 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptation of Foundation LLMs for e-Commerce
Jan 16, 2025We present the e-Llama models: 8 billion and 70 billion parameter large language models that are adapted towards the e-commerce domain. These models are meant as foundation models with deep knowledge about e-commerce, that form a base for instruction- and fine-tuning. The e-Llama models are obtained by continuously pretraining the Llama 3.1 base models on 1 trillion tokens of domain-specific data. We discuss our approach and motivate our choice of hyperparameters with a series of ablation studies. To quantify how well the models have been adapted to the e-commerce domain, we define and implement a set of multilingual, e-commerce specific evaluation tasks. We show that, when carefully choosing the training setup, the Llama 3.1 models can be adapted towards the new domain without sacrificing significant performance on general domain tasks. We also explore the possibility of merging the adapted model and the base model for a better control of the performance trade-off between domains.
Visual Probing: Cognitive Framework for Explaining Self-Supervised Image Representations
Jun 21, 2021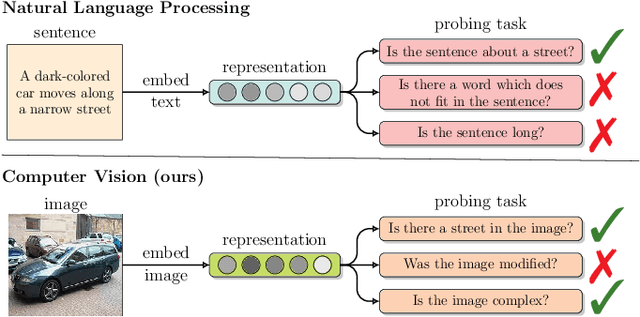
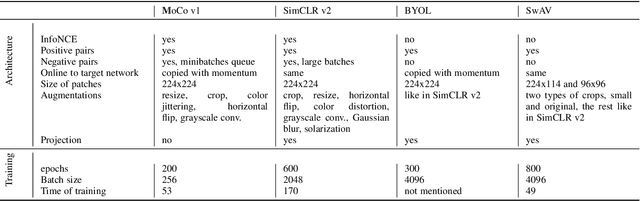
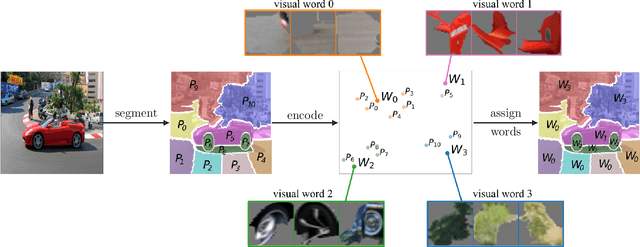
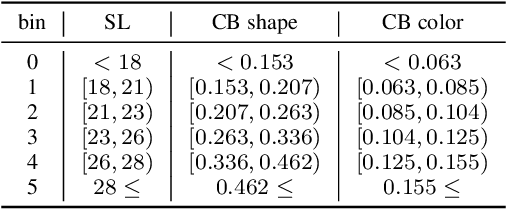
Recently introduced self-supervised methods for image representation learning provide on par or superior results to their fully supervised competitors, yet the corresponding efforts to explain the self-supervised approaches lag behind. Motivated by this observation, we introduce a novel visual probing framework for explaining the self-supervised models by leveraging probing tasks employed previously in natural language processing. The probing tasks require knowledge about semantic relationships between image parts. Hence, we propose a systematic approach to obtain analogs of natural language in vision, such as visual words, context, and taxonomy. Our proposal is grounded in Marr's computational theory of vision and concerns features like textures, shapes, and lines. We show the effectiveness and applicability of those analogs in the context of explaining self-supervised representations. Our key findings emphasize that relations between language and vision can serve as an effective yet intuitive tool for discovering how machine learning models work, independently of data modality. Our work opens a plethora of research pathways towards more explainable and transparent AI.
I know why you like this movie: Interpretable Efficient Multimodal Recommender
Jun 09, 2020
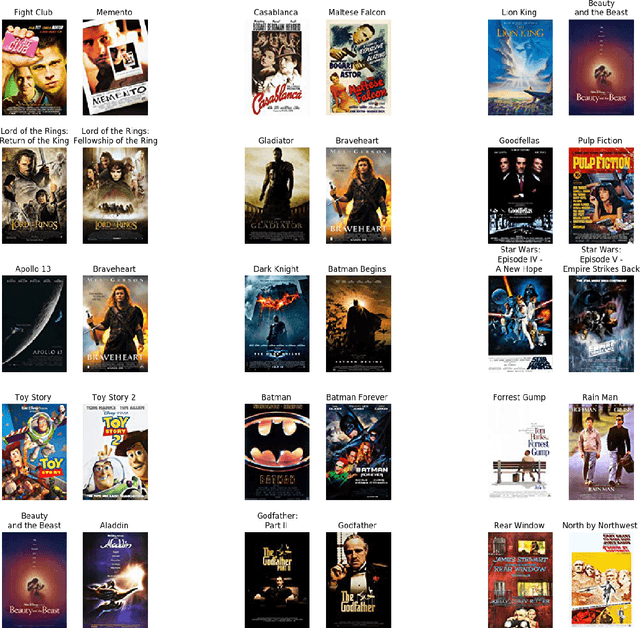


