 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBooVAE: A scalable framework for continual VAE learning under boosting approach
Paper and Code
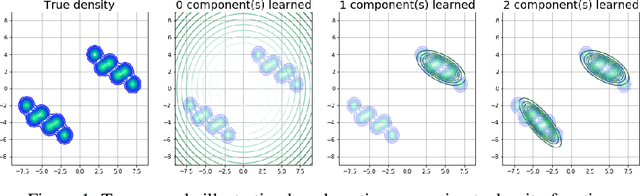

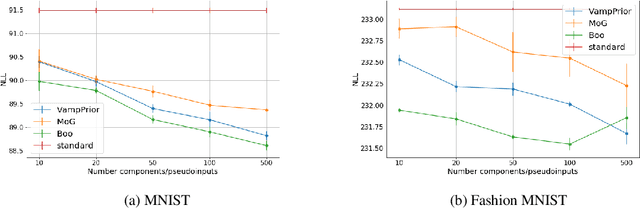
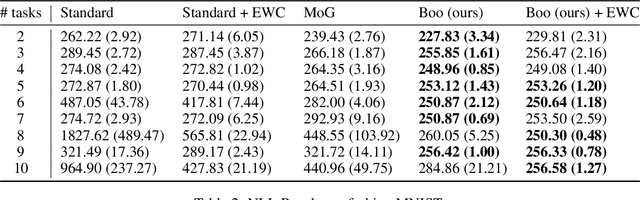
Variational Auto Encoders (VAE) are capable of generating realistic images, sounds and video sequences. From practitioners point of view, we are usually interested in solving problems where tasks are learned sequentially, in a way that avoids revisiting all previous data at each stage. We address this problem by introducing a conceptually simple and scalable end-to-end approach of incorporating past knowledge by learning prior directly from the data. We consider scalable boosting-like approximation for intractable theoretical optimal prior. We provide empirical studies on two commonly used benchmarks, namely MNIST and Fashion MNIST on disjoint sequential image generation tasks. For each dataset proposed method delivers the best results or comparable to SOTA, avoiding catastrophic forgetting in a fully automatic way.