 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reasoning on the Edge
Mar 17, 2026Large language models (LLMs) with chain-of-thought reasoning achieve state-of-the-art performance across complex problem-solving tasks, but their verbose reasoning traces and large context requirements make them impractical for edge deployment. These challenges include high token generation costs, large KV-cache footprints, and inefficiencies when distilling reasoning capabilities into smaller models for mobile devices. Existing approaches often rely on distilling reasoning traces from larger models into smaller models, which are verbose and stylistically redundant, undesirable for on-device inference. In this work, we propose a lightweight approach to enable reasoning in small LLMs using LoRA adapters combined with supervised fine-tuning. We further introduce budget forcing via reinforcement learning on these adapters, significantly reducing response length with minimal accuracy loss. To address memory-bound decoding, we exploit parallel test-time scaling, improving accuracy at minor latency increase. Finally, we present a dynamic adapter-switching mechanism that activates reasoning only when needed and a KV-cache sharing strategy during prompt encoding, reducing time-to-first-token for on-device inference. Experiments on Qwen2.5-7B demonstrate that our method achieves efficient, accurate reasoning under strict resource constraints, making LLM reasoning practical for mobile scenarios. Videos demonstrating our solution running on mobile devices are available on our project page.
KaVa: Latent Reasoning via Compressed KV-Cache Distillation
Oct 02, 2025Large Language Models (LLMs) excel at multi-step reasoning problems with explicit chain-of-thought (CoT), but verbose traces incur significant computational costs and memory overhead, and often carry redundant, stylistic artifacts. Latent reasoning has emerged as an efficient alternative that internalizes the thought process, but it suffers from a critical lack of supervision, limiting its effectiveness on complex, natural-language reasoning traces. In this work, we propose KaVa, the first framework that bridges this gap by distilling knowledge directly from a compressed KV-cache of the teacher into a latent-reasoning student via self-distillation, leveraging the representational flexibility of continuous latent tokens to align stepwise KV trajectories. We show that the abstract, unstructured knowledge within compressed KV-cache, which lacks direct token correspondence, can serve as a rich supervisory signal for a latent reasoning student. Empirically, the approach consistently outperforms strong latent baselines, exhibits markedly smaller degradation from equation-only to natural-language traces, and scales to larger backbones while preserving efficiency. These results establish compressed KV-cache distillation as a scalable supervision signal for latent reasoning, combining the accuracy of CoT-trained teachers with the efficiency and deployability of latent inference.
Hierarchical VAE with a Diffusion-based VampPrior
Dec 02, 2024



Deep hierarchical variational autoencoders (VAEs) are powerful latent variable generative models. In this paper, we introduce Hierarchical VAE with Diffusion-based Variational Mixture of the Posterior Prior (VampPrior). We apply amortization to scale the VampPrior to models with many stochastic layers. The proposed approach allows us to achieve better performance compared to the original VampPrior work and other deep hierarchical VAEs, while using fewer parameters. We empirically validate our method on standard benchmark datasets (MNIST, OMNIGLOT, CIFAR10) and demonstrate improved training stability and latent space utilization.
