 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAi-Sampler: Adversarial Learning of Markov kernels with involutive maps
Jun 04, 2024Markov chain Monte Carlo methods have become popular in statistics as versatile techniques to sample from complicated probability distributions. In this work, we propose a method to parameterize and train transition kernels of Markov chains to achieve efficient sampling and good mixing. This training procedure minimizes the total variation distance between the stationary distribution of the chain and the empirical distribution of the data. Our approach leverages involutive Metropolis-Hastings kernels constructed from reversible neural networks that ensure detailed balance by construction. We find that reversibility also implies $C_2$-equivariance of the discriminator function which can be used to restrict its function space.
The END: An Equivariant Neural Decoder for Quantum Error Correction
Apr 14, 2023Quantum error correction is a critical component for scaling up quantum computing. Given a quantum code, an optimal decoder maps the measured code violations to the most likely error that occurred, but its cost scales exponentially with the system size. Neural network decoders are an appealing solution since they can learn from data an efficient approximation to such a mapping and can automatically adapt to the noise distribution. In this work, we introduce a data efficient neural decoder that exploits the symmetries of the problem. We characterize the symmetries of the optimal decoder for the toric code and propose a novel equivariant architecture that achieves state of the art accuracy compared to previous neural decoders.
Involutive MCMC: a Unifying Framework
Jun 30, 2020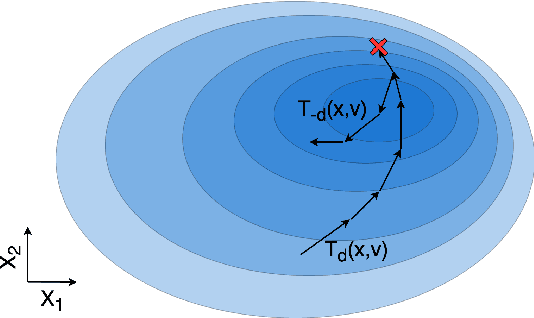
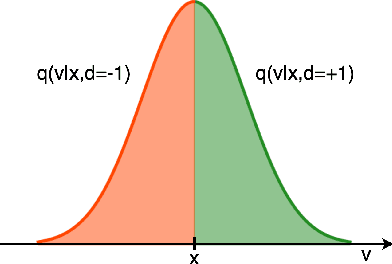

Markov Chain Monte Carlo (MCMC) is a computational approach to fundamental problems such as inference, integration, optimization, and simulation. The field has developed a broad spectrum of algorithms, varying in the way they are motivated, the way they are applied and how efficiently they sample. Despite all the differences, many of them share the same core principle, which we unify as the Involutive MCMC (iMCMC) framework. Building upon this, we describe a wide range of MCMC algorithms in terms of iMCMC, and formulate a number of "tricks" which one can use as design principles for developing new MCMC algorithms. Thus, iMCMC provides a unified view of many known MCMC algorithms, which facilitates the derivation of powerful extensions. We demonstrate the latter with two examples where we transform known reversible MCMC algorithms into more efficient irreversible ones.
Bayesian Generative Models for Knowledge Transfer in MRI Semantic Segmentation Problems
May 27, 2020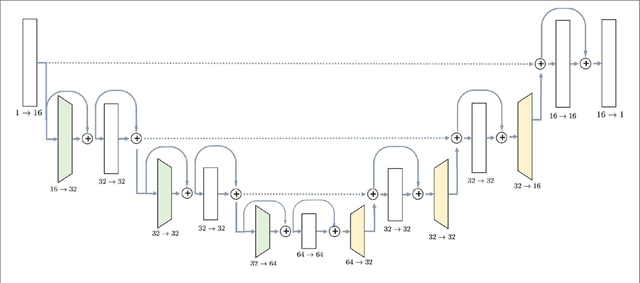


Automatic segmentation methods based on deep learning have recently demonstrated state-of-the-art performance, outperforming the ordinary methods. Nevertheless, these methods are inapplicable for small datasets, which are very common in medical problems. To this end, we propose a knowledge transfer method between diseases via the Generative Bayesian Prior network. Our approach is compared to a pre-train approach and random initialization and obtains the best results in terms of Dice Similarity Coefficient metric for the small subsets of the Brain Tumor Segmentation 2018 database (BRATS2018).
