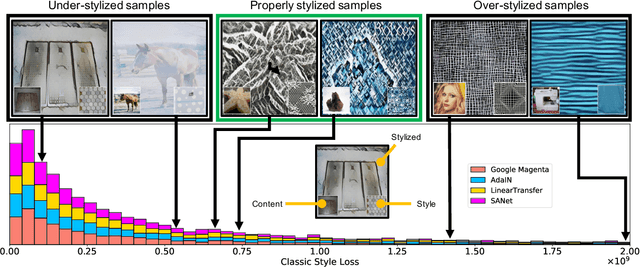
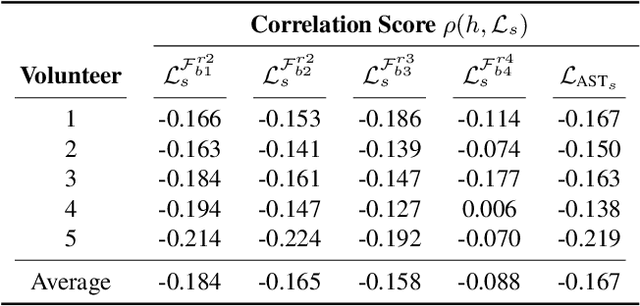
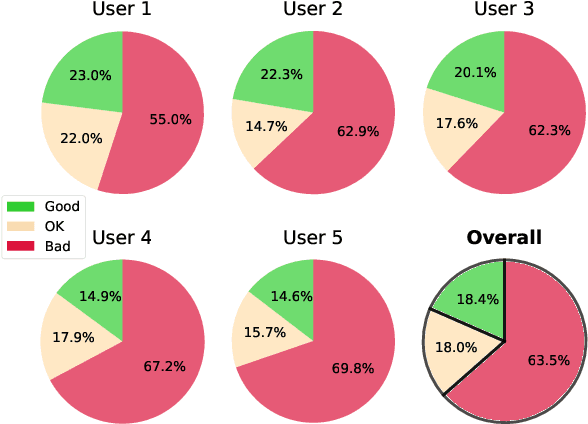
Neural Style Transfer (NST) has quickly evolved from single-style to infinite-style models, also known as Arbitrary Style Transfer (AST). Although appealing results have been widely reported in literature, our empirical studies on four well-known AST approaches (GoogleMagenta, AdaIN, LinearTransfer, and SANet) show that more than 50% of the time, AST stylized images are not acceptable to human users, typically due to under- or over-stylization. We systematically study the cause of this imbalanced style transferability (IST) and propose a simple yet effective solution to mitigate this issue. Our studies show that the IST issue is related to the conventional AST style loss, and reveal that the root cause is the equal weightage of training samples irrespective of the properties of their corresponding style images, which biases the model towards certain styles. Through investigation of the theoretical bounds of the AST style loss, we propose a new loss that largely overcomes IST. Theoretical analysis and experimental results validate the effectiveness of our loss, with over 80% relative improvement in style deception rate and 98% relatively higher preference in human evaluation.
