 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeeting SLOs, Slashing Hours: Automated Enterprise LLM Optimization with OptiKIT
Jan 28, 2026Enterprise LLM deployment faces a critical scalability challenge: organizations must optimize models systematically to scale AI initiatives within constrained compute budgets, yet the specialized expertise required for manual optimization remains a niche and scarce skillset. This challenge is particularly evident in managing GPU utilization across heterogeneous infrastructure while enabling teams with diverse workloads and limited LLM optimization experience to deploy models efficiently. We present OptiKIT, a distributed LLM optimization framework that democratizes model compression and tuning by automating complex optimization workflows for non-expert teams. OptiKIT provides dynamic resource allocation, staged pipeline execution with automatic cleanup, and seamless enterprise integration. In production, it delivers more than 2x GPU throughput improvement while empowering application teams to achieve consistent performance improvements without deep LLM optimization expertise. We share both the platform design and key engineering insights into resource allocation algorithms, pipeline orchestration, and integration patterns that enable large-scale, production-grade democratization of model optimization. Finally, we open-source the system to enable external contributions and broader reproducibility.
Unilogit: Robust Machine Unlearning for LLMs Using Uniform-Target Self-Distillation
May 09, 2025



This paper introduces Unilogit, a novel self-distillation method for machine unlearning in Large Language Models. Unilogit addresses the challenge of selectively forgetting specific information while maintaining overall model utility, a critical task in compliance with data privacy regulations like GDPR. Unlike prior methods that rely on static hyperparameters or starting model outputs, Unilogit dynamically adjusts target logits to achieve a uniform probability for the target token, leveraging the current model's outputs for more accurate self-distillation targets. This approach not only eliminates the need for additional hyperparameters but also enhances the model's ability to approximate the golden targets. Extensive experiments on public benchmarks and an in-house e-commerce dataset demonstrate Unilogit's superior performance in balancing forget and retain objectives, outperforming state-of-the-art methods such as NPO and UnDIAL. Our analysis further reveals Unilogit's robustness across various scenarios, highlighting its practical applicability and effectiveness in achieving efficacious machine unlearning.
ClusComp: A Simple Paradigm for Model Compression and Efficient Finetuning
Mar 17, 2025



As large language models (LLMs) scale, model compression is crucial for edge deployment and accessibility. Weight-only quantization reduces model size but suffers from performance degradation at lower bit widths. Moreover, standard finetuning is incompatible with quantized models, and alternative methods often fall short of full finetuning. In this paper, we propose ClusComp, a simple yet effective compression paradigm that clusters weight matrices into codebooks and finetunes them block-by-block. ClusComp (1) achieves superior performance in 2-4 bit quantization, (2) pushes compression to 1-bit while outperforming ultra-low-bit methods with minimal finetuning, and (3) enables efficient finetuning, even surpassing existing quantization-based approaches and rivaling full FP16 finetuning. Notably, ClusComp supports compression and finetuning of 70B LLMs on a single A6000-48GB GPU.
Reproducibility study of "LICO: Explainable Models with Language-Image Consistency"
Oct 17, 2024
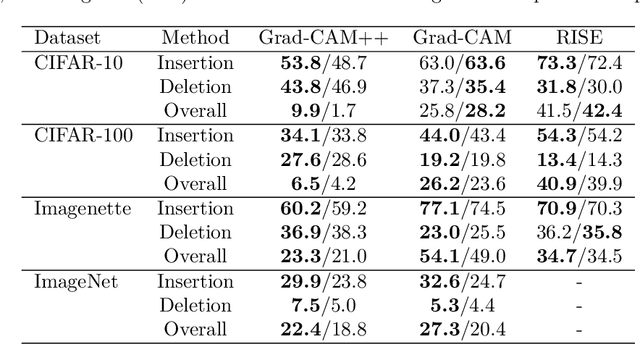


The growing reproducibility crisis in machine learning has brought forward a need for careful examination of research findings. This paper investigates the claims made by Lei et al. (2023) regarding their proposed method, LICO, for enhancing post-hoc interpretability techniques and improving image classification performance. LICO leverages natural language supervision from a vision-language model to enrich feature representations and guide the learning process. We conduct a comprehensive reproducibility study, employing (Wide) ResNets and established interpretability methods like Grad-CAM and RISE. We were mostly unable to reproduce the authors' results. In particular, we did not find that LICO consistently led to improved classification performance or improvements in quantitative and qualitative measures of interpretability. Thus, our findings highlight the importance of rigorous evaluation and transparent reporting in interpretability research.
* 15 pages, 2 figures, Machine Learning Reproducibility Challenge 2024