 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Uniformity and Alignment for Multimodal Representation Learning
Feb 10, 2026Multimodal representation learning aims to construct a shared embedding space in which heterogeneous modalities are semantically aligned. Despite strong empirical results, InfoNCE-based objectives introduce inherent conflicts that yield distribution gaps across modalities. In this work, we identify two conflicts in the multimodal regime, both exacerbated as the number of modalities increases: (i) an alignment-uniformity conflict, whereby the repulsion of uniformity undermines pairwise alignment, and (ii) an intra-alignment conflict, where aligning multiple modalities induces competing alignment directions. To address these issues, we propose a principled decoupling of alignment and uniformity for multimodal representations, providing a conflict-free recipe for multimodal learning that simultaneously supports discriminative and generative use cases without task-specific modules. We then provide a theoretical guarantee that our method acts as an efficient proxy for a global Hölder divergence over multiple modality distributions, and thus reduces the distribution gap among modalities. Extensive experiments on retrieval and UnCLIP-style generation demonstrate consistent gains.
Probabilistic Interactive 3D Segmentation with Hierarchical Neural Processes
May 03, 2025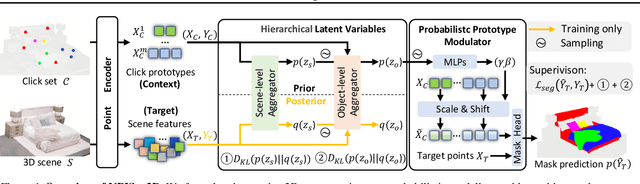
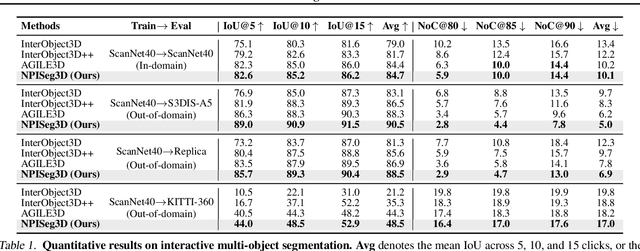
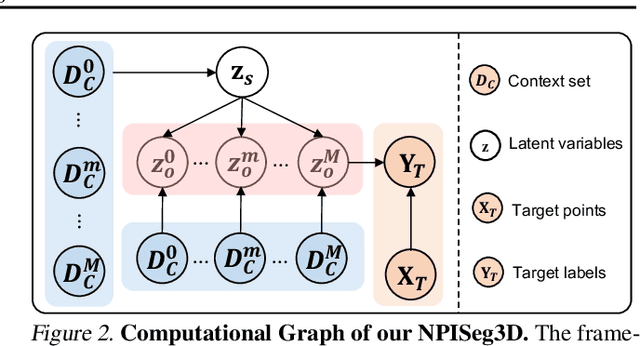
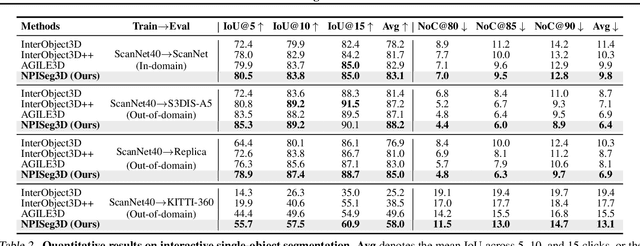
Interactive 3D segmentation has emerged as a promising solution for generating accurate object masks in complex 3D scenes by incorporating user-provided clicks. However, two critical challenges remain underexplored: (1) effectively generalizing from sparse user clicks to produce accurate segmentation, and (2) quantifying predictive uncertainty to help users identify unreliable regions. In this work, we propose NPISeg3D, a novel probabilistic framework that builds upon Neural Processes (NPs) to address these challenges. Specifically, NPISeg3D introduces a hierarchical latent variable structure with scene-specific and object-specific latent variables to enhance few-shot generalization by capturing both global context and object-specific characteristics. Additionally, we design a probabilistic prototype modulator that adaptively modulates click prototypes with object-specific latent variables, improving the model's ability to capture object-aware context and quantify predictive uncertainty. Experiments on four 3D point cloud datasets demonstrate that NPISeg3D achieves superior segmentation performance with fewer clicks while providing reliable uncertainty estimations.