Class-agnostic Object Detection
Nov 28, 2020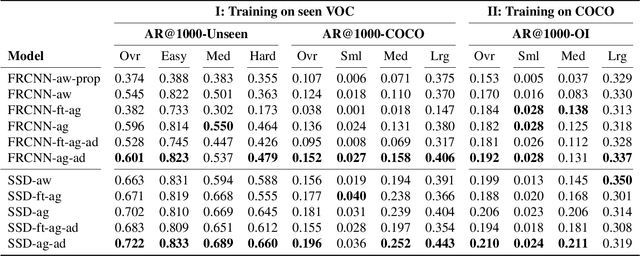
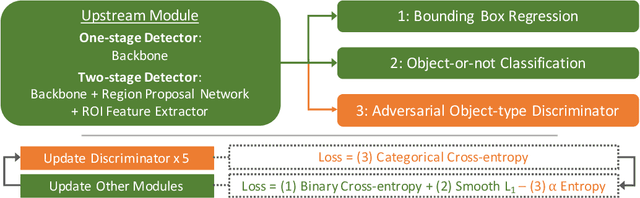
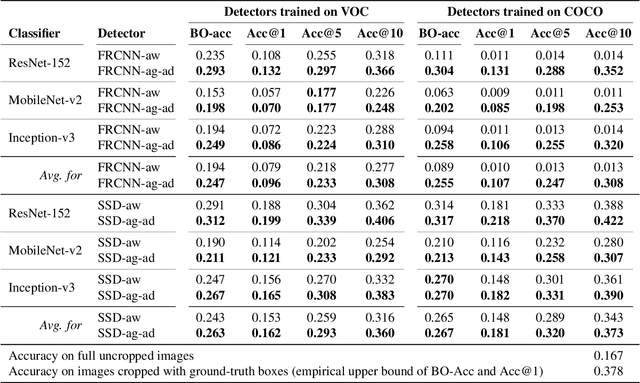
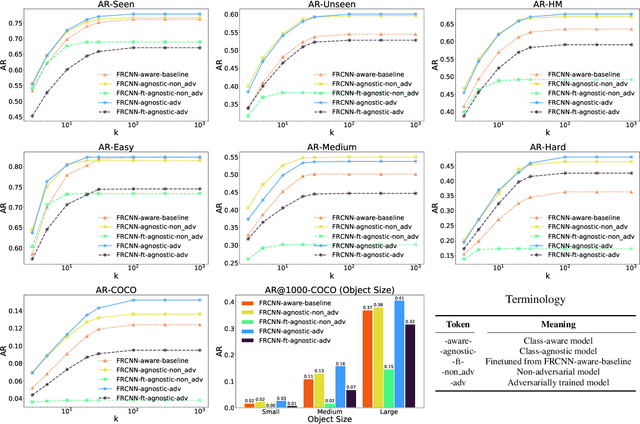
Object detection models perform well at localizing and classifying objects that they are shown during training. However, due to the difficulty and cost associated with creating and annotating detection datasets, trained models detect a limited number of object types with unknown objects treated as background content. This hinders the adoption of conventional detectors in real-world applications like large-scale object matching, visual grounding, visual relation prediction, obstacle detection (where it is more important to determine the presence and location of objects than to find specific types), etc. We propose class-agnostic object detection as a new problem that focuses on detecting objects irrespective of their object-classes. Specifically, the goal is to predict bounding boxes for all objects in an image but not their object-classes. The predicted boxes can then be consumed by another system to perform application-specific classification, retrieval, etc. We propose training and evaluation protocols for benchmarking class-agnostic detectors to advance future research in this domain. Finally, we propose (1) baseline methods and (2) a new adversarial learning framework for class-agnostic detection that forces the model to exclude class-specific information from features used for predictions. Experimental results show that adversarial learning improves class-agnostic detection efficacy.
MEG: Multi-Evidence GNN for Multimodal Semantic Forensics
Nov 23, 2020
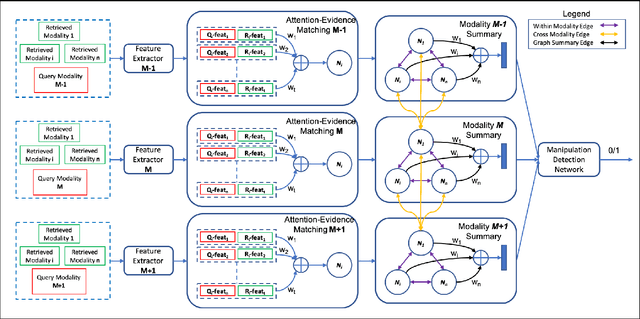


Fake news often involves semantic manipulations across modalities such as image, text, location etc and requires the development of multimodal semantic forensics for its detection. Recent research has centered the problem around images, calling it image repurposing -- where a digitally unmanipulated image is semantically misrepresented by means of its accompanying multimodal metadata such as captions, location, etc. The image and metadata together comprise a multimedia package. The problem setup requires algorithms to perform multimodal semantic forensics to authenticate a query multimedia package using a reference dataset of potentially related packages as evidences. Existing methods are limited to using a single evidence (retrieved package), which ignores potential performance improvement from the use of multiple evidences. In this work, we introduce a novel graph neural network based model for multimodal semantic forensics, which effectively utilizes multiple retrieved packages as evidences and is scalable with the number of evidences. We compare the scalability and performance of our model against existing methods. Experimental results show that the proposed model outperforms existing state-of-the-art algorithms with an error reduction of up to 25%.
