 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClifford Group Equivariant Diffusion Models for 3D Molecular Generation
Apr 22, 2025This paper explores leveraging the Clifford algebra's expressive power for $\E(n)$-equivariant diffusion models. We utilize the geometric products between Clifford multivectors and the rich geometric information encoded in Clifford subspaces in \emph{Clifford Diffusion Models} (CDMs). We extend the diffusion process beyond just Clifford one-vectors to incorporate all higher-grade multivector subspaces. The data is embedded in grade-$k$ subspaces, allowing us to apply latent diffusion across complete multivectors. This enables CDMs to capture the joint distribution across different subspaces of the algebra, incorporating richer geometric information through higher-order features. We provide empirical results for unconditional molecular generation on the QM9 dataset, showing that CDMs provide a promising avenue for generative modeling.
On the Importance of Embedding Norms in Self-Supervised Learning
Feb 13, 2025Self-supervised learning (SSL) allows training data representations without a supervised signal and has become an important paradigm in machine learning. Most SSL methods employ the cosine similarity between embedding vectors and hence effectively embed data on a hypersphere. While this seemingly implies that embedding norms cannot play any role in SSL, a few recent works have suggested that embedding norms have properties related to network convergence and confidence. In this paper, we resolve this apparent contradiction and systematically establish the embedding norm's role in SSL training. Using theoretical analysis, simulations, and experiments, we show that embedding norms (i) govern SSL convergence rates and (ii) encode network confidence, with smaller norms corresponding to unexpected samples. Additionally, we show that manipulating embedding norms can have large effects on convergence speed. Our findings demonstrate that SSL embedding norms are integral to understanding and optimizing network behavior.
On the Utility of Equivariance and Symmetry Breaking in Deep Learning Architectures on Point Clouds
Jan 01, 2025This paper explores the key factors that influence the performance of models working with point clouds, across different tasks of varying geometric complexity. In this work, we explore the trade-offs between flexibility and weight-sharing introduced by equivariant layers, assessing when equivariance boosts or detracts from performance. It is often argued that providing more information as input improves a model's performance. However, if this additional information breaks certain properties, such as $\SE(3)$ equivariance, does it remain beneficial? We identify the key aspects of equivariant and non-equivariant architectures that drive success in different tasks by benchmarking them on segmentation, regression, and generation tasks across multiple datasets with increasing complexity. We observe a positive impact of equivariance, which becomes more pronounced with increasing task complexity, even when strict equivariance is not required.
Learning Symmetries via Weight-Sharing with Doubly Stochastic Tensors
Dec 05, 2024Group equivariance has emerged as a valuable inductive bias in deep learning, enhancing generalization, data efficiency, and robustness. Classically, group equivariant methods require the groups of interest to be known beforehand, which may not be realistic for real-world data. Additionally, baking in fixed group equivariance may impose overly restrictive constraints on model architecture. This highlights the need for methods that can dynamically discover and apply symmetries as soft constraints. For neural network architectures, equivariance is commonly achieved through group transformations of a canonical weight tensor, resulting in weight sharing over a given group $G$. In this work, we propose to learn such a weight-sharing scheme by defining a collection of learnable doubly stochastic matrices that act as soft permutation matrices on canonical weight tensors, which can take regular group representations as a special case. This yields learnable kernel transformations that are jointly optimized with downstream tasks. We show that when the dataset exhibits strong symmetries, the permutation matrices will converge to regular group representations and our weight-sharing networks effectively become regular group convolutions. Additionally, the flexibility of the method enables it to effectively pick up on partial symmetries.
* 19 pages, 14 figures, 4 tables
ICML Topological Deep Learning Challenge 2024: Beyond the Graph Domain
