 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Molecule Generation and Property Prediction
Apr 23, 2025Modeling the joint distribution of the data samples and their properties allows to construct a single model for both data generation and property prediction, with synergistic capabilities reaching beyond purely generative or predictive models. However, training joint models presents daunting architectural and optimization challenges. Here, we propose Hyformer, a transformer-based joint model that successfully blends the generative and predictive functionalities, using an alternating attention mask together with a unified pre-training scheme. We show that Hyformer rivals other joint models, as well as state-of-the-art molecule generation and property prediction models. Additionally, we show the benefits of joint modeling in downstream tasks of molecular representation learning, hit identification and antimicrobial peptide design.
Knowledge Graph-extended Retrieval Augmented Generation for Question Answering
Apr 11, 2025Large Language Models (LLMs) and Knowledge Graphs (KGs) offer a promising approach to robust and explainable Question Answering (QA). While LLMs excel at natural language understanding, they suffer from knowledge gaps and hallucinations. KGs provide structured knowledge but lack natural language interaction. Ideally, an AI system should be both robust to missing facts as well as easy to communicate with. This paper proposes such a system that integrates LLMs and KGs without requiring training, ensuring adaptability across different KGs with minimal human effort. The resulting approach can be classified as a specific form of a Retrieval Augmented Generation (RAG) with a KG, thus, it is dubbed Knowledge Graph-extended Retrieval Augmented Generation (KG-RAG). It includes a question decomposition module to enhance multi-hop information retrieval and answer explainability. Using In-Context Learning (ICL) and Chain-of-Thought (CoT) prompting, it generates explicit reasoning chains processed separately to improve truthfulness. Experiments on the MetaQA benchmark show increased accuracy for multi-hop questions, though with a slight trade-off in single-hop performance compared to LLM with KG baselines. These findings demonstrate KG-RAG's potential to improve transparency in QA by bridging unstructured language understanding with structured knowledge retrieval.
Hierarchical VAE with a Diffusion-based VampPrior
Dec 02, 2024



Deep hierarchical variational autoencoders (VAEs) are powerful latent variable generative models. In this paper, we introduce Hierarchical VAE with Diffusion-based Variational Mixture of the Posterior Prior (VampPrior). We apply amortization to scale the VampPrior to models with many stochastic layers. The proposed approach allows us to achieve better performance compared to the original VampPrior work and other deep hierarchical VAEs, while using fewer parameters. We empirically validate our method on standard benchmark datasets (MNIST, OMNIGLOT, CIFAR10) and demonstrate improved training stability and latent space utilization.
Attention-based Multi-instance Mixed Models
Nov 04, 2023



Predicting patient features from single-cell data can unveil cellular states implicated in health and disease. Linear models and average cell type expressions are typically favored for this task for their efficiency and robustness, but they overlook the rich cell heterogeneity inherent in single-cell data. To address this gap, we introduce GMIL, a framework integrating Generalized Linear Mixed Models (GLMM) and Multiple Instance Learning (MIL), upholding the advantages of linear models while modeling cell-state heterogeneity. By leveraging predefined cell embeddings, GMIL enhances computational efficiency and aligns with recent advancements in single-cell representation learning. Our empirical results reveal that GMIL outperforms existing MIL models in single-cell datasets, uncovering new associations and elucidating biological mechanisms across different domains.
De Novo Drug Design with Joint Transformers
Oct 03, 2023De novo drug design requires simultaneously generating novel molecules outside of training data and predicting their target properties, making it a hard task for generative models. To address this, we propose Joint Transformer that combines a Transformer decoder, a Transformer encoder, and a predictor in a joint generative model with shared weights. We show that training the model with a penalized log-likelihood objective results in state-of-the-art performance in molecule generation, while decreasing the prediction error on newly sampled molecules, as compared to a fine-tuned decoder-only Transformer, by 42%. Finally, we propose a probabilistic black-box optimization algorithm that employs Joint Transformer to generate novel molecules with improved target properties, as compared to the training data, outperforming other SMILES-based optimization methods in de novo drug design.
Exploring Continual Learning of Diffusion Models
Mar 27, 2023



Diffusion models have achieved remarkable success in generating high-quality images thanks to their novel training procedures applied to unprecedented amounts of data. However, training a diffusion model from scratch is computationally expensive. This highlights the need to investigate the possibility of training these models iteratively, reusing computation while the data distribution changes. In this study, we take the first step in this direction and evaluate the continual learning (CL) properties of diffusion models. We begin by benchmarking the most common CL methods applied to Denoising Diffusion Probabilistic Models (DDPMs), where we note the strong performance of the experience replay with the reduced rehearsal coefficient. Furthermore, we provide insights into the dynamics of forgetting, which exhibit diverse behavior across diffusion timesteps. We also uncover certain pitfalls of using the bits-per-dimension metric for evaluating CL.
Analyzing the Posterior Collapse in Hierarchical Variational Autoencoders
Feb 20, 2023