Discovery and Separation of Features for Invariant Representation Learning
Dec 02, 2019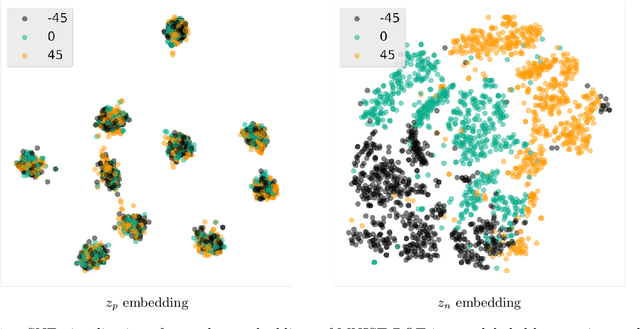


Supervised machine learning models often associate irrelevant nuisance factors with the prediction target, which hurts generalization. We propose a framework for training robust neural networks that induces invariance to nuisances through learning to discover and separate predictive and nuisance factors of data. We present an information theoretic formulation of our approach, from which we derive training objectives and its connections with previous methods. Empirical results on a wide array of datasets show that the proposed framework achieves state-of-the-art performance, without requiring nuisance annotations during training.
Invariant Representations through Adversarial Forgetting
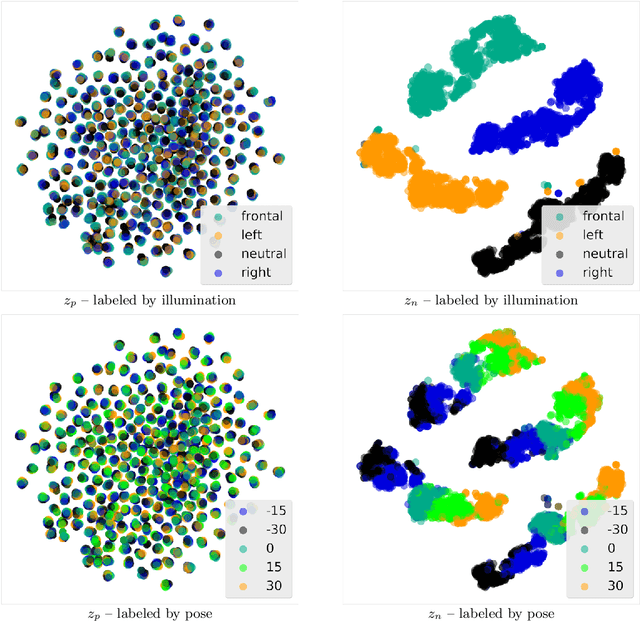
Nov 20, 2019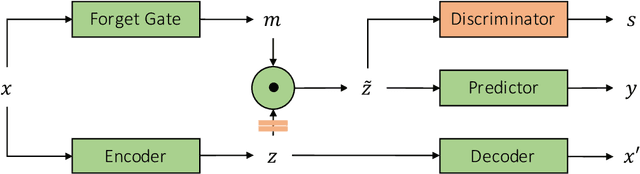

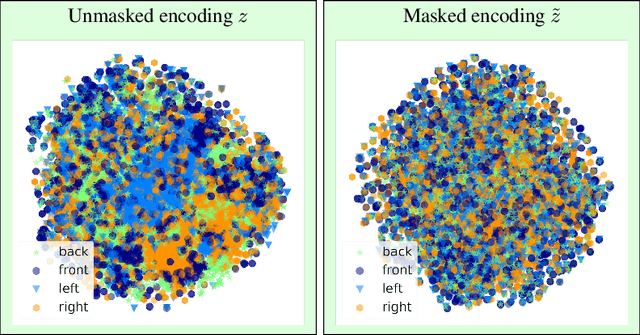
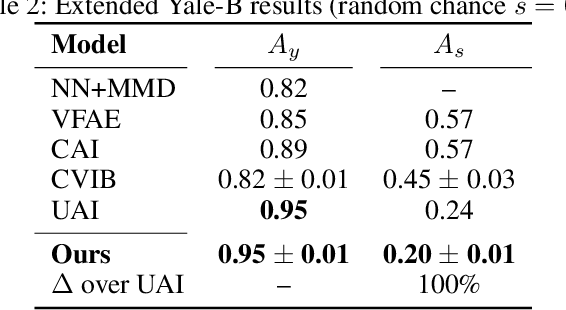
We propose a novel approach to achieving invariance for deep neural networks in the form of inducing amnesia to unwanted factors of data through a new adversarial forgetting mechanism. We show that the forgetting mechanism serves as an information-bottleneck, which is manipulated by the adversarial training to learn invariance to unwanted factors. Empirical results show that the proposed framework achieves state-of-the-art performance at learning invariance in both nuisance and bias settings on a diverse collection of datasets and tasks.