Distributional Vision-Language Alignment by Cauchy-Schwarz Divergence
Feb 24, 2025Multimodal alignment is crucial for various downstream tasks such as cross-modal generation and retrieval. Previous multimodal approaches like CLIP maximize the mutual information mainly by aligning pairwise samples across modalities while overlooking the distributional differences, leading to suboptimal alignment with modality gaps. In this paper, to overcome the limitation, we propose CS-Aligner, a novel and straightforward framework that performs distributional vision-language alignment by integrating Cauchy-Schwarz (CS) divergence with mutual information. In the proposed framework, we find that the CS divergence and mutual information serve complementary roles in multimodal alignment, capturing both the global distribution information of each modality and the pairwise semantic relationships, yielding tighter and more precise alignment. Moreover, CS-Aligher enables incorporating additional information from unpaired data and token-level representations, enhancing flexible and fine-grained alignment in practice. Experiments on text-to-image generation and cross-modality retrieval tasks demonstrate the effectiveness of our method on vision-language alignment.
Geometric Neural Process Fields
Feb 04, 2025This paper addresses the challenge of Neural Field (NeF) generalization, where models must efficiently adapt to new signals given only a few observations. To tackle this, we propose Geometric Neural Process Fields (G-NPF), a probabilistic framework for neural radiance fields that explicitly captures uncertainty. We formulate NeF generalization as a probabilistic problem, enabling direct inference of NeF function distributions from limited context observations. To incorporate structural inductive biases, we introduce a set of geometric bases that encode spatial structure and facilitate the inference of NeF function distributions. Building on these bases, we design a hierarchical latent variable model, allowing G-NPF to integrate structural information across multiple spatial levels and effectively parameterize INR functions. This hierarchical approach improves generalization to novel scenes and unseen signals. Experiments on novel-view synthesis for 3D scenes, as well as 2D image and 1D signal regression, demonstrate the effectiveness of our method in capturing uncertainty and leveraging structural information for improved generalization.
Deep End-to-end Adaptive k-Space Sampling, Reconstruction, and Registration for Dynamic MRI
Nov 27, 2024Dynamic MRI enables a range of clinical applications, including cardiac function assessment, organ motion tracking, and radiotherapy guidance. However, fully sampling the dynamic k-space data is often infeasible due to time constraints and physiological motion such as respiratory and cardiac motion. This necessitates undersampling, which degrades the quality of reconstructed images. Poor image quality not only hinders visualization but also impairs the estimation of deformation fields, crucial for registering dynamic (moving) images to a static reference image. This registration enables tasks such as motion correction, treatment planning, and quantitative analysis in applications like cardiac imaging and MR-guided radiotherapy. To overcome the challenges posed by undersampling and motion, we introduce an end-to-end deep learning (DL) framework that integrates adaptive dynamic k-space sampling, reconstruction, and registration. Our approach begins with a DL-based adaptive sampling strategy, optimizing dynamic k-space acquisition to capture the most relevant data for each specific case. This is followed by a DL-based reconstruction module that produces images optimized for accurate deformation field estimation from the undersampled moving data. Finally, a registration module estimates the deformation fields aligning the reconstructed dynamic images with a static reference. The proposed framework is independent of specific reconstruction and registration modules allowing for plug-and-play integration of these components. The entire framework is jointly trained using a combination of supervised and unsupervised loss functions, enabling end-to-end optimization for improved performance across all components. Through controlled experiments and ablation studies, we validate each component, demonstrating that each choice contributes to robust motion estimation from undersampled dynamic data.