Recently, the Efficient Manifold Density Estimator (EMDE) model has been introduced. The model exploits Local Sensitive Hashing and Count-Min Sketch algorithms, combining them with a neural network to achieve state-of-the-art results on multiple recommender datasets. However, this model ingests a compressed joint representation of all input items for each user/session, so calculating attributions for separate items via gradient-based methods seems not applicable. We prove that interpreting this model in a white-box setting is possible thanks to the properties of EMDE item retrieval method. By exploiting multimodal flexibility of this model, we obtain meaningful results showing the influence of multiple modalities: text, categorical features, and images, on movie recommendation output.
An efficient manifold density estimator for all recommendation systems
Jun 05, 2020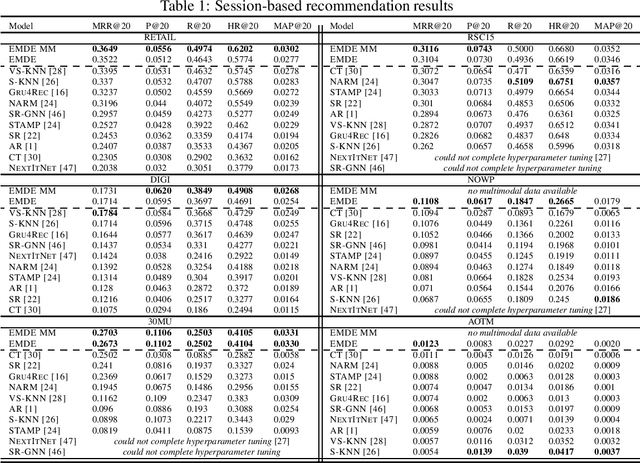
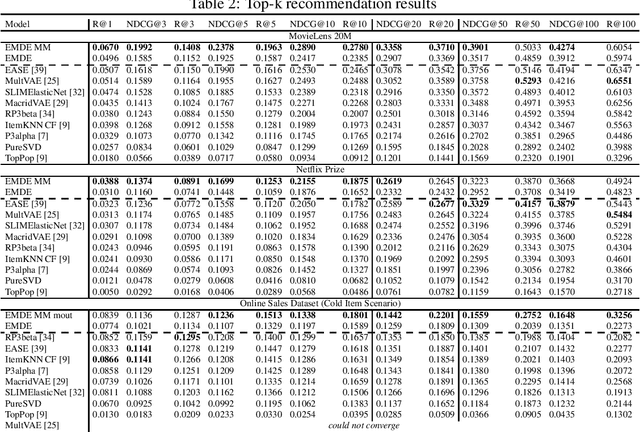

Many unsupervised representation learning methods belong to the class of similarity learning models. While various modality-specific approaches exist for different types of data, a core property of many methods is that representations of similar inputs are close under some similarity function. We propose EMDE (Efficient Manifold Density Estimator) - a framework utilizing arbitrary vector representations with the property of local similarity to succinctly represent smooth probability densities on Riemannian manifolds. Our approximate representation has the desirable properties of being fixed-size and having simple additive compositionality, thus being especially amenable to treatment with neural networks - both as input and output format, producing efficient conditional estimators. We generalize and reformulate the problem of multi-modal recommendations as conditional, weighted density estimation on manifolds. Our approach allows for trivial inclusion of multiple interaction types, modalities of data as well as interaction strengths for any recommendation setting. Applying EMDE to both top-k and session-based recommendation settings, we establish new state-of-the-art results on multiple open datasets in both uni-modal and multi-modal settings. We release the source code and our own real-world dataset of e-commerce product purchases, with special focus on modeling of the item cold-start problem.
Can Your Context-Aware MT System Pass the DiP Benchmark Tests? : Evaluation Benchmarks for Discourse Phenomena in Machine Translation
Apr 30, 2020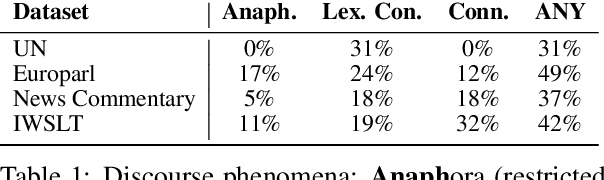