NIESR: Nuisance Invariant End-to-end Speech Recognition
Jul 07, 2019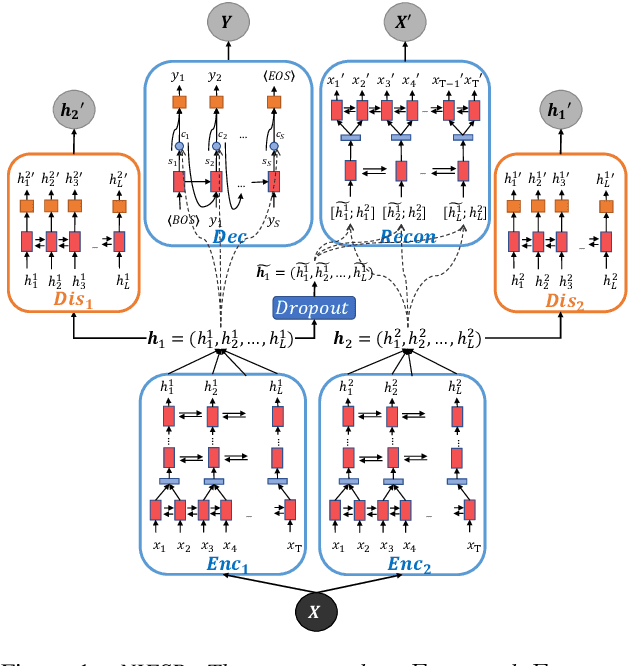

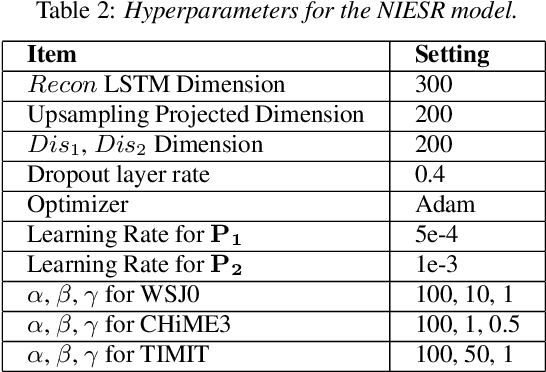
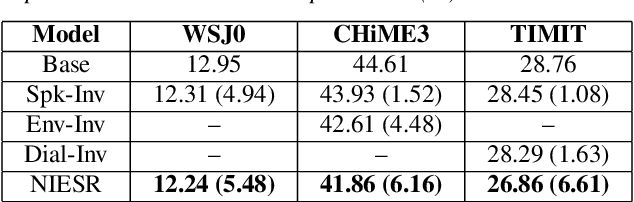
Deep neural network models for speech recognition have achieved great success recently, but they can learn incorrect associations between the target and nuisance factors of speech (e.g., speaker identities, background noise, etc.), which can lead to overfitting. While several methods have been proposed to tackle this problem, existing methods incorporate additional information about nuisance factors during training to develop invariant models. However, enumeration of all possible nuisance factors in speech data and the collection of their annotations is difficult and expensive. We present a robust training scheme for end-to-end speech recognition that adopts an unsupervised adversarial invariance induction framework to separate out essential factors for speech-recognition from nuisances without using any supplementary labels besides the transcriptions. Experiments show that the speech recognition model trained with the proposed training scheme achieves relative improvements of 5.48% on WSJ0, 6.16% on CHiME3, and 6.61% on TIMIT dataset over the base model. Additionally, the proposed method achieves a relative improvement of 14.44% on the combined WSJ0+CHiME3 dataset.
