 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Your Context-Aware MT System Pass the DiP Benchmark Tests? : Evaluation Benchmarks for Discourse Phenomena in Machine Translation
Paper and Code
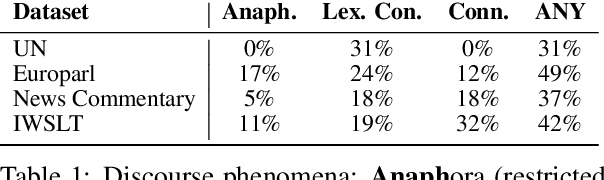

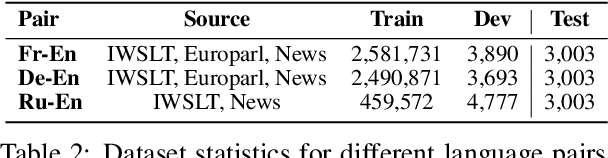

Despite increasing instances of machine translation (MT) systems including contextual information, the evidence for translation quality improvement is sparse, especially for discourse phenomena. Popular metrics like BLEU are not expressive or sensitive enough to capture quality improvements or drops that are minor in size but significant in perception. We introduce the first of their kind MT benchmark datasets that aim to track and hail improvements across four main discourse phenomena: anaphora, lexical consistency, coherence and readability, and discourse connective translation. We also introduce evaluation methods for these tasks, and evaluate several baseline MT systems on the curated datasets. Surprisingly, we find that existing context-aware models do not improve discourse-related translations consistently across languages and phenomena.