Hierarchical Variational Autoencoders (VAEs) are among the most popular likelihood-based generative models. There is rather a consensus that the top-down hierarchical VAEs allow to effectively learn deep latent structures and avoid problems like the posterior collapse. Here, we show that it is not necessarily the case and the problem of collapsing posteriors remains. To discourage the posterior collapse, we propose a new deep hierarchical VAE with a partly fixed encoder, specifically, we use Discrete Cosine Transform to obtain top latent variables. In a series of experiments, we observe that the proposed modification allows us to achieve better utilization of the latent space. Further, we demonstrate that the proposed approach can be useful for compression and robustness to adversarial attacks.
Learning Data Representations with Joint Diffusion Models
Jan 31, 2023
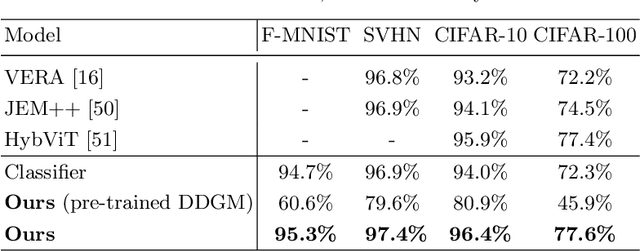


We introduce a joint diffusion model that simultaneously learns meaningful internal representations fit for both generative and predictive tasks. Joint machine learning models that allow synthesizing and classifying data often offer uneven performance between those tasks or are unstable to train. In this work, we depart from a set of empirical observations that indicate the usefulness of internal representations built by contemporary deep diffusion-based generative models in both generative and predictive settings. We then introduce an extension of the vanilla diffusion model with a classifier that allows for stable joint training with shared parametrization between those objectives. The resulting joint diffusion model offers superior performance across various tasks, including generative modeling, semi-supervised classification, and domain adaptation.
Modelling Long Range Dependencies in N-D: From Task-Specific to a General Purpose CNN
Jan 25, 2023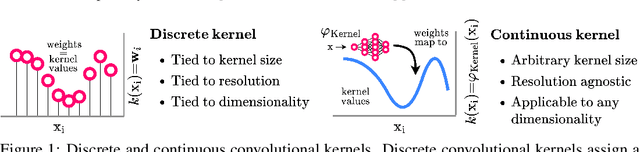
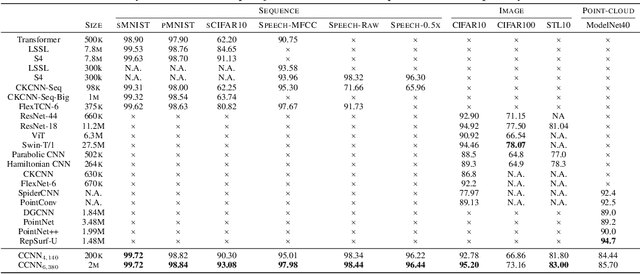
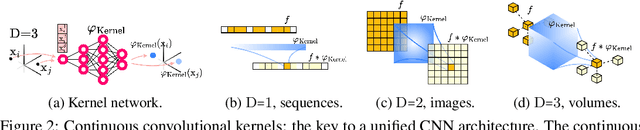
Performant Convolutional Neural Network (CNN) architectures must be tailored to specific tasks in order to consider the length, resolution, and dimensionality of the input data. In this work, we tackle the need for problem-specific CNN architectures. We present the Continuous Convolutional Neural Network (CCNN): a single CNN able to process data of arbitrary resolution, dimensionality and length without any structural changes. Its key component are its continuous convolutional kernels which model long-range dependencies at every layer, and thus remove the need of current CNN architectures for task-dependent downsampling and depths. We showcase the generality of our method by using the same architecture for tasks on sequential ($1{\rm D}$), visual ($2{\rm D}$) and point-cloud ($3{\rm D}$) data. Our CCNN matches and often outperforms the current state-of-the-art across all tasks considered.
A-NeSI: A Scalable Approximate Method for Probabilistic Neurosymbolic Inference
Dec 23, 2022



We study the problem of combining neural networks with symbolic reasoning. Recently introduced frameworks for Probabilistic Neurosymbolic Learning (PNL), such as DeepProbLog, perform exponential-time exact inference, limiting the scalability of PNL solutions. We introduce Approximate Neurosymbolic Inference (A-NeSI): a new framework for PNL that uses neural networks for scalable approximate inference. A-NeSI 1) performs approximate inference in polynomial time without changing the semantics of probabilistic logics; 2) is trained using data generated by the background knowledge; 3) can generate symbolic explanations of predictions; and 4) can guarantee the satisfaction of logical constraints at test time, which is vital in safety-critical applications. Our experiments show that A-NeSI is the first end-to-end method to scale the Multi-digit MNISTAdd benchmark to sums of 15 MNIST digits, up from 4 in competing systems. Finally, our experiments show that A-NeSI achieves explainability and safety without a penalty in performance.