 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrete Feynman-Kac Correctors
Jan 15, 2026Discrete diffusion models have recently emerged as a promising alternative to the autoregressive approach for generating discrete sequences. Sample generation via gradual denoising or demasking processes allows them to capture hierarchical non-sequential interdependencies in the data. These custom processes, however, do not assume a flexible control over the distribution of generated samples. We propose Discrete Feynman-Kac Correctors, a framework that allows for controlling the generated distribution of discrete masked diffusion models at inference time. We derive Sequential Monte Carlo (SMC) algorithms that, given a trained discrete diffusion model, control the temperature of the sampled distribution (i.e. perform annealing), sample from the product of marginals of several diffusion processes (e.g. differently conditioned processes), and sample from the product of the marginal with an external reward function, producing likely samples from the target distribution that also have high reward. Notably, our framework does not require any training of additional models or fine-tuning of the original model. We illustrate the utility of our framework in several applications including: efficient sampling from the annealed Boltzmann distribution of the Ising model, improving the performance of language models for code generation and amortized learning, as well as reward-tilted protein sequence generation.
Assessing Quantum Advantage for Gaussian Process Regression
May 28, 2025



Gaussian Process Regression is a well-known machine learning technique for which several quantum algorithms have been proposed. We show here that in a wide range of scenarios these algorithms show no exponential speedup. We achieve this by rigorously proving that the condition number of a kernel matrix scales at least linearly with the matrix size under general assumptions on the data and kernel. We additionally prove that the sparsity and Frobenius norm of a kernel matrix scale linearly under similar assumptions. The implications for the quantum algorithms runtime are independent of the complexity of loading classical data on a quantum computer and also apply to dequantised algorithms. We supplement our theoretical analysis with numerical verification for popular kernels in machine learning.
Feynman-Kac Correctors in Diffusion: Annealing, Guidance, and Product of Experts
Mar 04, 2025While score-based generative models are the model of choice across diverse domains, there are limited tools available for controlling inference-time behavior in a principled manner, e.g. for composing multiple pretrained models. Existing classifier-free guidance methods use a simple heuristic to mix conditional and unconditional scores to approximately sample from conditional distributions. However, such methods do not approximate the intermediate distributions, necessitating additional 'corrector' steps. In this work, we provide an efficient and principled method for sampling from a sequence of annealed, geometric-averaged, or product distributions derived from pretrained score-based models. We derive a weighted simulation scheme which we call Feynman-Kac Correctors (FKCs) based on the celebrated Feynman-Kac formula by carefully accounting for terms in the appropriate partial differential equations (PDEs). To simulate these PDEs, we propose Sequential Monte Carlo (SMC) resampling algorithms that leverage inference-time scaling to improve sampling quality. We empirically demonstrate the utility of our methods by proposing amortized sampling via inference-time temperature annealing, improving multi-objective molecule generation using pretrained models, and improving classifier-free guidance for text-to-image generation. Our code is available at https://github.com/martaskrt/fkc-diffusion.
Continuous normalizing flows for lattice gauge theories
Oct 17, 2024Continuous normalizing flows are known to be highly expressive and flexible, which allows for easier incorporation of large symmetries and makes them a powerful tool for sampling in lattice field theories. Building on previous work, we present a general continuous normalizing flow architecture for matrix Lie groups that is equivariant under group transformations. We apply this to lattice gauge theories in two dimensions as a proof-of-principle and demonstrate competitive performance, showing its potential as a tool for future lattice sampling tasks.
Accurate Learning of Equivariant Quantum Systems from a Single Ground State
May 20, 2024Predicting properties across system parameters is an important task in quantum physics, with applications ranging from molecular dynamics to variational quantum algorithms. Recently, provably efficient algorithms to solve this task for ground states within a gapped phase were developed. Here we dramatically improve the efficiency of these algorithms by showing how to learn properties of all ground states for systems with periodic boundary conditions from a single ground state sample. We prove that the prediction error tends to zero in the thermodynamic limit and numerically verify the results.