Despite increasing instances of machine translation (MT) systems including contextual information, the evidence for translation quality improvement is sparse, especially for discourse phenomena. Popular metrics like BLEU are not expressive or sensitive enough to capture quality improvements or drops that are minor in size but significant in perception. We introduce the first of their kind MT benchmark datasets that aim to track and hail improvements across four main discourse phenomena: anaphora, lexical consistency, coherence and readability, and discourse connective translation. We also introduce evaluation methods for these tasks, and evaluate several baseline MT systems on the curated datasets. Surprisingly, we find that existing context-aware models do not improve discourse-related translations consistently across languages and phenomena.
Are you tough enough? Framework for Robustness Validation of Machine Comprehension Systems
Dec 05, 2018


Deep Learning NLP domain lacks procedures for the analysis of model robustness. In this paper we propose a framework which validates robustness of any Question Answering model through model explainers. We propose that a robust model should transgress the initial notion of semantic similarity induced by word embeddings to learn a more human-like understanding of meaning. We test this property by manipulating questions in two ways: swapping important question word for 1) its semantically correct synonym and 2) for word vector that is close in embedding space. We estimate importance of words in asked questions with Locally Interpretable Model Agnostic Explanations method (LIME). With these two steps we compare state-of-the-art Q&A models. We show that although accuracy of state-of-the-art models is high, they are very fragile to changes in the input. Moreover, we propose 2 adversarial training scenarios which raise model sensitivity to true synonyms by up to 7% accuracy measure. Our findings help to understand which models are more stable and how they can be improved. In addition, we have created and published a new dataset that may be used for validation of robustness of a Q&A model.
Does it care what you asked? Understanding Importance of Verbs in Deep Learning QA System
Sep 11, 2018
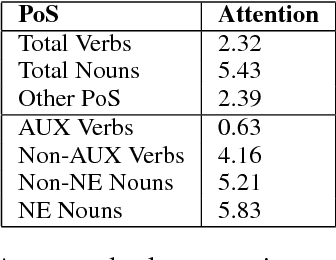
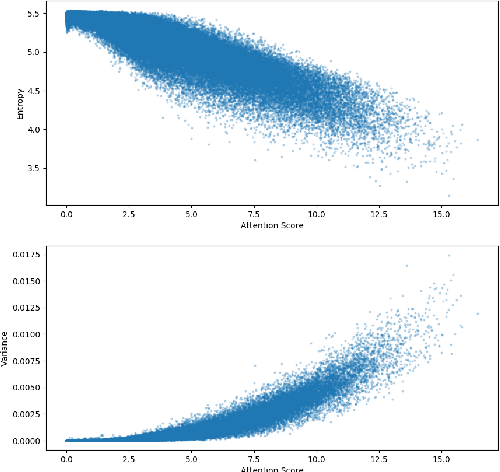
In this paper we present the results of an investigation of the importance of verbs in a deep learning QA system trained on SQuAD dataset. We show that main verbs in questions carry little influence on the decisions made by the system - in over 90% of researched cases swapping verbs for their antonyms did not change system decision. We track this phenomenon down to the insides of the net, analyzing the mechanism of self-attention and values contained in hidden layers of RNN. Finally, we recognize the characteristics of the SQuAD dataset as the source of the problem. Our work refers to the recently popular topic of adversarial examples in NLP, combined with investigating deep net structure.
How much should you ask? On the question structure in QA systems
Sep 11, 2018



Datasets that boosted state-of-the-art solutions for Question Answering (QA) systems prove that it is possible to ask questions in natural language manner. However, users are still used to query-like systems where they type in keywords to search for answer. In this study we validate which parts of questions are essential for obtaining valid answer. In order to conclude that, we take advantage of LIME - a framework that explains prediction by local approximation. We find that grammar and natural language is disregarded by QA. State-of-the-art model can answer properly even if 'asked' only with a few words with high coefficients calculated with LIME. According to our knowledge, it is the first time that QA model is being explained by LIME.