Variational Stochastic Gradient Descent for Deep Neural Networks
Apr 09, 2024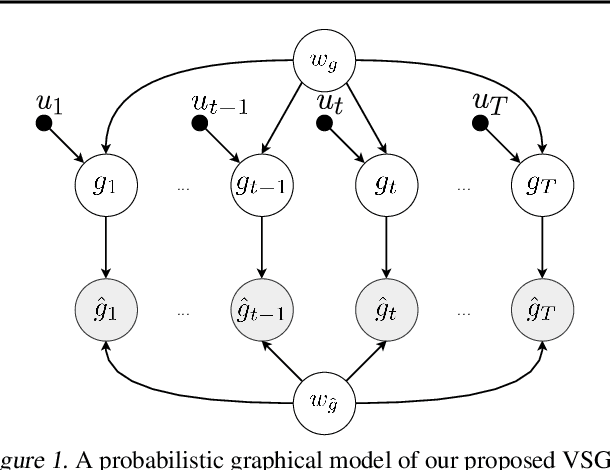
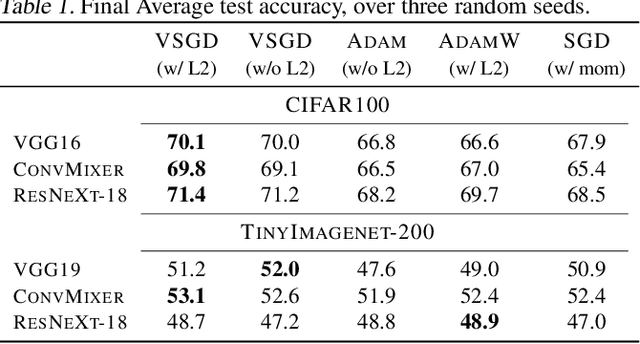
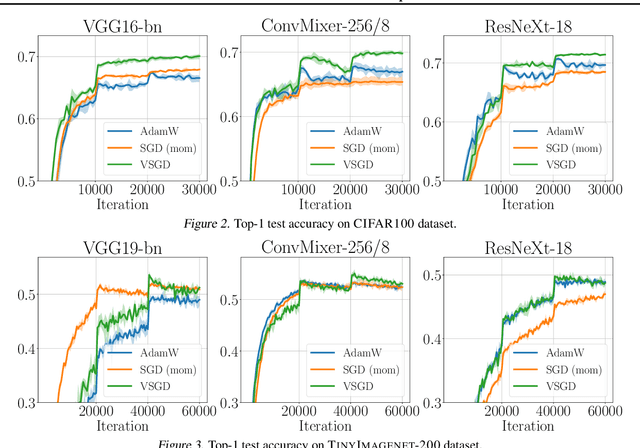
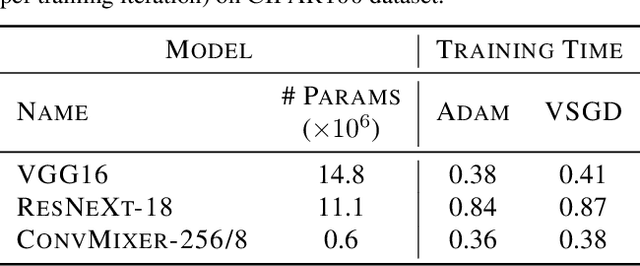
Optimizing deep neural networks is one of the main tasks in successful deep learning. Current state-of-the-art optimizers are adaptive gradient-based optimization methods such as Adam. Recently, there has been an increasing interest in formulating gradient-based optimizers in a probabilistic framework for better estimation of gradients and modeling uncertainties. Here, we propose to combine both approaches, resulting in the Variational Stochastic Gradient Descent (VSGD) optimizer. We model gradient updates as a probabilistic model and utilize stochastic variational inference (SVI) to derive an efficient and effective update rule. Further, we show how our VSGD method relates to other adaptive gradient-based optimizers like Adam. Lastly, we carry out experiments on two image classification datasets and four deep neural network architectures, where we show that VSGD outperforms Adam and SGD.
Exploring Continual Learning of Diffusion Models
Mar 27, 2023



Diffusion models have achieved remarkable success in generating high-quality images thanks to their novel training procedures applied to unprecedented amounts of data. However, training a diffusion model from scratch is computationally expensive. This highlights the need to investigate the possibility of training these models iteratively, reusing computation while the data distribution changes. In this study, we take the first step in this direction and evaluate the continual learning (CL) properties of diffusion models. We begin by benchmarking the most common CL methods applied to Denoising Diffusion Probabilistic Models (DDPMs), where we note the strong performance of the experience replay with the reduced rehearsal coefficient. Furthermore, we provide insights into the dynamics of forgetting, which exhibit diverse behavior across diffusion timesteps. We also uncover certain pitfalls of using the bits-per-dimension metric for evaluating CL.
Analyzing the Posterior Collapse in Hierarchical Variational Autoencoders
Feb 20, 2023



Hierarchical Variational Autoencoders (VAEs) are among the most popular likelihood-based generative models. There is rather a consensus that the top-down hierarchical VAEs allow to effectively learn deep latent structures and avoid problems like the posterior collapse. Here, we show that it is not necessarily the case and the problem of collapsing posteriors remains. To discourage the posterior collapse, we propose a new deep hierarchical VAE with a partly fixed encoder, specifically, we use Discrete Cosine Transform to obtain top latent variables. In a series of experiments, we observe that the proposed modification allows us to achieve better utilization of the latent space. Further, we demonstrate that the proposed approach can be useful for compression and robustness to adversarial attacks.
