 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDream to Manipulate: Compositional World Models Empowering Robot Imitation Learning with Imagination
Dec 19, 2024A world model provides an agent with a representation of its environment, enabling it to predict the causal consequences of its actions. Current world models typically cannot directly and explicitly imitate the actual environment in front of a robot, often resulting in unrealistic behaviors and hallucinations that make them unsuitable for real-world applications. In this paper, we introduce a new paradigm for constructing world models that are explicit representations of the real world and its dynamics. By integrating cutting-edge advances in real-time photorealism with Gaussian Splatting and physics simulators, we propose the first compositional manipulation world model, which we call DreMa. DreMa replicates the observed world and its dynamics, allowing it to imagine novel configurations of objects and predict the future consequences of robot actions. We leverage this capability to generate new data for imitation learning by applying equivariant transformations to a small set of demonstrations. Our evaluations across various settings demonstrate significant improvements in both accuracy and robustness by incrementing actions and object distributions, reducing the data needed to learn a policy and improving the generalization of the agents. As a highlight, we show that a real Franka Emika Panda robot, powered by DreMa's imagination, can successfully learn novel physical tasks from just a single example per task variation (one-shot policy learning). Our project page and source code can be found in https://leobarcellona.github.io/DreamToManipulate/
From MLP to NeoMLP: Leveraging Self-Attention for Neural Fields
Dec 11, 2024Neural fields (NeFs) have recently emerged as a state-of-the-art method for encoding spatio-temporal signals of various modalities. Despite the success of NeFs in reconstructing individual signals, their use as representations in downstream tasks, such as classification or segmentation, is hindered by the complexity of the parameter space and its underlying symmetries, in addition to the lack of powerful and scalable conditioning mechanisms. In this work, we draw inspiration from the principles of connectionism to design a new architecture based on MLPs, which we term NeoMLP. We start from an MLP, viewed as a graph, and transform it from a multi-partite graph to a complete graph of input, hidden, and output nodes, equipped with high-dimensional features. We perform message passing on this graph and employ weight-sharing via self-attention among all the nodes. NeoMLP has a built-in mechanism for conditioning through the hidden and output nodes, which function as a set of latent codes, and as such, NeoMLP can be used straightforwardly as a conditional neural field. We demonstrate the effectiveness of our method by fitting high-resolution signals, including multi-modal audio-visual data. Furthermore, we fit datasets of neural representations, by learning instance-specific sets of latent codes using a single backbone architecture, and then use them for downstream tasks, outperforming recent state-of-the-art methods. The source code is open-sourced at https://github.com/mkofinas/neomlp.
NeuralDEM -- Real-time Simulation of Industrial Particulate Flows
Nov 14, 2024Advancements in computing power have made it possible to numerically simulate large-scale fluid-mechanical and/or particulate systems, many of which are integral to core industrial processes. Among the different numerical methods available, the discrete element method (DEM) provides one of the most accurate representations of a wide range of physical systems involving granular and discontinuous materials. Consequently, DEM has become a widely accepted approach for tackling engineering problems connected to granular flows and powder mechanics. Additionally, DEM can be integrated with grid-based computational fluid dynamics (CFD) methods, enabling the simulation of chemical processes taking place, e.g., in fluidized beds. However, DEM is computationally intensive because of the intrinsic multiscale nature of particulate systems, restricting simulation duration or number of particles. Towards this end, NeuralDEM presents an end-to-end approach to replace slow numerical DEM routines with fast, adaptable deep learning surrogates. NeuralDEM is capable of picturing long-term transport processes across different regimes using macroscopic observables without any reference to microscopic model parameters. First, NeuralDEM treats the Lagrangian discretization of DEM as an underlying continuous field, while simultaneously modeling macroscopic behavior directly as additional auxiliary fields. Second, NeuralDEM introduces multi-branch neural operators scalable to real-time modeling of industrially-sized scenarios - from slow and pseudo-steady to fast and transient. Such scenarios have previously posed insurmountable challenges for deep learning models. Notably, NeuralDEM faithfully models coupled CFD-DEM fluidized bed reactors of 160k CFD cells and 500k DEM particles for trajectories of 28s. NeuralDEM will open many new doors to advanced engineering and much faster process cycles.
NARAIM: Native Aspect Ratio Autoregressive Image Models
Oct 13, 2024
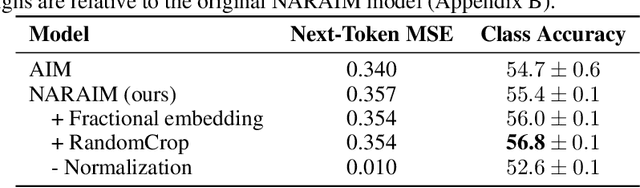
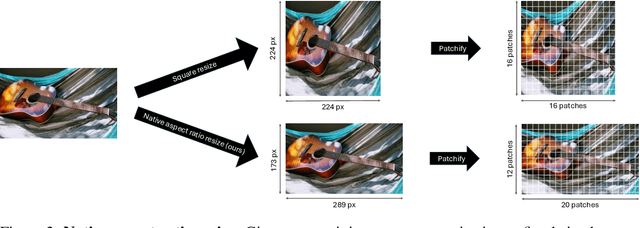
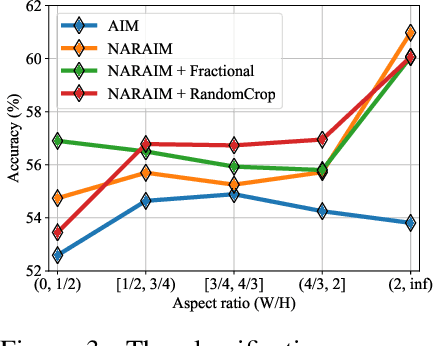
While vision transformers are able to solve a wide variety of computer vision tasks, no pre-training method has yet demonstrated the same scaling laws as observed in language models. Autoregressive models show promising results, but are commonly trained on images that are cropped or transformed into square images, which distorts or destroys information present in the input. To overcome this limitation, we propose NARAIM, a vision model pre-trained with an autoregressive objective that uses images in their native aspect ratio. By maintaining the native aspect ratio, we preserve the original spatial context, thereby enhancing the model's ability to interpret visual information. In our experiments, we show that maintaining the aspect ratio improves performance on a downstream classification task.
Exploring the Effectiveness of Object-Centric Representations in Visual Question Answering: Comparative Insights with Foundation Models
Jul 22, 2024Object-centric (OC) representations, which represent the state of a visual scene by modeling it as a composition of objects, have the potential to be used in various downstream tasks to achieve systematic compositional generalization and facilitate reasoning. However, these claims have not been thoroughly analyzed yet. Recently, foundation models have demonstrated unparalleled capabilities across diverse domains from language to computer vision, marking them as a potential cornerstone of future research for a multitude of computational tasks. In this paper, we conduct an extensive empirical study on representation learning for downstream Visual Question Answering (VQA), which requires an accurate compositional understanding of the scene. We thoroughly investigate the benefits and trade-offs of OC models and alternative approaches including large pre-trained foundation models on both synthetic and real-world data, and demonstrate a viable way to achieve the best of both worlds. The extensiveness of our study, encompassing over 800 downstream VQA models and 15 different types of upstream representations, also provides several additional insights that we believe will be of interest to the community at large.
Grounding Continuous Representations in Geometry: Equivariant Neural Fields
Jun 11, 2024