BooVAE: A scalable framework for continual VAE learning under boosting approach
Aug 30, 2019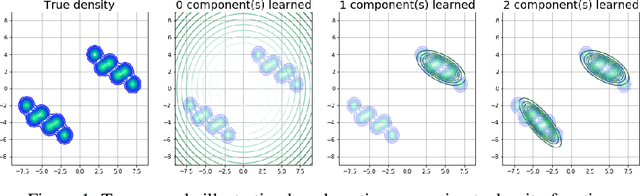

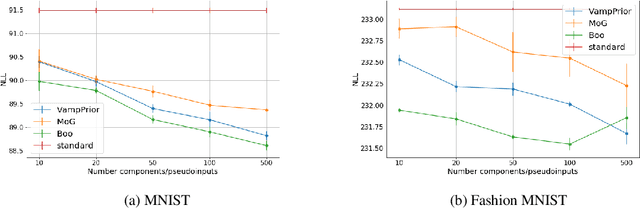
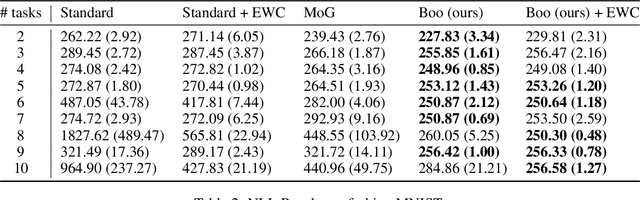
Variational Auto Encoders (VAE) are capable of generating realistic images, sounds and video sequences. From practitioners point of view, we are usually interested in solving problems where tasks are learned sequentially, in a way that avoids revisiting all previous data at each stage. We address this problem by introducing a conceptually simple and scalable end-to-end approach of incorporating past knowledge by learning prior directly from the data. We consider scalable boosting-like approximation for intractable theoretical optimal prior. We provide empirical studies on two commonly used benchmarks, namely MNIST and Fashion MNIST on disjoint sequential image generation tasks. For each dataset proposed method delivers the best results or comparable to SOTA, avoiding catastrophic forgetting in a fully automatic way.
The Implicit Metropolis-Hastings Algorithm
Jun 09, 2019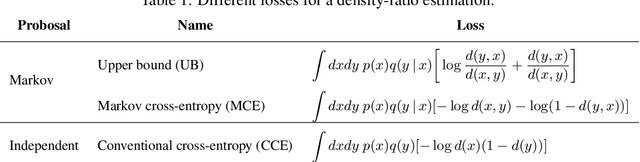
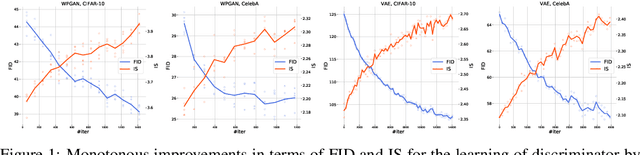

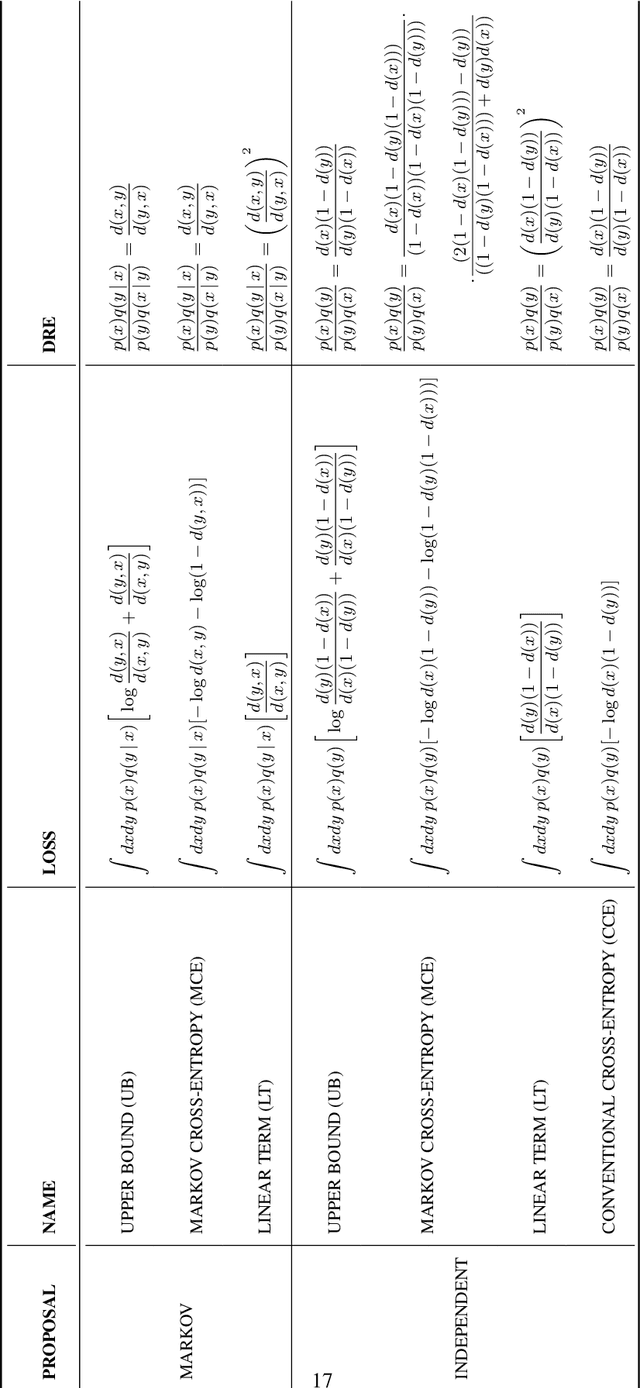