Equivariant Priors for Compressed Sensing with Unknown Orientation
Jun 28, 2022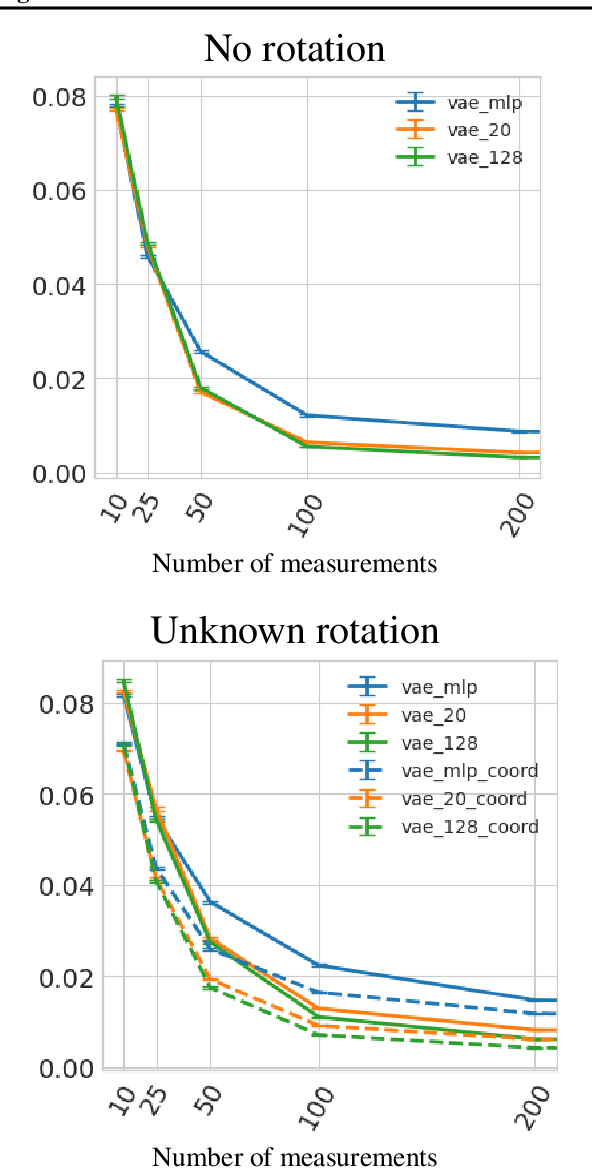
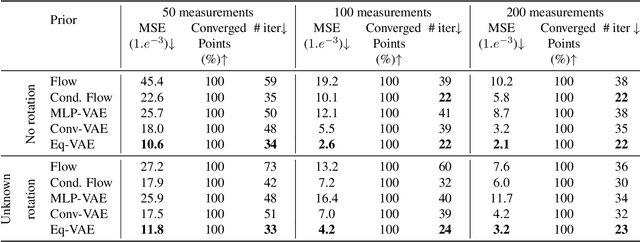
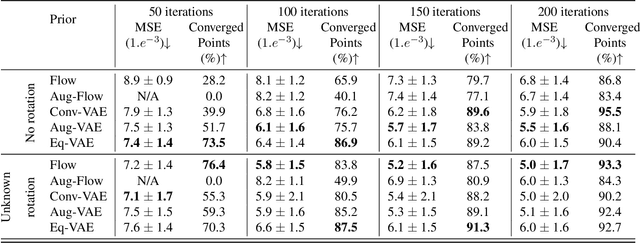
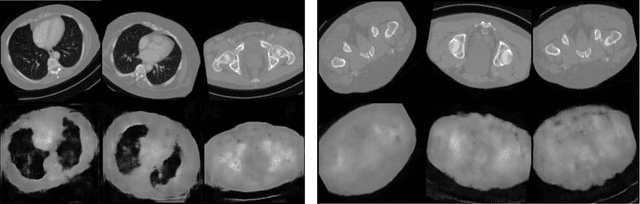
In compressed sensing, the goal is to reconstruct the signal from an underdetermined system of linear measurements. Thus, prior knowledge about the signal of interest and its structure is required. Additionally, in many scenarios, the signal has an unknown orientation prior to measurements. To address such recovery problems, we propose using equivariant generative models as a prior, which encapsulate orientation information in their latent space. Thereby, we show that signals with unknown orientations can be recovered with iterative gradient descent on the latent space of these models and provide additional theoretical recovery guarantees. We construct an equivariant variational autoencoder and use the decoder as generative prior for compressed sensing. We discuss additional potential gains of the proposed approach in terms of convergence and latency.