Recently, Neural Fields have emerged as a powerful modelling paradigm to represent continuous signals. In a conditional neural field, a field is represented by a latent variable that conditions the NeF, whose parametrisation is otherwise shared over an entire dataset. We propose Equivariant Neural Fields based on cross attention transformers, in which NeFs are conditioned on a geometric conditioning variable, a latent point cloud, that enables an equivariant decoding from latent to field. Our equivariant approach induces a steerability property by which both field and latent are grounded in geometry and amenable to transformation laws if the field transforms, the latent represents transforms accordingly and vice versa. Crucially, the equivariance relation ensures that the latent is capable of (1) representing geometric patterns faitfhully, allowing for geometric reasoning in latent space, (2) weightsharing over spatially similar patterns, allowing for efficient learning of datasets of fields. These main properties are validated using classification experiments and a verification of the capability of fitting entire datasets, in comparison to other non-equivariant NeF approaches. We further validate the potential of ENFs by demonstrate unique local field editing properties.
Space-Time Continuous PDE Forecasting using Equivariant Neural Fields
Jun 10, 2024



Recently, Conditional Neural Fields (NeFs) have emerged as a powerful modelling paradigm for PDEs, by learning solutions as flows in the latent space of the Conditional NeF. Although benefiting from favourable properties of NeFs such as grid-agnosticity and space-time-continuous dynamics modelling, this approach limits the ability to impose known constraints of the PDE on the solutions -- e.g. symmetries or boundary conditions -- in favour of modelling flexibility. Instead, we propose a space-time continuous NeF-based solving framework that - by preserving geometric information in the latent space - respects known symmetries of the PDE. We show that modelling solutions as flows of pointclouds over the group of interest $G$ improves generalization and data-efficiency. We validated that our framework readily generalizes to unseen spatial and temporal locations, as well as geometric transformations of the initial conditions - where other NeF-based PDE forecasting methods fail - and improve over baselines in a number of challenging geometries.
Nodule detection and generation on chest X-rays: NODE21 Challenge
Jan 04, 2024