Sep 08, 2024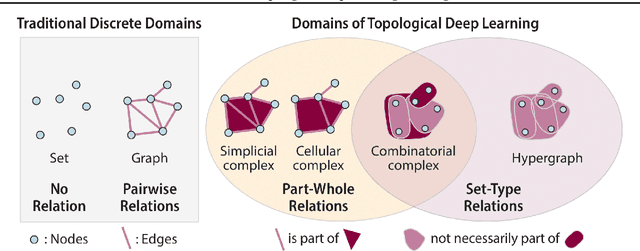
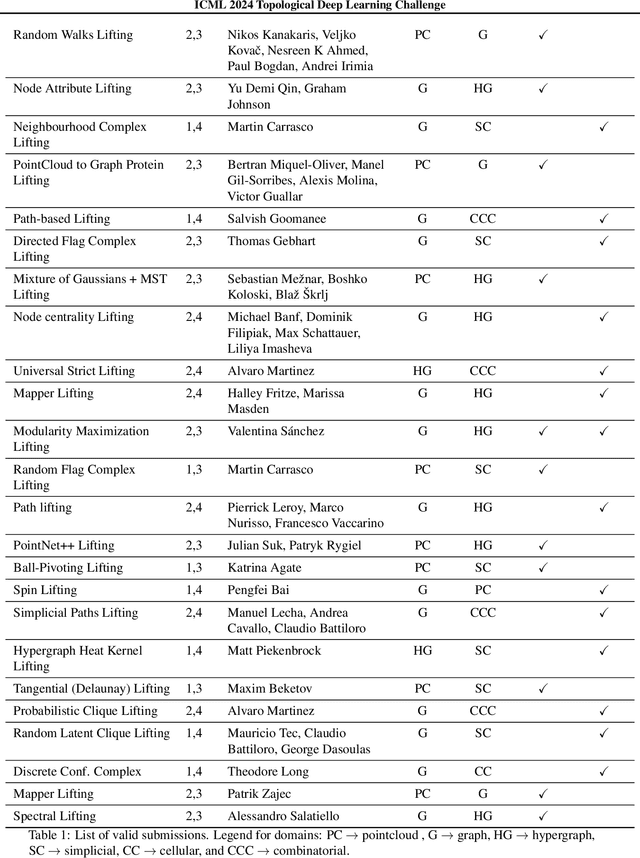
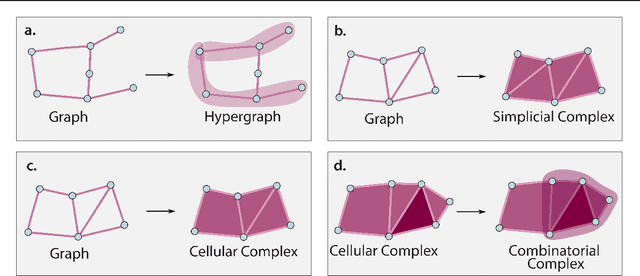
This paper describes the 2nd edition of the ICML Topological Deep Learning Challenge that was hosted within the ICML 2024 ELLIS Workshop on Geometry-grounded Representation Learning and Generative Modeling (GRaM). The challenge focused on the problem of representing data in different discrete topological domains in order to bridge the gap between Topological Deep Learning (TDL) and other types of structured datasets (e.g. point clouds, graphs). Specifically, participants were asked to design and implement topological liftings, i.e. mappings between different data structures and topological domains --like hypergraphs, or simplicial/cell/combinatorial complexes. The challenge received 52 submissions satisfying all the requirements. This paper introduces the main scope of the challenge, and summarizes the main results and findings.
The Hidden Pitfalls of the Cosine Similarity Loss
Jun 24, 2024We show that the gradient of the cosine similarity between two points goes to zero in two under-explored settings: (1) if a point has large magnitude or (2) if the points are on opposite ends of the latent space. Counterintuitively, we prove that optimizing the cosine similarity between points forces them to grow in magnitude. Thus, (1) is unavoidable in practice. We then observe that these derivations are extremely general -- they hold across deep learning architectures and for many of the standard self-supervised learning (SSL) loss functions. This leads us to propose cut-initialization: a simple change to network initialization that helps all studied SSL methods converge faster.
Grounding Continuous Representations in Geometry: Equivariant Neural Fields
Jun 11, 2024



Recently, Neural Fields have emerged as a powerful modelling paradigm to represent continuous signals. In a conditional neural field, a field is represented by a latent variable that conditions the NeF, whose parametrisation is otherwise shared over an entire dataset. We propose Equivariant Neural Fields based on cross attention transformers, in which NeFs are conditioned on a geometric conditioning variable, a latent point cloud, that enables an equivariant decoding from latent to field. Our equivariant approach induces a steerability property by which both field and latent are grounded in geometry and amenable to transformation laws if the field transforms, the latent represents transforms accordingly and vice versa. Crucially, the equivariance relation ensures that the latent is capable of (1) representing geometric patterns faitfhully, allowing for geometric reasoning in latent space, (2) weightsharing over spatially similar patterns, allowing for efficient learning of datasets of fields. These main properties are validated using classification experiments and a verification of the capability of fitting entire datasets, in comparison to other non-equivariant NeF approaches. We further validate the potential of ENFs by demonstrate unique local field editing properties.
Fast, Expressive SE$(n)$ Equivariant Networks through Weight-Sharing in Position-Orientation Space
Oct 04, 2023



Based on the theory of homogeneous spaces we derive \textit{geometrically optimal edge attributes} to be used within the flexible message passing framework. We formalize the notion of weight sharing in convolutional networks as the sharing of message functions over point-pairs that should be treated equally. We define equivalence classes of point-pairs that are identical up to a transformation in the group and derive attributes that uniquely identify these classes. Weight sharing is then obtained by conditioning message functions on these attributes. As an application of the theory, we develop an efficient equivariant group convolutional network for processing 3D point clouds. The theory of homogeneous spaces tells us how to do group convolutions with feature maps over the homogeneous space of positions $\mathbb{R}^3$, position and orientations $\mathbb{R}^3 {\times} S^2$, and the group SE$(3)$ itself. Among these, $\mathbb{R}^3 {\times} S^2$ is an optimal choice due to the ability to represent directional information, which $\mathbb{R}^3$ methods cannot, and it significantly enhances computational efficiency compared to indexing features on the full SE$(3)$ group. We empirically support this claim by reaching state-of-the-art results -- in accuracy and speed -- on three different benchmarks: interatomic potential energy prediction, trajectory forecasting in N-body systems, and generating molecules via equivariant diffusion models.