 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Geometrically Grounded Lorentz Neural Networks
Jan 29, 2026Hyperbolic space is quickly gaining traction as a promising geometry for hierarchical and robust representation learning. A core open challenge is the development of a mathematical formulation of hyperbolic neural networks that is both efficient and captures the key properties of hyperbolic space. The Lorentz model of hyperbolic space has been shown to enable both fast forward and backward propagation. However, we prove that, with the current formulation of Lorentz linear layers, the hyperbolic norms of the outputs scale logarithmically with the number of gradient descent steps, nullifying the key advantage of hyperbolic geometry. We propose a new Lorentz linear layer grounded in the well-known ``distance-to-hyperplane" formulation. We prove that our formulation results in the usual linear scaling of output hyperbolic norms with respect to the number of gradient descent steps. Our new formulation, together with further algorithmic efficiencies through Lorentzian activation functions and a new caching strategy results in neural networks fully abiding by hyperbolic geometry while simultaneously bridging the computation gap to Euclidean neural networks. Code available at: https://github.com/robertdvdk/hyperbolic-fully-connected.
Reproducibility study of "LICO: Explainable Models with Language-Image Consistency"
Oct 17, 2024
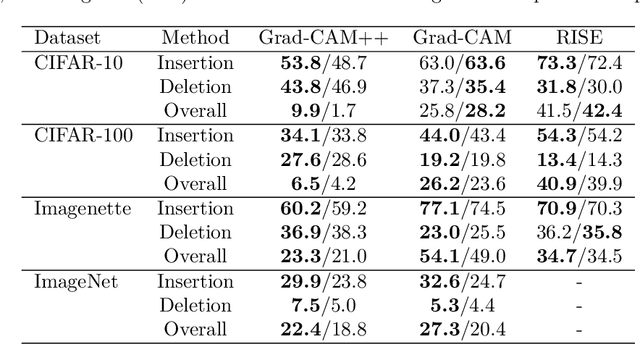


The growing reproducibility crisis in machine learning has brought forward a need for careful examination of research findings. This paper investigates the claims made by Lei et al. (2023) regarding their proposed method, LICO, for enhancing post-hoc interpretability techniques and improving image classification performance. LICO leverages natural language supervision from a vision-language model to enrich feature representations and guide the learning process. We conduct a comprehensive reproducibility study, employing (Wide) ResNets and established interpretability methods like Grad-CAM and RISE. We were mostly unable to reproduce the authors' results. In particular, we did not find that LICO consistently led to improved classification performance or improvements in quantitative and qualitative measures of interpretability. Thus, our findings highlight the importance of rigorous evaluation and transparent reporting in interpretability research.
* 15 pages, 2 figures, Machine Learning Reproducibility Challenge 2024
NARAIM: Native Aspect Ratio Autoregressive Image Models
Oct 13, 2024
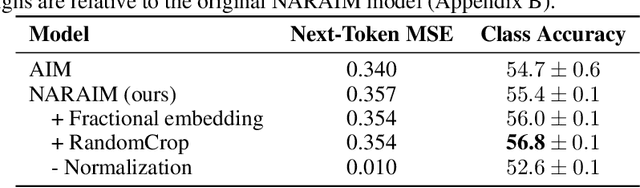
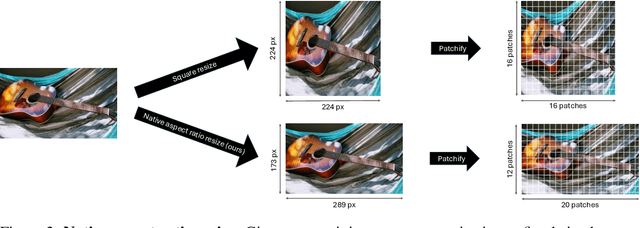
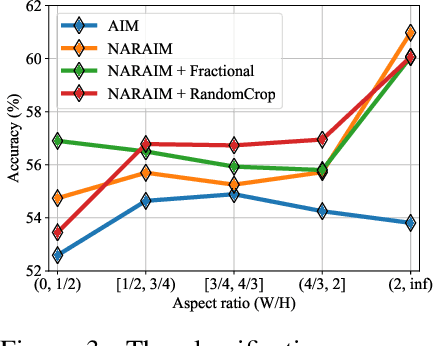
While vision transformers are able to solve a wide variety of computer vision tasks, no pre-training method has yet demonstrated the same scaling laws as observed in language models. Autoregressive models show promising results, but are commonly trained on images that are cropped or transformed into square images, which distorts or destroys information present in the input. To overcome this limitation, we propose NARAIM, a vision model pre-trained with an autoregressive objective that uses images in their native aspect ratio. By maintaining the native aspect ratio, we preserve the original spatial context, thereby enhancing the model's ability to interpret visual information. In our experiments, we show that maintaining the aspect ratio improves performance on a downstream classification task.
PDiscoNet: Semantically consistent part discovery for fine-grained recognition
Sep 06, 2023



Fine-grained classification often requires recognizing specific object parts, such as beak shape and wing patterns for birds. Encouraging a fine-grained classification model to first detect such parts and then using them to infer the class could help us gauge whether the model is indeed looking at the right details better than with interpretability methods that provide a single attribution map. We propose PDiscoNet to discover object parts by using only image-level class labels along with priors encouraging the parts to be: discriminative, compact, distinct from each other, equivariant to rigid transforms, and active in at least some of the images. In addition to using the appropriate losses to encode these priors, we propose to use part-dropout, where full part feature vectors are dropped at once to prevent a single part from dominating in the classification, and part feature vector modulation, which makes the information coming from each part distinct from the perspective of the classifier. Our results on CUB, CelebA, and PartImageNet show that the proposed method provides substantially better part discovery performance than previous methods while not requiring any additional hyper-parameter tuning and without penalizing the classification performance. The code is available at https://github.com/robertdvdk/part_detection.