Pulmonary nodules may be an early manifestation of lung cancer, the leading cause of cancer-related deaths among both men and women. Numerous studies have established that deep learning methods can yield high-performance levels in the detection of lung nodules in chest X-rays. However, the lack of gold-standard public datasets slows down the progression of the research and prevents benchmarking of methods for this task. To address this, we organized a public research challenge, NODE21, aimed at the detection and generation of lung nodules in chest X-rays. While the detection track assesses state-of-the-art nodule detection systems, the generation track determines the utility of nodule generation algorithms to augment training data and hence improve the performance of the detection systems. This paper summarizes the results of the NODE21 challenge and performs extensive additional experiments to examine the impact of the synthetically generated nodule training images on the detection algorithm performance.
How to Train Neural Field Representations: A Comprehensive Study and Benchmark
Dec 16, 2023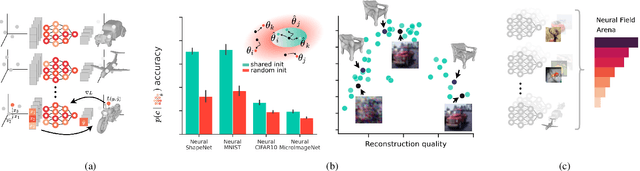
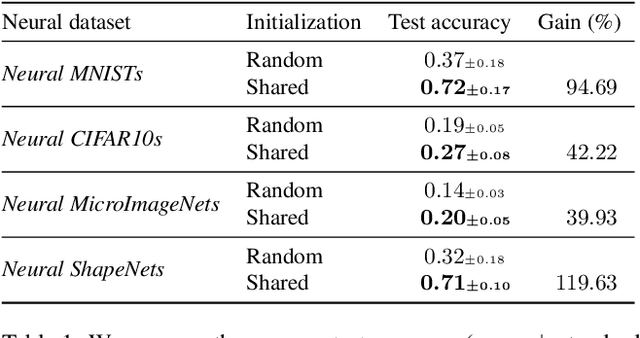


Neural fields (NeFs) have recently emerged as a versatile method for modeling signals of various modalities, including images, shapes, and scenes. Subsequently, a number of works have explored the use of NeFs as representations for downstream tasks, e.g. classifying an image based on the parameters of a NeF that has been fit to it. However, the impact of the NeF hyperparameters on their quality as downstream representation is scarcely understood and remains largely unexplored. This is in part caused by the large amount of time required to fit datasets of neural fields. In this work, we propose $\verb|fit-a-nef|$, a JAX-based library that leverages parallelization to enable fast optimization of large-scale NeF datasets, resulting in a significant speed-up. With this library, we perform a comprehensive study that investigates the effects of different hyperparameters -- including initialization, network architecture, and optimization strategies -- on fitting NeFs for downstream tasks. Our study provides valuable insights on how to train NeFs and offers guidance for optimizing their effectiveness in downstream applications. Finally, based on the proposed library and our analysis, we propose Neural Field Arena, a benchmark consisting of neural field variants of popular vision datasets, including MNIST, CIFAR, variants of ImageNet, and ShapeNetv2. Our library and the Neural Field Arena will be open-sourced to introduce standardized benchmarking and promote further research on neural fields.
Neural Modulation Fields for Conditional Cone Beam Neural Tomography
Jul 17, 2023



Conventional Computed Tomography (CT) methods require large numbers of noise-free projections for accurate density reconstructions, limiting their applicability to the more complex class of Cone Beam Geometry CT (CBCT) reconstruction. Recently, deep learning methods have been proposed to overcome these limitations, with methods based on neural fields (NF) showing strong performance, by approximating the reconstructed density through a continuous-in-space coordinate based neural network. Our focus is on improving such methods, however, unlike previous work, which requires training an NF from scratch for each new set of projections, we instead propose to leverage anatomical consistencies over different scans by training a single conditional NF on a dataset of projections. We propose a novel conditioning method where local modulations are modeled per patient as a field over the input domain through a Neural Modulation Field (NMF). The resulting Conditional Cone Beam Neural Tomography (CondCBNT) shows improved performance for both high and low numbers of available projections on noise-free and noisy data.