Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiagnosing Vulnerability of Variational Auto-Encoders to Adversarial Attacks
Paper and Code
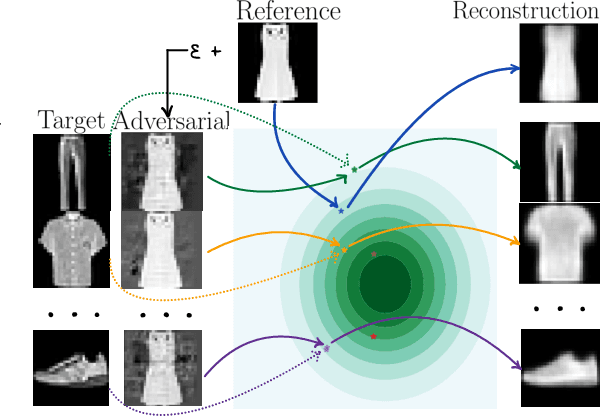

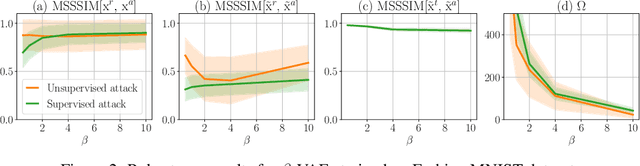

In this work, we explore adversarial attacks on the Variational Autoencoders (VAE). We show how to modify data point to obtain a prescribed latent code (supervised attack) or just get a drastically different code (unsupervised attack). We examine the influence of model modifications ($\beta$-VAE, NVAE) on the robustness of VAEs and suggest metrics to quantify it.
View paper on