Efficient Learning of Long-Range and Equivariant Quantum Systems
Dec 28, 2023



In this work, we consider a fundamental task in quantum many-body physics - finding and learning ground states of quantum Hamiltonians and their properties. Recent works have studied the task of predicting the ground state expectation value of sums of geometrically local observables by learning from data. For short-range gapped Hamiltonians, a sample complexity that is logarithmic in the number of qubits and quasipolynomial in the error was obtained. Here we extend these results beyond the local requirements on both Hamiltonians and observables, motivated by the relevance of long-range interactions in molecular and atomic systems. For interactions decaying as a power law with exponent greater than twice the dimension of the system, we recover the same efficient logarithmic scaling with respect to the number of qubits, but the dependence on the error worsens to exponential. Further, we show that learning algorithms equivariant under the automorphism group of the interaction hypergraph achieve a sample complexity reduction, leading in particular to a constant number of samples for learning sums of local observables in systems with periodic boundary conditions. We demonstrate the efficient scaling in practice by learning from DMRG simulations of $1$D long-range and disordered systems with up to $128$ qubits. Finally, we provide an analysis of the concentration of expectation values of global observables stemming from central limit theorem, resulting in increased prediction accuracy.
The END: An Equivariant Neural Decoder for Quantum Error Correction
Apr 14, 2023Quantum error correction is a critical component for scaling up quantum computing. Given a quantum code, an optimal decoder maps the measured code violations to the most likely error that occurred, but its cost scales exponentially with the system size. Neural network decoders are an appealing solution since they can learn from data an efficient approximation to such a mapping and can automatically adapt to the noise distribution. In this work, we introduce a data efficient neural decoder that exploits the symmetries of the problem. We characterize the symmetries of the optimal decoder for the toric code and propose a novel equivariant architecture that achieves state of the art accuracy compared to previous neural decoders.
Bayesian Optimization for Macro Placement
Jul 18, 2022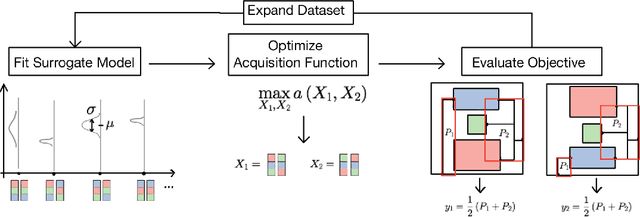
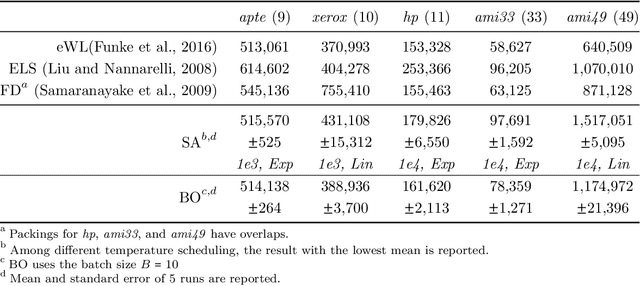
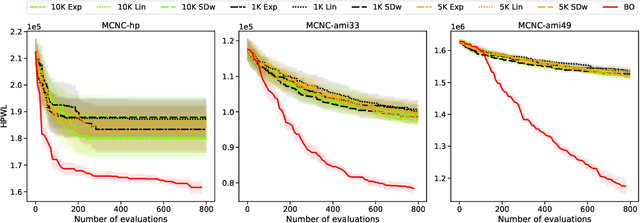

Macro placement is the problem of placing memory blocks on a chip canvas. It can be formulated as a combinatorial optimization problem over sequence pairs, a representation which describes the relative positions of macros. Solving this problem is particularly challenging since the objective function is expensive to evaluate. In this paper, we develop a novel approach to macro placement using Bayesian optimization (BO) over sequence pairs. BO is a machine learning technique that uses a probabilistic surrogate model and an acquisition function that balances exploration and exploitation to efficiently optimize a black-box objective function. BO is more sample-efficient than reinforcement learning and therefore can be used with more realistic objectives. Additionally, the ability to learn from data and adapt the algorithm to the objective function makes BO an appealing alternative to other black-box optimization methods such as simulated annealing, which relies on problem-dependent heuristics and parameter-tuning. We benchmark our algorithm on the fixed-outline macro placement problem with the half-perimeter wire length objective and demonstrate competitive performance.