On Analyzing Generative and Denoising Capabilities of Diffusion-based Deep Generative Models
May 31, 2022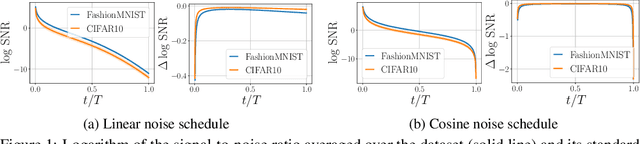
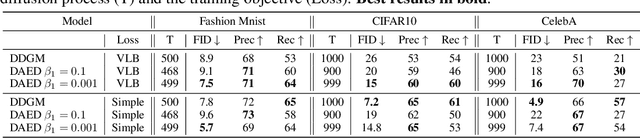
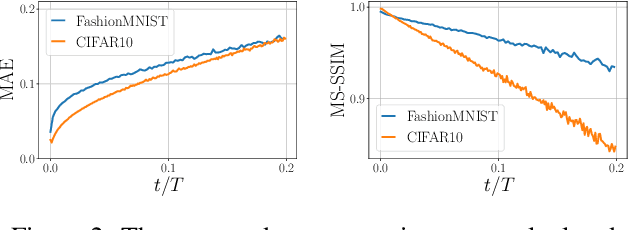
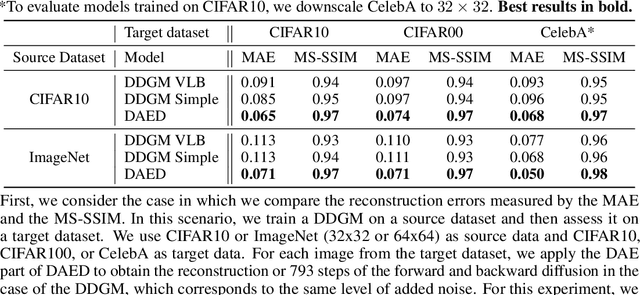
Diffusion-based Deep Generative Models (DDGMs) offer state-of-the-art performance in generative modeling. Their main strength comes from their unique setup in which a model (the backward diffusion process) is trained to reverse the forward diffusion process, which gradually adds noise to the input signal. Although DDGMs are well studied, it is still unclear how the small amount of noise is transformed during the backward diffusion process. Here, we focus on analyzing this problem to gain more insight into the behavior of DDGMs and their denoising and generative capabilities. We observe a fluid transition point that changes the functionality of the backward diffusion process from generating a (corrupted) image from noise to denoising the corrupted image to the final sample. Based on this observation, we postulate to divide a DDGM into two parts: a denoiser and a generator. The denoiser could be parameterized by a denoising auto-encoder, while the generator is a diffusion-based model with its own set of parameters. We experimentally validate our proposition, showing its pros and cons.
