 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Vision-Language Models for E-commerce Understanding at Scale
Feb 12, 2026E-commerce product understanding demands by nature, strong multimodal comprehension from text, images, and structured attributes. General-purpose Vision-Language Models (VLMs) enable generalizable multimodal latent modelling, yet there is no documented, well-known strategy for adapting them to the attribute-centric, multi-image, and noisy nature of e-commerce data, without sacrificing general performance. In this work, we show through a large-scale experimental study, how targeted adaptation of general VLMs can substantially improve e-commerce performance while preserving broad multimodal capabilities. Furthermore, we propose a novel extensive evaluation suite covering deep product understanding, strict instruction following, and dynamic attribute extraction.
Unilogit: Robust Machine Unlearning for LLMs Using Uniform-Target Self-Distillation
May 09, 2025



This paper introduces Unilogit, a novel self-distillation method for machine unlearning in Large Language Models. Unilogit addresses the challenge of selectively forgetting specific information while maintaining overall model utility, a critical task in compliance with data privacy regulations like GDPR. Unlike prior methods that rely on static hyperparameters or starting model outputs, Unilogit dynamically adjusts target logits to achieve a uniform probability for the target token, leveraging the current model's outputs for more accurate self-distillation targets. This approach not only eliminates the need for additional hyperparameters but also enhances the model's ability to approximate the golden targets. Extensive experiments on public benchmarks and an in-house e-commerce dataset demonstrate Unilogit's superior performance in balancing forget and retain objectives, outperforming state-of-the-art methods such as NPO and UnDIAL. Our analysis further reveals Unilogit's robustness across various scenarios, highlighting its practical applicability and effectiveness in achieving efficacious machine unlearning.
CONGRAD:Conflicting Gradient Filtering for Multilingual Preference Alignment
Mar 31, 2025Naive joint training of large language models (LLMs) for multilingual preference alignment can suffer from negative interference. This is a known issue in multilingual training, where conflicting objectives degrade overall performance. However, the impact of this phenomenon in the context of multilingual preference alignment remains largely underexplored. To address this issue, we propose CONGRAD, a scalable and effective filtering method that selects high-quality preference samples with minimal gradient conflicts across languages. Our method leverages gradient surgery to retain samples aligned with an aggregated multilingual update direction. Additionally, we incorporate a sublinear gradient compression strategy that reduces memory overhead during gradient accumulation. We integrate CONGRAD into self-rewarding framework and evaluate on LLaMA3-8B and Gemma2-2B across 10 languages. Results show that CONGRAD consistently outperforms strong baselines in both seen and unseen languages, with minimal alignment tax.
ClusComp: A Simple Paradigm for Model Compression and Efficient Finetuning
Mar 17, 2025



As large language models (LLMs) scale, model compression is crucial for edge deployment and accessibility. Weight-only quantization reduces model size but suffers from performance degradation at lower bit widths. Moreover, standard finetuning is incompatible with quantized models, and alternative methods often fall short of full finetuning. In this paper, we propose ClusComp, a simple yet effective compression paradigm that clusters weight matrices into codebooks and finetunes them block-by-block. ClusComp (1) achieves superior performance in 2-4 bit quantization, (2) pushes compression to 1-bit while outperforming ultra-low-bit methods with minimal finetuning, and (3) enables efficient finetuning, even surpassing existing quantization-based approaches and rivaling full FP16 finetuning. Notably, ClusComp supports compression and finetuning of 70B LLMs on a single A6000-48GB GPU.
Domain Adaptation of Foundation LLMs for e-Commerce
Jan 16, 2025We present the e-Llama models: 8 billion and 70 billion parameter large language models that are adapted towards the e-commerce domain. These models are meant as foundation models with deep knowledge about e-commerce, that form a base for instruction- and fine-tuning. The e-Llama models are obtained by continuously pretraining the Llama 3.1 base models on 1 trillion tokens of domain-specific data. We discuss our approach and motivate our choice of hyperparameters with a series of ablation studies. To quantify how well the models have been adapted to the e-commerce domain, we define and implement a set of multilingual, e-commerce specific evaluation tasks. We show that, when carefully choosing the training setup, the Llama 3.1 models can be adapted towards the new domain without sacrificing significant performance on general domain tasks. We also explore the possibility of merging the adapted model and the base model for a better control of the performance trade-off between domains.