Neural Topological Ordering for Computation Graphs
Jul 13, 2022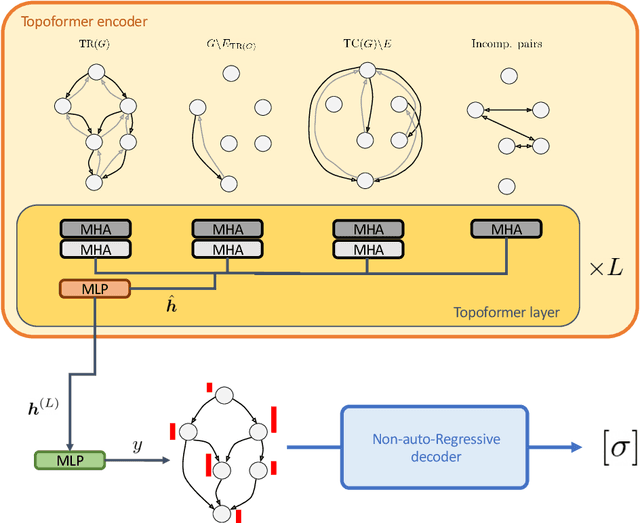
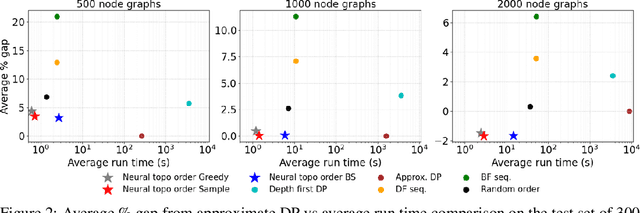
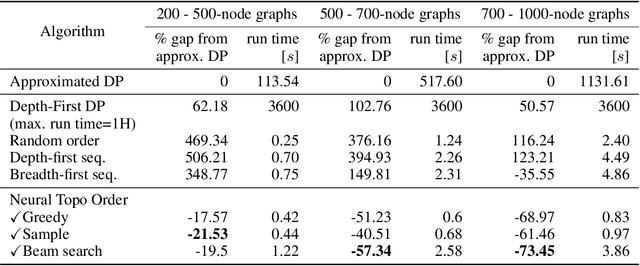
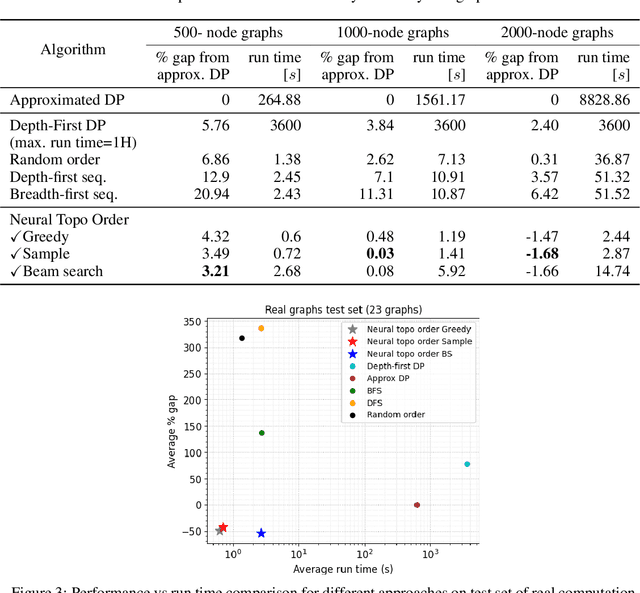
Recent works on machine learning for combinatorial optimization have shown that learning based approaches can outperform heuristic methods in terms of speed and performance. In this paper, we consider the problem of finding an optimal topological order on a directed acyclic graph with focus on the memory minimization problem which arises in compilers. We propose an end-to-end machine learning based approach for topological ordering using an encoder-decoder framework. Our encoder is a novel attention based graph neural network architecture called \emph{Topoformer} which uses different topological transforms of a DAG for message passing. The node embeddings produced by the encoder are converted into node priorities which are used by the decoder to generate a probability distribution over topological orders. We train our model on a dataset of synthetically generated graphs called layered graphs. We show that our model outperforms, or is on-par, with several topological ordering baselines while being significantly faster on synthetic graphs with up to 2k nodes. We also train and test our model on a set of real-world computation graphs, showing performance improvements.
