 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Continuous Representations in Geometry: Equivariant Neural Fields
Jun 11, 2024



Recently, Neural Fields have emerged as a powerful modelling paradigm to represent continuous signals. In a conditional neural field, a field is represented by a latent variable that conditions the NeF, whose parametrisation is otherwise shared over an entire dataset. We propose Equivariant Neural Fields based on cross attention transformers, in which NeFs are conditioned on a geometric conditioning variable, a latent point cloud, that enables an equivariant decoding from latent to field. Our equivariant approach induces a steerability property by which both field and latent are grounded in geometry and amenable to transformation laws if the field transforms, the latent represents transforms accordingly and vice versa. Crucially, the equivariance relation ensures that the latent is capable of (1) representing geometric patterns faitfhully, allowing for geometric reasoning in latent space, (2) weightsharing over spatially similar patterns, allowing for efficient learning of datasets of fields. These main properties are validated using classification experiments and a verification of the capability of fitting entire datasets, in comparison to other non-equivariant NeF approaches. We further validate the potential of ENFs by demonstrate unique local field editing properties.
Space-Time Continuous PDE Forecasting using Equivariant Neural Fields
Jun 10, 2024



Recently, Conditional Neural Fields (NeFs) have emerged as a powerful modelling paradigm for PDEs, by learning solutions as flows in the latent space of the Conditional NeF. Although benefiting from favourable properties of NeFs such as grid-agnosticity and space-time-continuous dynamics modelling, this approach limits the ability to impose known constraints of the PDE on the solutions -- e.g. symmetries or boundary conditions -- in favour of modelling flexibility. Instead, we propose a space-time continuous NeF-based solving framework that - by preserving geometric information in the latent space - respects known symmetries of the PDE. We show that modelling solutions as flows of pointclouds over the group of interest $G$ improves generalization and data-efficiency. We validated that our framework readily generalizes to unseen spatial and temporal locations, as well as geometric transformations of the initial conditions - where other NeF-based PDE forecasting methods fail - and improve over baselines in a number of challenging geometries.
How to Train Neural Field Representations: A Comprehensive Study and Benchmark
Dec 16, 2023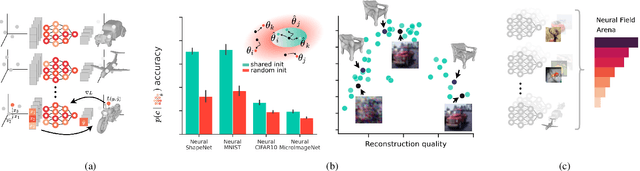
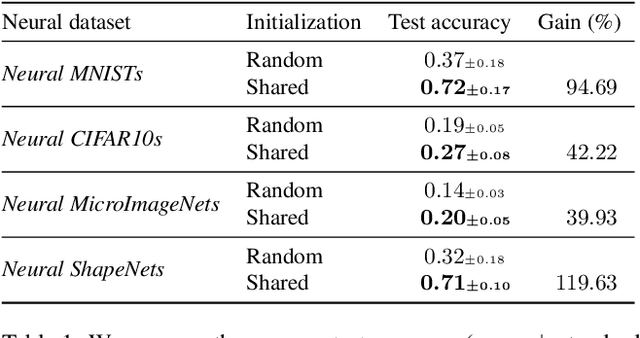


Neural fields (NeFs) have recently emerged as a versatile method for modeling signals of various modalities, including images, shapes, and scenes. Subsequently, a number of works have explored the use of NeFs as representations for downstream tasks, e.g. classifying an image based on the parameters of a NeF that has been fit to it. However, the impact of the NeF hyperparameters on their quality as downstream representation is scarcely understood and remains largely unexplored. This is in part caused by the large amount of time required to fit datasets of neural fields. In this work, we propose $\verb|fit-a-nef|$, a JAX-based library that leverages parallelization to enable fast optimization of large-scale NeF datasets, resulting in a significant speed-up. With this library, we perform a comprehensive study that investigates the effects of different hyperparameters -- including initialization, network architecture, and optimization strategies -- on fitting NeFs for downstream tasks. Our study provides valuable insights on how to train NeFs and offers guidance for optimizing their effectiveness in downstream applications. Finally, based on the proposed library and our analysis, we propose Neural Field Arena, a benchmark consisting of neural field variants of popular vision datasets, including MNIST, CIFAR, variants of ImageNet, and ShapeNetv2. Our library and the Neural Field Arena will be open-sourced to introduce standardized benchmarking and promote further research on neural fields.
Data Augmentations in Deep Weight Spaces
Nov 15, 2023Learning in weight spaces, where neural networks process the weights of other deep neural networks, has emerged as a promising research direction with applications in various fields, from analyzing and editing neural fields and implicit neural representations, to network pruning and quantization. Recent works designed architectures for effective learning in that space, which takes into account its unique, permutation-equivariant, structure. Unfortunately, so far these architectures suffer from severe overfitting and were shown to benefit from large datasets. This poses a significant challenge because generating data for this learning setup is laborious and time-consuming since each data sample is a full set of network weights that has to be trained. In this paper, we address this difficulty by investigating data augmentations for weight spaces, a set of techniques that enable generating new data examples on the fly without having to train additional input weight space elements. We first review several recently proposed data augmentation schemes %that were proposed recently and divide them into categories. We then introduce a novel augmentation scheme based on the Mixup method. We evaluate the performance of these techniques on existing benchmarks as well as new benchmarks we generate, which can be valuable for future studies.
Neural Modulation Fields for Conditional Cone Beam Neural Tomography
Jul 17, 2023