Recurrent Convolutional Strategies for Face Manipulation Detection in Videos
May 16, 2019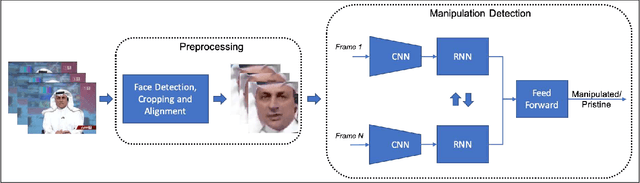
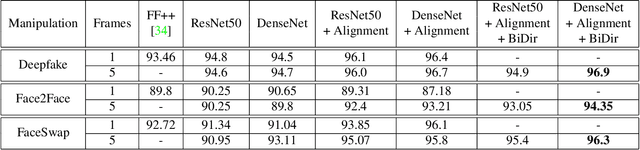
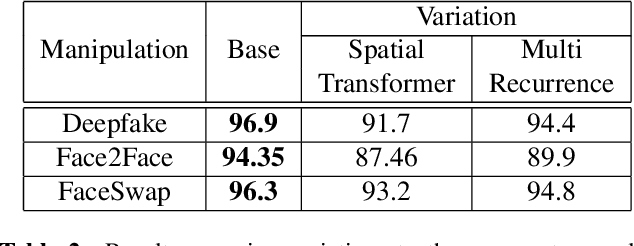
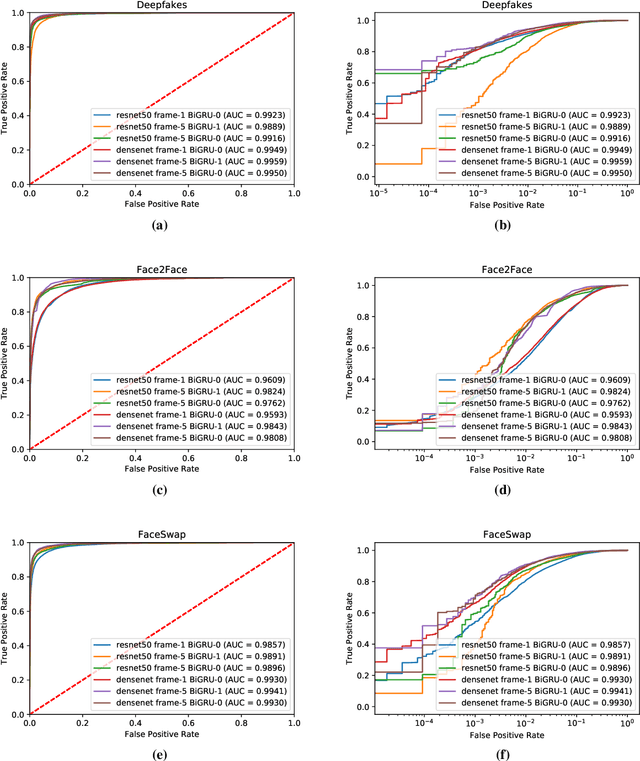
The spread of misinformation through synthetically generated yet realistic images and videos has become a significant problem, calling for robust manipulation detection methods. Despite the predominant effort of detecting face manipulation in still images, less attention has been paid to the identification of tampered faces in videos by taking advantage of the temporal information present in the stream. Recurrent convolutional models are a class of deep learning models which have proven effective at exploiting the temporal information from image streams across domains. We thereby distill the best strategy for combining variations in these models along with domain specific face preprocessing techniques through extensive experimentation to obtain state-of-the-art performance on publicly available video-based facial manipulation benchmarks. Specifically, we attempt to detect Deepfake, Face2Face and FaceSwap tampered faces in video streams. Evaluation is performed on the recently introduced FaceForensics++ dataset, improving the previous state-of-the-art by up to 4.55% in accuracy.