Learning Lattice Quantum Field Theories with Equivariant Continuous Flows
Jul 01, 2022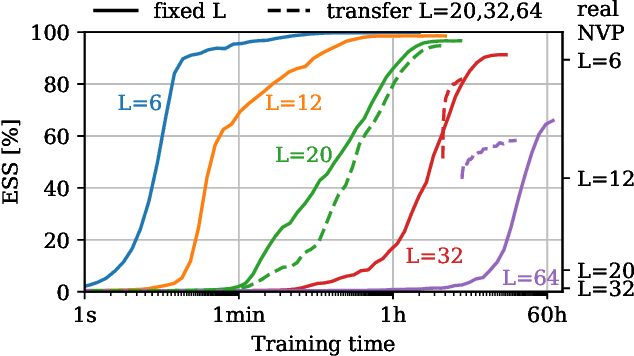

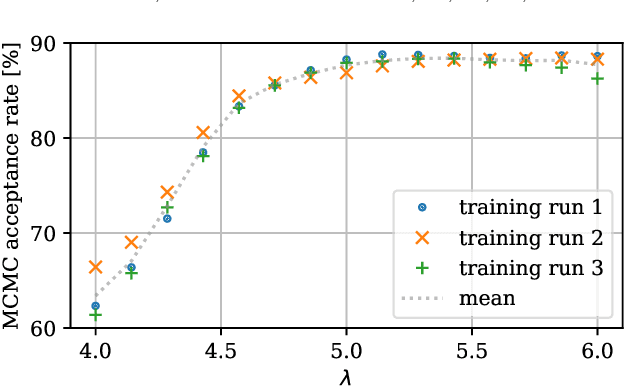
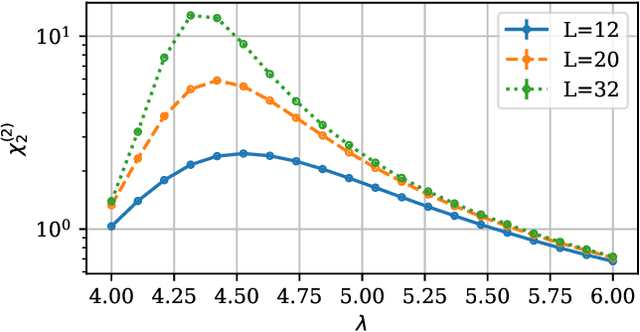
We propose a novel machine learning method for sampling from the high-dimensional probability distributions of Lattice Quantum Field Theories. Instead of the deep architectures used so far for this task, our proposal is based on a single neural ODE layer and incorporates the full symmetries of the problem. We test our model on the $\phi^4$ theory, showing that it systematically outperforms previously proposed flow-based methods in sampling efficiency, and the improvement is especially pronounced for larger lattices. Compared to the previous baseline model, we improve a key metric, the effective sample size, from 1% to 91% on a lattice of size $32\times 32$. We also demonstrate that our model can successfully learn a continuous family of theories at once, and the results of learning can be transferred to larger lattices. Such generalization capacities further accentuate the potential advantages of machine learning methods compared to traditional MCMC-based methods.