 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Stochastic Localization for Non-autoregressive Generation
Feb 18, 2026Non-autoregressive (NAR) generation reduces decoding latency by predicting many tokens in parallel, but iterative refinement often suffers from error accumulation and distribution shift under self-generated drafts. Masked diffusion language models (MDLMs) and their remasking samplers (e.g., ReMDM) can be viewed as modern NAR iterative refinement, where generation repeatedly revises a partially observed draft. In this work we show that \emph{training alone} can substantially improve the step-efficiency of MDLM/ReMDM sampling. We propose \textsc{DSL} (Discrete Stochastic Localization), which trains a single SNR-invariant denoiser across a continuum of corruption levels, bridging intermediate draft noise and mask-style endpoint corruption within one Diffusion Transformer. On OpenWebText, \textsc{DSL} fine-tuning yields large MAUVE gains at low step budgets, surpassing the MDLM+ReMDM baseline with \(\sim\)4$\times$ fewer denoiser evaluations, and matches autoregressive quality at high budgets. Analyses show improved self-correction and uncertainty calibration, making remasking markedly more compute-efficient.
Scalable Spatio-Temporal SE(3) Diffusion for Long-Horizon Protein Dynamics
Feb 02, 2026Molecular dynamics (MD) simulations remain the gold standard for studying protein dynamics, but their computational cost limits access to biologically relevant timescales. Recent generative models have shown promise in accelerating simulations, yet they struggle with long-horizon generation due to architectural constraints, error accumulation, and inadequate modeling of spatio-temporal dynamics. We present STAR-MD (Spatio-Temporal Autoregressive Rollout for Molecular Dynamics), a scalable SE(3)-equivariant diffusion model that generates physically plausible protein trajectories over microsecond timescales. Our key innovation is a causal diffusion transformer with joint spatio-temporal attention that efficiently captures complex space-time dependencies while avoiding the memory bottlenecks of existing methods. On the standard ATLAS benchmark, STAR-MD achieves state-of-the-art performance across all metrics--substantially improving conformational coverage, structural validity, and dynamic fidelity compared to previous methods. STAR-MD successfully extrapolates to generate stable microsecond-scale trajectories where baseline methods fail catastrophically, maintaining high structural quality throughout the extended rollout. Our comprehensive evaluation reveals severe limitations in current models for long-horizon generation, while demonstrating that STAR-MD's joint spatio-temporal modeling enables robust dynamics simulation at biologically relevant timescales, paving the way for accelerated exploration of protein function.
Generation Order and Parallel Decoding in Masked Diffusion Models: An Information-Theoretic Perspective
Jan 30, 2026Masked Diffusion Models (MDMs) significantly accelerate inference by trading off sequential determinism. However, the theoretical mechanisms governing generation order and the risks inherent in parallelization remain under-explored. In this work, we provide a unified information-theoretic framework to decouple and analyze two fundamental sources of failure: order sensitivity and parallelization bias. Our analysis yields three key insights: (1) The benefits of Easy-First decoding (prioritizing low-entropy tokens) are magnified as model error increases; (2) factorized parallel decoding introduces intrinsic sampling errors that can lead to arbitrary large Reverse KL divergence, capturing "incoherence" failures that standard Forward KL metrics overlook; and (3) while verification can eliminate sampling error, it incurs an exponential cost governed by the total correlation within a block. Conversely, heuristics like remasking, though computationally efficient, cannot guarantee distributional correctness. Experiments on a controlled Block-HMM and large-scale MDMs (LLaDA) for arithmetic reasoning validate our theoretical framework.
Measurement-aligned Flow for Inverse Problem
Jun 13, 2025Diffusion models provide a powerful way to incorporate complex prior information for solving inverse problems. However, existing methods struggle to correctly incorporate guidance from conflicting signals in the prior and measurement, especially in the challenging setting of non-Gaussian or unknown noise. To bridge these gaps, we propose Measurement-Aligned Sampling (MAS), a novel framework for linear inverse problem solving that can more flexibly balance prior and measurement information. MAS unifies and extends existing approaches like DDNM and DAPS, and offers a new optimization perspective. MAS can generalize to handle known Gaussian noise, unknown or non-Gaussian noise types. Extensive experiments show that MAS consistently outperforms state-of-the-art methods across a range of tasks.