IKUN for WMT24 General MT Task: LLMs Are here for Multilingual Machine Translation
Aug 21, 2024



This paper introduces two multilingual systems, IKUN and IKUN-C, developed for the general machine translation task in WMT24. IKUN and IKUN-C represent an open system and a constrained system, respectively, built on Llama-3-8b and Mistral-7B-v0.3. Both systems are designed to handle all 11 language directions using a single model. According to automatic evaluation metrics, IKUN-C achieved 6 first-place and 3 second-place finishes among all constrained systems, while IKUN secured 1 first-place and 2 second-place finishes across both open and constrained systems. These encouraging results suggest that large language models (LLMs) are nearing the level of proficiency required for effective multilingual machine translation. The systems are based on a two-stage approach: first, continuous pre-training on monolingual data in 10 languages, followed by fine-tuning on high-quality parallel data for 11 language directions. The primary difference between IKUN and IKUN-C lies in their monolingual pre-training strategy. IKUN-C is pre-trained using constrained monolingual data, whereas IKUN leverages monolingual data from the OSCAR dataset. In the second phase, both systems are fine-tuned on parallel data sourced from NTREX, Flores, and WMT16-23 for all 11 language pairs.
LiLiuM: eBay's Large Language Models for e-commerce
Jun 17, 2024



We introduce the LiLiuM series of large language models (LLMs): 1B, 7B, and 13B parameter models developed 100% in-house to fit eBay's specific needs in the e-commerce domain. This gives eBay full control over all aspects of the models including license, data, vocabulary, and architecture. We expect these models to be used as a foundation for fine-tuning and instruction-tuning, eliminating dependencies to external models. The LiLiuM LLMs have been trained on 3 trillion tokens of multilingual text from general and e-commerce domain. They perform similar to the popular LLaMA-2 models on English natural language understanding (NLU) benchmarks. At the same time, we outperform LLaMA-2 on non-English NLU tasks, machine translation and on e-commerce specific downstream tasks. As part of our data mixture, we utilize the newly released RedPajama-V2 dataset for training and share our insights regarding data filtering and deduplication. We also discuss in detail how to serialize structured data for use in autoregressive language modeling. We provide insights on the effects of including code and parallel machine translation data in pre-training. Furthermore, we develop our own tokenizer and model vocabulary, customized towards e-commerce. This way, we can achieve up to 34% speed-up in text generation on eBay-specific downstream tasks compared to LLaMA-2. Finally, in relation to LLM pretraining, we show that checkpoint averaging can further improve over the best individual model checkpoint.
Document-Level Language Models for Machine Translation
Oct 18, 2023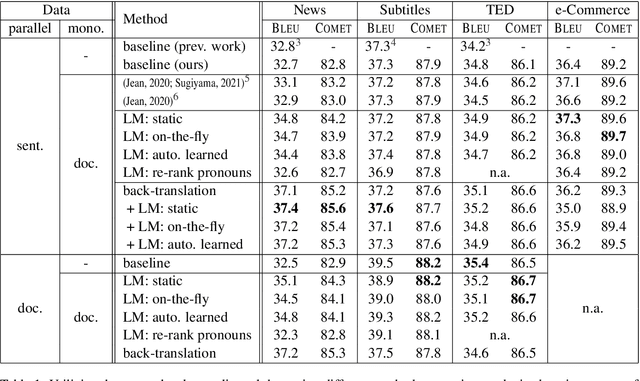
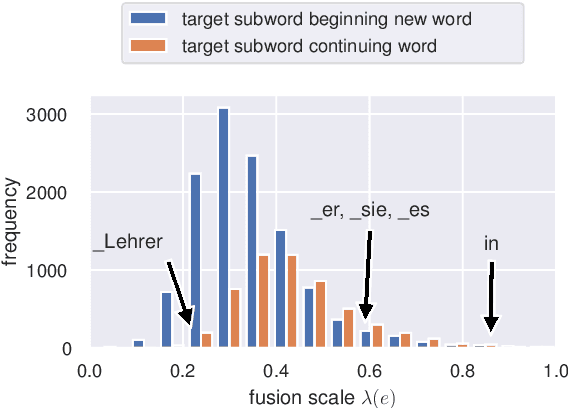
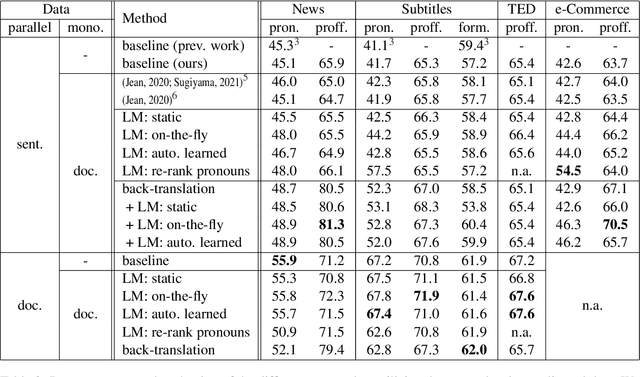
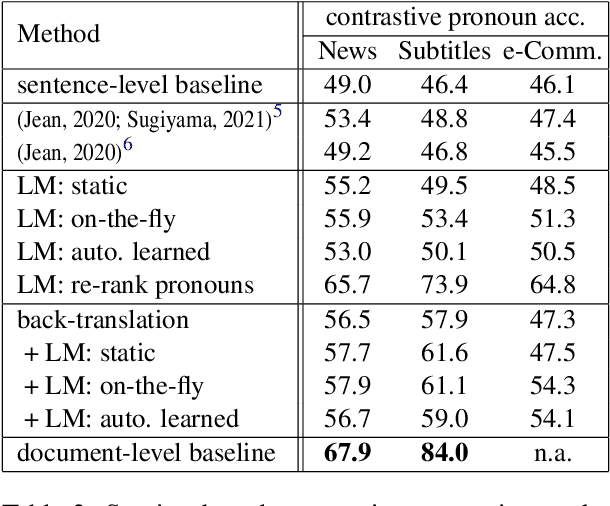