Defending Variational Autoencoders from Adversarial Attacks with MCMC
Mar 18, 2022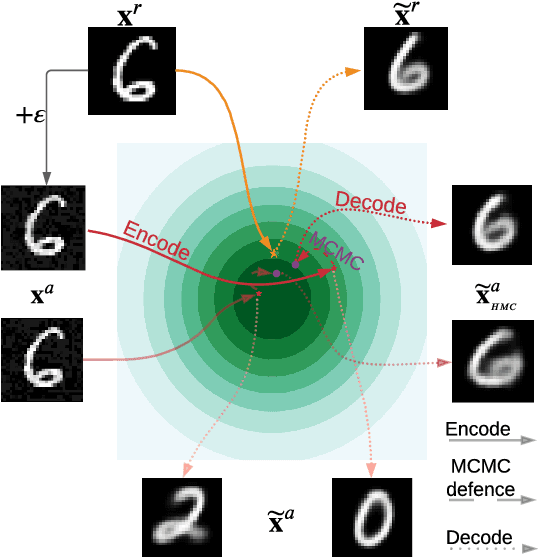

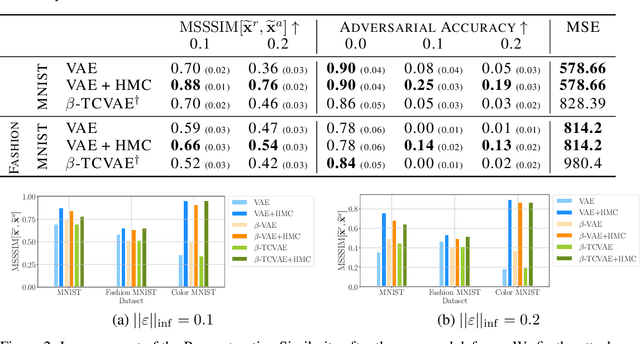
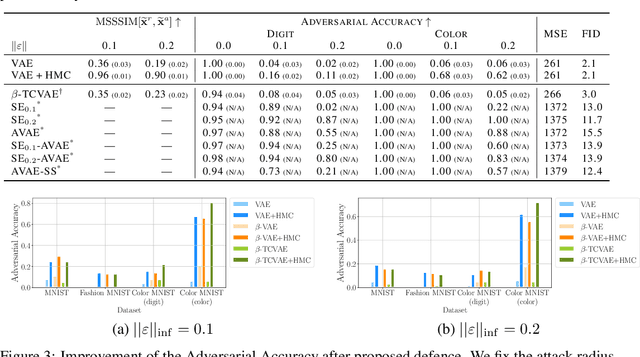
Variational autoencoders (VAEs) are deep generative models used in various domains. VAEs can generate complex objects and provide meaningful latent representations, which can be further used in downstream tasks such as classification. As previous work has shown, one can easily fool VAEs to produce unexpected latent representations and reconstructions for a visually slightly modified input. Here, we examine several objective functions for adversarial attacks construction, suggest metrics assess the model robustness, and propose a solution to alleviate the effect of an attack. Our method utilizes the Markov Chain Monte Carlo (MCMC) technique in the inference step and is motivated by our theoretical analysis. Thus, we do not incorporate any additional costs during training or we do not decrease the performance on non-attacked inputs. We validate our approach on a variety of datasets (MNIST, Fashion MNIST, Color MNIST, CelebA) and VAE configurations ($\beta$-VAE, NVAE, TC-VAE) and show that it consistently improves the model robustness to adversarial attacks.
Diagnosing Vulnerability of Variational Auto-Encoders to Adversarial Attacks
Mar 19, 2021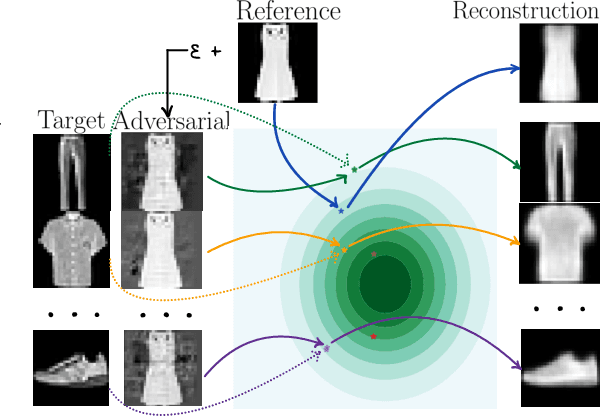

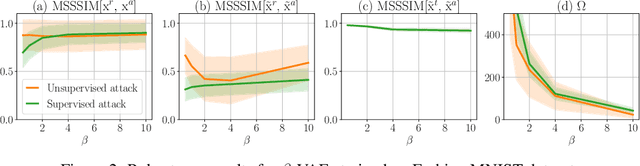

In this work, we explore adversarial attacks on the Variational Autoencoders (VAE). We show how to modify data point to obtain a prescribed latent code (supervised attack) or just get a drastically different code (unsupervised attack). We examine the influence of model modifications ($\beta$-VAE, NVAE) on the robustness of VAEs and suggest metrics to quantify it.