Recent works propose using the discriminator of a GAN to filter out unrealistic samples of the generator. We generalize these ideas by introducing the implicit Metropolis-Hastings algorithm. For any implicit probabilistic model and a target distribution represented by a set of samples, implicit Metropolis-Hastings operates by learning a discriminator to estimate the density-ratio and then generating a chain of samples. Since the approximation of density ratio introduces an error on every step of the chain, it is crucial to analyze the stationary distribution of such chain. For that purpose, we present a theoretical result stating that the discriminator loss upper bounds the total variation distance between the target distribution and the stationary distribution. Finally, we validate the proposed algorithm both for independent and Markov proposals on CIFAR-10 and CelebA datasets.
MaxEntropy Pursuit Variational Inference
May 20, 2019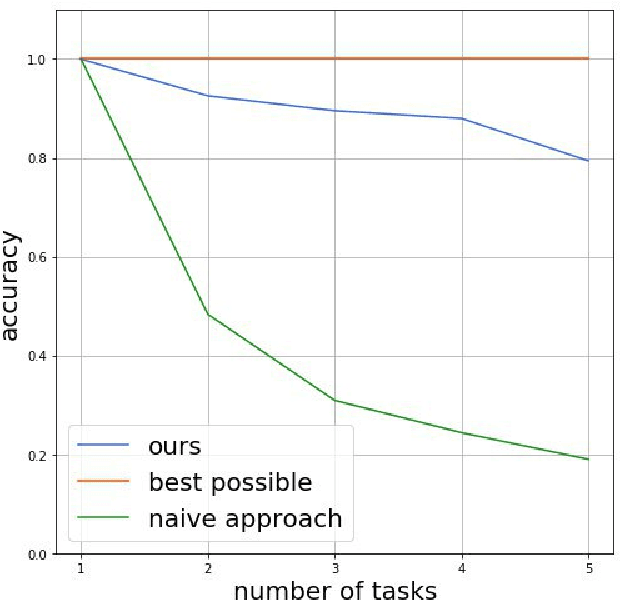
One of the core problems in variational inference is a choice of approximate posterior distribution. It is crucial to trade-off between efficient inference with simple families as mean-field models and accuracy of inference. We propose a variant of a greedy approximation of the posterior distribution with tractable base learners. Using Max-Entropy approach, we obtain a well-defined optimization problem. We demonstrate the ability of the method to capture complex multimodal posterior via continual learning setting for neural networks.
* 10 pages, 1 figure