CaPo: Cooperative Plan Optimization for Efficient Embodied Multi-Agent Cooperation
Nov 07, 2024



In this work, we address the cooperation problem among large language model (LLM) based embodied agents, where agents must cooperate to achieve a common goal. Previous methods often execute actions extemporaneously and incoherently, without long-term strategic and cooperative planning, leading to redundant steps, failures, and even serious repercussions in complex tasks like search-and-rescue missions where discussion and cooperative plan are crucial. To solve this issue, we propose Cooperative Plan Optimization (CaPo) to enhance the cooperation efficiency of LLM-based embodied agents. Inspired by human cooperation schemes, CaPo improves cooperation efficiency with two phases: 1) meta-plan generation, and 2) progress-adaptive meta-plan and execution. In the first phase, all agents analyze the task, discuss, and cooperatively create a meta-plan that decomposes the task into subtasks with detailed steps, ensuring a long-term strategic and coherent plan for efficient coordination. In the second phase, agents execute tasks according to the meta-plan and dynamically adjust it based on their latest progress (e.g., discovering a target object) through multi-turn discussions. This progress-based adaptation eliminates redundant actions, improving the overall cooperation efficiency of agents. Experimental results on the ThreeDworld Multi-Agent Transport and Communicative Watch-And-Help tasks demonstrate that CaPo achieves much higher task completion rate and efficiency compared with state-of-the-arts.
Deep Multi-contrast Cardiac MRI Reconstruction via vSHARP with Auxiliary Refinement Network
Nov 02, 2024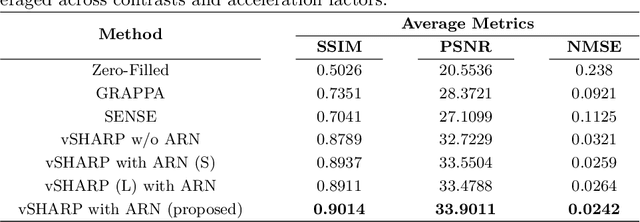

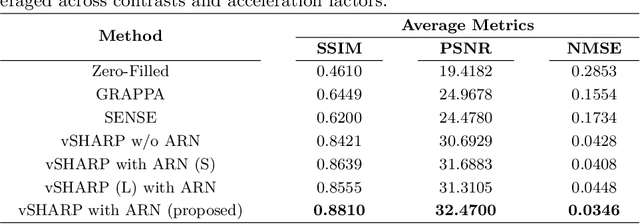

Cardiac MRI (CMRI) is a cornerstone imaging modality that provides in-depth insights into cardiac structure and function. Multi-contrast CMRI (MCCMRI), which acquires sequences with varying contrast weightings, significantly enhances diagnostic capabilities by capturing a wide range of cardiac tissue characteristics. However, MCCMRI is often constrained by lengthy acquisition times and susceptibility to motion artifacts. To mitigate these challenges, accelerated imaging techniques that use k-space undersampling via different sampling schemes at acceleration factors have been developed to shorten scan durations. In this context, we propose a deep learning-based reconstruction method for 2D dynamic multi-contrast, multi-scheme, and multi-acceleration MRI. Our approach integrates the state-of-the-art vSHARP model, which utilizes half-quadratic variable splitting and ADMM optimization, with a Variational Network serving as an Auxiliary Refinement Network (ARN) to better adapt to the diverse nature of MCCMRI data. Specifically, the subsampled k-space data is fed into the ARN, which produces an initial prediction for the denoising step used by vSHARP. This, along with the subsampled k-space, is then used by vSHARP to generate high-quality 2D sequence predictions. Our method outperforms traditional reconstruction techniques and other vSHARP-based models.
Space-Time Continuous PDE Forecasting using Equivariant Neural Fields
Jun 10, 2024



Recently, Conditional Neural Fields (NeFs) have emerged as a powerful modelling paradigm for PDEs, by learning solutions as flows in the latent space of the Conditional NeF. Although benefiting from favourable properties of NeFs such as grid-agnosticity and space-time-continuous dynamics modelling, this approach limits the ability to impose known constraints of the PDE on the solutions -- e.g. symmetries or boundary conditions -- in favour of modelling flexibility. Instead, we propose a space-time continuous NeF-based solving framework that - by preserving geometric information in the latent space - respects known symmetries of the PDE. We show that modelling solutions as flows of pointclouds over the group of interest $G$ improves generalization and data-efficiency. We validated that our framework readily generalizes to unseen spatial and temporal locations, as well as geometric transformations of the initial conditions - where other NeF-based PDE forecasting methods fail - and improve over baselines in a number of challenging geometries.