Unified Adversarial Invariance
May 07, 2019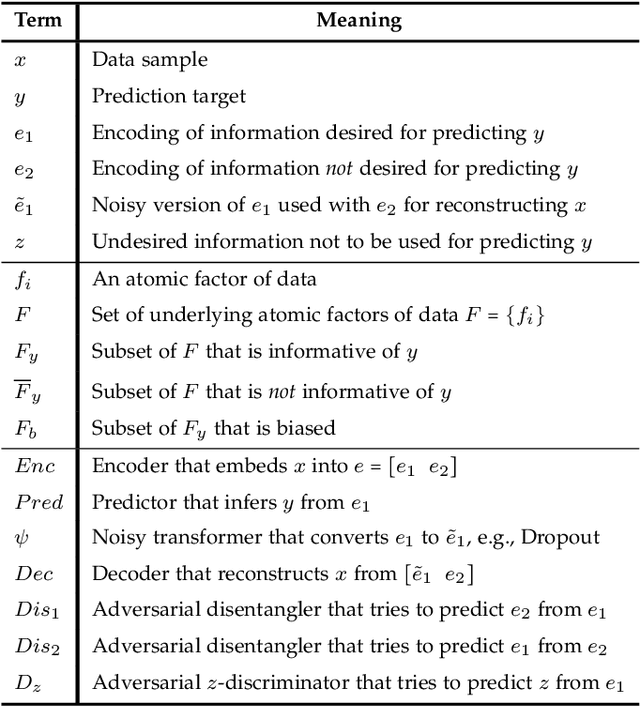
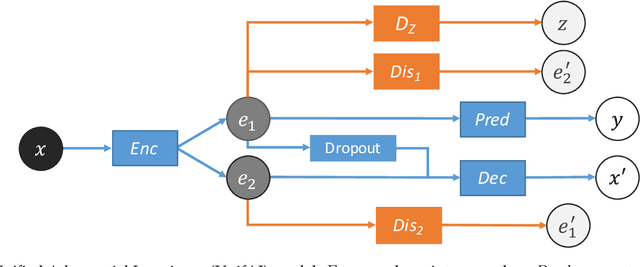
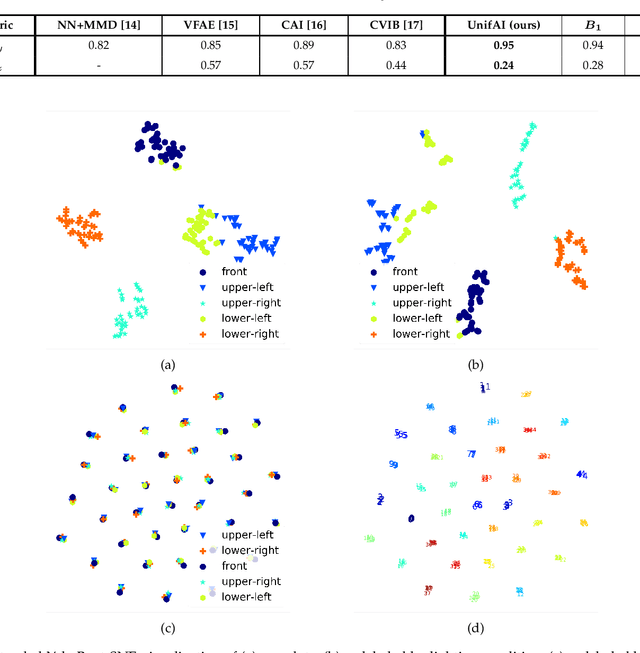

We present a unified invariance framework for supervised neural networks that can induce independence to nuisance factors of data without using any nuisance annotations, but can additionally use labeled information about biasing factors to force their removal from the latent embedding for making fair predictions. Invariance to nuisance is achieved by learning a split representation of data through competitive training between the prediction task and a reconstruction task coupled with disentanglement, whereas that to biasing factors is brought about by penalizing the network if the latent embedding contains any information about them. We describe an adversarial instantiation of this framework and provide analysis of its working. Our model outperforms previous works at inducing invariance to nuisance factors without using any labeled information about such variables, and achieves state-of-the-art performance at learning independence to biasing factors in fairness settings.