Conventional Computed Tomography (CT) methods require large numbers of noise-free projections for accurate density reconstructions, limiting their applicability to the more complex class of Cone Beam Geometry CT (CBCT) reconstruction. Recently, deep learning methods have been proposed to overcome these limitations, with methods based on neural fields (NF) showing strong performance, by approximating the reconstructed density through a continuous-in-space coordinate based neural network. Our focus is on improving such methods, however, unlike previous work, which requires training an NF from scratch for each new set of projections, we instead propose to leverage anatomical consistencies over different scans by training a single conditional NF on a dataset of projections. We propose a novel conditioning method where local modulations are modeled per patient as a field over the input domain through a Neural Modulation Field (NMF). The resulting Conditional Cone Beam Neural Tomography (CondCBNT) shows improved performance for both high and low numbers of available projections on noise-free and noisy data.
Learning Lie Group Symmetry Transformations with Neural Networks
Jul 04, 2023The problem of detecting and quantifying the presence of symmetries in datasets is useful for model selection, generative modeling, and data analysis, amongst others. While existing methods for hard-coding transformations in neural networks require prior knowledge of the symmetries of the task at hand, this work focuses on discovering and characterizing unknown symmetries present in the dataset, namely, Lie group symmetry transformations beyond the traditional ones usually considered in the field (rotation, scaling, and translation). Specifically, we consider a scenario in which a dataset has been transformed by a one-parameter subgroup of transformations with different parameter values for each data point. Our goal is to characterize the transformation group and the distribution of the parameter values. The results showcase the effectiveness of the approach in both these settings.
Learning reversible symplectic dynamics
Apr 26, 2022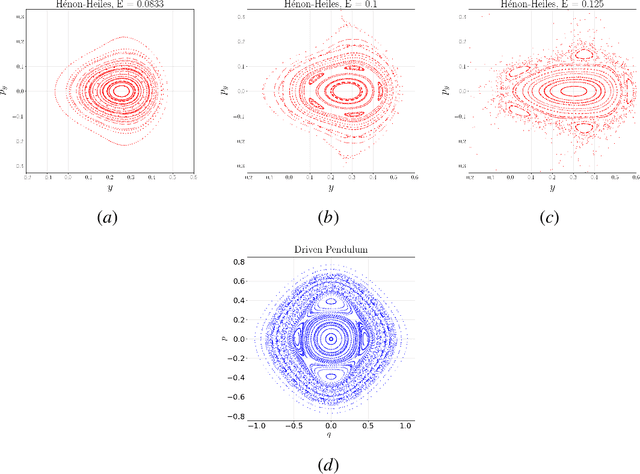
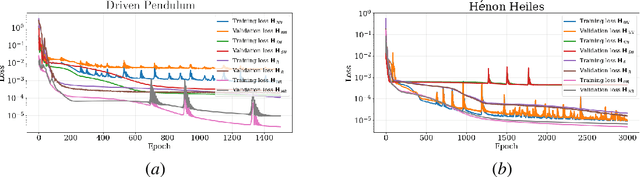
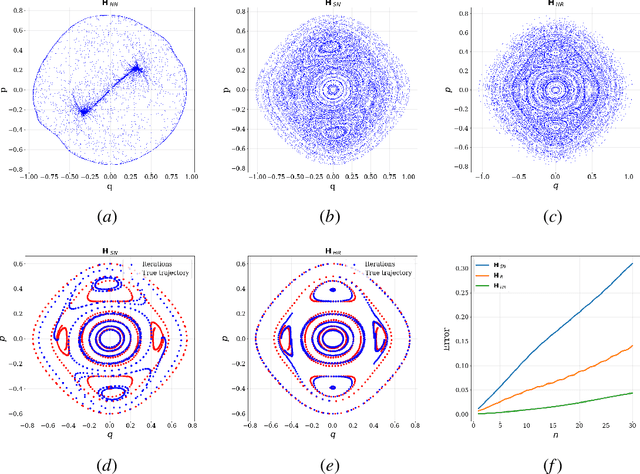
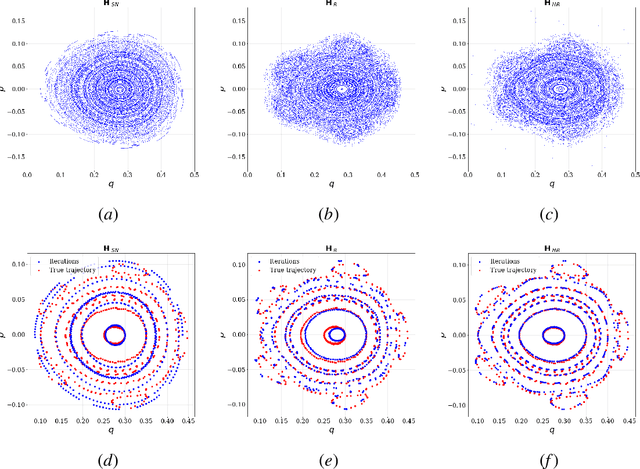
Time-reversal symmetry arises naturally as a structural property in many dynamical systems of interest. While the importance of hard-wiring symmetry is increasingly recognized in machine learning, to date this has eluded time-reversibility. In this paper we propose a new neural network architecture for learning time-reversible dynamical systems from data. We focus in particular on an adaptation to symplectic systems, because of their importance in physics-informed learning.