Domain Adaptation with Cauchy-Schwarz Divergence
May 30, 2024



Domain adaptation aims to use training data from one or multiple source domains to learn a hypothesis that can be generalized to a different, but related, target domain. As such, having a reliable measure for evaluating the discrepancy of both marginal and conditional distributions is crucial. We introduce Cauchy-Schwarz (CS) divergence to the problem of unsupervised domain adaptation (UDA). The CS divergence offers a theoretically tighter generalization error bound than the popular Kullback-Leibler divergence. This holds for the general case of supervised learning, including multi-class classification and regression. Furthermore, we illustrate that the CS divergence enables a simple estimator on the discrepancy of both marginal and conditional distributions between source and target domains in the representation space, without requiring any distributional assumptions. We provide multiple examples to illustrate how the CS divergence can be conveniently used in both distance metric- or adversarial training-based UDA frameworks, resulting in compelling performance.
End-to-end Adaptive Dynamic Subsampling and Reconstruction for Cardiac MRI
Mar 15, 2024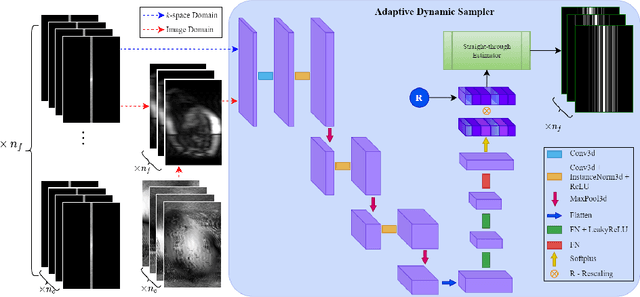
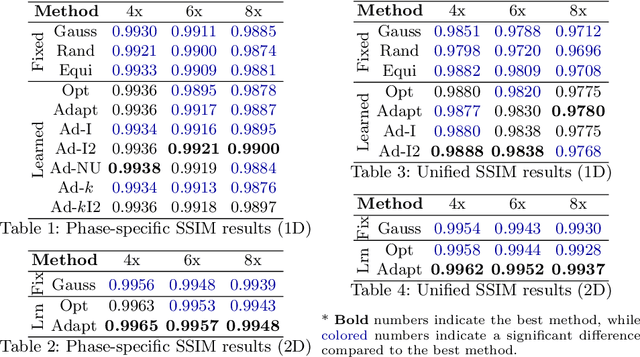
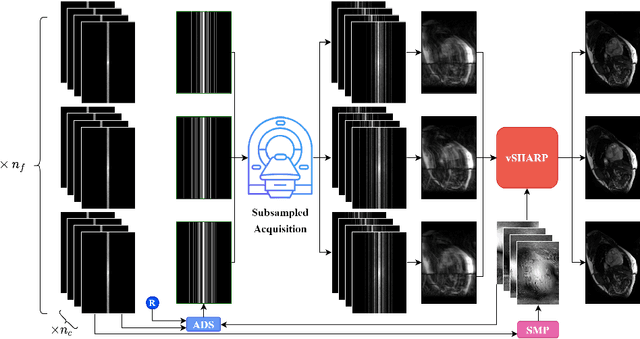
Accelerating dynamic MRI is essential for enhancing clinical applications, such as adaptive radiotherapy, and improving patient comfort. Traditional deep learning (DL) approaches for accelerated dynamic MRI reconstruction typically rely on predefined or random subsampling patterns, applied uniformly across all temporal phases. This standard practice overlooks the potential benefits of leveraging temporal correlations and lacks the adaptability required for case-specific subsampling optimization, which holds the potential for maximizing reconstruction quality. Addressing this gap, we present a novel end-to-end framework for adaptive dynamic MRI subsampling and reconstruction. Our pipeline integrates a DL-based adaptive sampler, generating case-specific dynamic subsampling patterns, trained end-to-end with a state-of-the-art 2D dynamic reconstruction network, namely vSHARP, which effectively reconstructs the adaptive dynamic subsampled data into a moving image. Our method is assessed using dynamic cine cardiac MRI data, comparing its performance against vSHARP models that employ common subsampling trajectories, and pipelines trained to optimize dataset-specific sampling schemes alongside vSHARP reconstruction. Our results indicate superior reconstruction quality, particularly at high accelerations.