Despite the known limitations, most machine translation systems today still operate on the sentence-level. One reason for this is, that most parallel training data is only sentence-level aligned, without document-level meta information available. In this work, we set out to build context-aware translation systems utilizing document-level monolingual data instead. This can be achieved by combining any existing sentence-level translation model with a document-level language model. We improve existing approaches by leveraging recent advancements in model combination. Additionally, we propose novel weighting techniques that make the system combination more flexible and significantly reduce computational overhead. In a comprehensive evaluation on four diverse translation tasks, we show that our extensions improve document-targeted scores substantially and are also computationally more efficient. However, we also find that in most scenarios, back-translation gives even better results, at the cost of having to re-train the translation system. Finally, we explore language model fusion in the light of recent advancements in large language models. Our findings suggest that there might be strong potential in utilizing large language models via model combination.
On Search Strategies for Document-Level Neural Machine Translation
Jun 08, 2023Compared to sentence-level systems, document-level neural machine translation (NMT) models produce a more consistent output across a document and are able to better resolve ambiguities within the input. There are many works on document-level NMT, mostly focusing on modifying the model architecture or training strategy to better accommodate the additional context-input. On the other hand, in most works, the question on how to perform search with the trained model is scarcely discussed, sometimes not mentioned at all. In this work, we aim to answer the question how to best utilize a context-aware translation model in decoding. We start with the most popular document-level NMT approach and compare different decoding schemes, some from the literature and others proposed by us. In the comparison, we are using both, standard automatic metrics, as well as specific linguistic phenomena on three standard document-level translation benchmarks. We find that most commonly used decoding strategies perform similar to each other and that higher quality context information has the potential to further improve the translation.
Improving Long Context Document-Level Machine Translation
Jun 08, 2023Document-level context for neural machine translation (NMT) is crucial to improve the translation consistency and cohesion, the translation of ambiguous inputs, as well as several other linguistic phenomena. Many works have been published on the topic of document-level NMT, but most restrict the system to only local context, typically including just the one or two preceding sentences as additional information. This might be enough to resolve some ambiguous inputs, but it is probably not sufficient to capture some document-level information like the topic or style of a conversation. When increasing the context size beyond just the local context, there are two challenges: (i) the~memory usage increases exponentially (ii) the translation performance starts to degrade. We argue that the widely-used attention mechanism is responsible for both issues. Therefore, we propose a constrained attention variant that focuses the attention on the most relevant parts of the sequence, while simultaneously reducing the memory consumption. For evaluation, we utilize targeted test sets in combination with novel evaluation techniques to analyze the translations in regards to specific discourse-related phenomena. We find that our approach is a good compromise between sentence-level NMT vs attending to the full context, especially in low resource scenarios.