Feynman-Kac Correctors in Diffusion: Annealing, Guidance, and Product of Experts
Mar 04, 2025While score-based generative models are the model of choice across diverse domains, there are limited tools available for controlling inference-time behavior in a principled manner, e.g. for composing multiple pretrained models. Existing classifier-free guidance methods use a simple heuristic to mix conditional and unconditional scores to approximately sample from conditional distributions. However, such methods do not approximate the intermediate distributions, necessitating additional 'corrector' steps. In this work, we provide an efficient and principled method for sampling from a sequence of annealed, geometric-averaged, or product distributions derived from pretrained score-based models. We derive a weighted simulation scheme which we call Feynman-Kac Correctors (FKCs) based on the celebrated Feynman-Kac formula by carefully accounting for terms in the appropriate partial differential equations (PDEs). To simulate these PDEs, we propose Sequential Monte Carlo (SMC) resampling algorithms that leverage inference-time scaling to improve sampling quality. We empirically demonstrate the utility of our methods by proposing amortized sampling via inference-time temperature annealing, improving multi-objective molecule generation using pretrained models, and improving classifier-free guidance for text-to-image generation. Our code is available at https://github.com/martaskrt/fkc-diffusion.
Generalized Flow Matching for Transition Dynamics Modeling
Oct 19, 2024



Simulating transition dynamics between metastable states is a fundamental challenge in dynamical systems and stochastic processes with wide real-world applications in understanding protein folding, chemical reactions and neural activities. However, the computational challenge often lies on sampling exponentially many paths in which only a small fraction ends in the target metastable state due to existence of high energy barriers. To amortize the cost, we propose a data-driven approach to warm-up the simulation by learning nonlinear interpolations from local dynamics. Specifically, we infer a potential energy function from local dynamics data. To find plausible paths between two metastable states, we formulate a generalized flow matching framework that learns a vector field to sample propable paths between the two marginal densities under the learned energy function. Furthermore, we iteratively refine the model by assigning importance weights to the sampled paths and buffering more likely paths for training. We validate the effectiveness of the proposed method to sample probable paths on both synthetic and real-world molecular systems.
Doob's Lagrangian: A Sample-Efficient Variational Approach to Transition Path Sampling
Oct 10, 2024

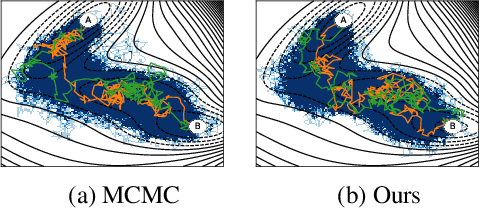
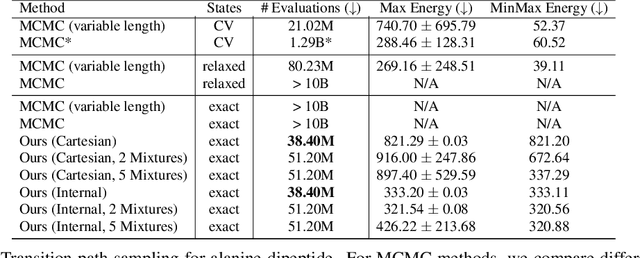
Rare event sampling in dynamical systems is a fundamental problem arising in the natural sciences, which poses significant computational challenges due to an exponentially large space of trajectories. For settings where the dynamical system of interest follows a Brownian motion with known drift, the question of conditioning the process to reach a given endpoint or desired rare event is definitively answered by Doob's h-transform. However, the naive estimation of this transform is infeasible, as it requires simulating sufficiently many forward trajectories to estimate rare event probabilities. In this work, we propose a variational formulation of Doob's $h$-transform as an optimization problem over trajectories between a given initial point and the desired ending point. To solve this optimization, we propose a simulation-free training objective with a model parameterization that imposes the desired boundary conditions by design. Our approach significantly reduces the search space over trajectories and avoids expensive trajectory simulation and inefficient importance sampling estimators which are required in existing methods. We demonstrate the ability of our method to find feasible transition paths on real-world molecular simulation and protein folding tasks.
Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo
Apr 26, 2024Numerous capability and safety techniques of Large Language Models (LLMs), including RLHF, automated red-teaming, prompt engineering, and infilling, can be cast as sampling from an unnormalized target distribution defined by a given reward or potential function over the full sequence. In this work, we leverage the rich toolkit of Sequential Monte Carlo (SMC) for these probabilistic inference problems. In particular, we use learned twist functions to estimate the expected future value of the potential at each timestep, which enables us to focus inference-time computation on promising partial sequences. We propose a novel contrastive method for learning the twist functions, and establish connections with the rich literature of soft reinforcement learning. As a complementary application of our twisted SMC framework, we present methods for evaluating the accuracy of language model inference techniques using novel bidirectional SMC bounds on the log partition function. These bounds can be used to estimate the KL divergence between the inference and target distributions in both directions. We apply our inference evaluation techniques to show that twisted SMC is effective for sampling undesirable outputs from a pretrained model (a useful component of harmlessness training and automated red-teaming), generating reviews with varied sentiment, and performing infilling tasks.
A Computational Framework for Solving Wasserstein Lagrangian Flows
Oct 17, 2023The dynamical formulation of the optimal transport can be extended through various choices of the underlying geometry ($\textit{kinetic energy}$), and the regularization of density paths ($\textit{potential energy}$). These combinations yield different variational problems ($\textit{Lagrangians}$), encompassing many variations of the optimal transport problem such as the Schr\"odinger bridge, unbalanced optimal transport, and optimal transport with physical constraints, among others. In general, the optimal density path is unknown, and solving these variational problems can be computationally challenging. Leveraging the dual formulation of the Lagrangians, we propose a novel deep learning based framework approaching all of these problems from a unified perspective. Our method does not require simulating or backpropagating through the trajectories of the learned dynamics, and does not need access to optimal couplings. We showcase the versatility of the proposed framework by outperforming previous approaches for the single-cell trajectory inference, where incorporating prior knowledge into the dynamics is crucial for correct predictions.
Improving Mutual Information Estimation with Annealed and Energy-Based Bounds
Mar 13, 2023Mutual information (MI) is a fundamental quantity in information theory and machine learning. However, direct estimation of MI is intractable, even if the true joint probability density for the variables of interest is known, as it involves estimating a potentially high-dimensional log partition function. In this work, we present a unifying view of existing MI bounds from the perspective of importance sampling, and propose three novel bounds based on this approach. Since accurate estimation of MI without density information requires a sample size exponential in the true MI, we assume either a single marginal or the full joint density information is known. In settings where the full joint density is available, we propose Multi-Sample Annealed Importance Sampling (AIS) bounds on MI, which we demonstrate can tightly estimate large values of MI in our experiments. In settings where only a single marginal distribution is known, we propose Generalized IWAE (GIWAE) and MINE-AIS bounds. Our GIWAE bound unifies variational and contrastive bounds in a single framework that generalizes InfoNCE, IWAE, and Barber-Agakov bounds. Our MINE-AIS method improves upon existing energy-based methods such as MINE-DV and MINE-F by directly optimizing a tighter lower bound on MI. MINE-AIS uses MCMC sampling to estimate gradients for training and Multi-Sample AIS for evaluating the bound. Our methods are particularly suitable for evaluating MI in deep generative models, since explicit forms of the marginal or joint densities are often available. We evaluate our bounds on estimating the MI of VAEs and GANs trained on the MNIST and CIFAR datasets, and showcase significant gains over existing bounds in these challenging settings with high ground truth MI.