AIRD: Adversarial Learning Framework for Image Repurposing Detection
Apr 09, 2019
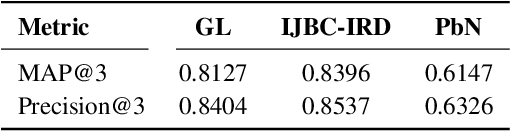
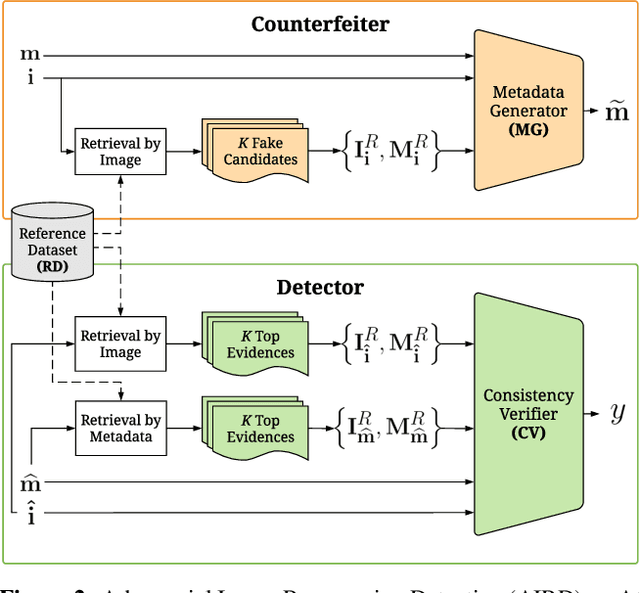
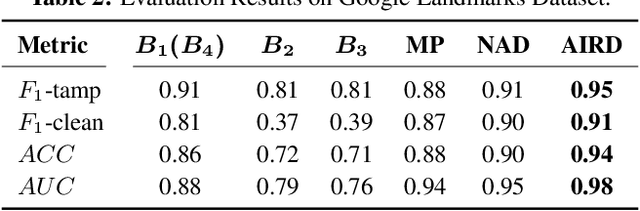
Image repurposing is a commonly used method for spreading misinformation on social media and online forums, which involves publishing untampered images with modified metadata to create rumors and further propaganda. While manual verification is possible, given vast amounts of verified knowledge available on the internet, the increasing prevalence and ease of this form of semantic manipulation call for the development of robust automatic ways of assessing the semantic integrity of multimedia data. In this paper, we present a novel method for image repurposing detection that is based on the real-world adversarial interplay between a bad actor who repurposes images with counterfeit metadata and a watchdog who verifies the semantic consistency between images and their accompanying metadata, where both players have access to a reference dataset of verified content, which they can use to achieve their goals. The proposed method exhibits state-of-the-art performance on location-identity, subject-identity and painting-artist verification, showing its efficacy across a diverse set of scenarios.