 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultidimensional Hopfield Networks for clustering
Oct 11, 2023
We present the Multidimensional Hopfield Network (DHN), a natural generalisation of the Hopfield Network. In our theoretical investigations we focus on DHNs with a certain activation function and provide energy functions for them. We conclude that these DHNs are convergent in finite time, and are equivalent to greedy methods that aim to find graph clusterings of locally minimal cuts. We also show that the general framework of DHNs encapsulates several previously known algorithms used for generating graph embeddings and clusterings. Namely, the Cleora graph embedding algorithm, the Louvain method, and the Newmans method can be cast as DHNs with appropriate activation function and update rule. Motivated by these findings we provide a generalisation of Newmans method to the multidimensional case.
Synerise at RecSys 2021: Twitter user engagement prediction with a fast neural model
Sep 28, 2021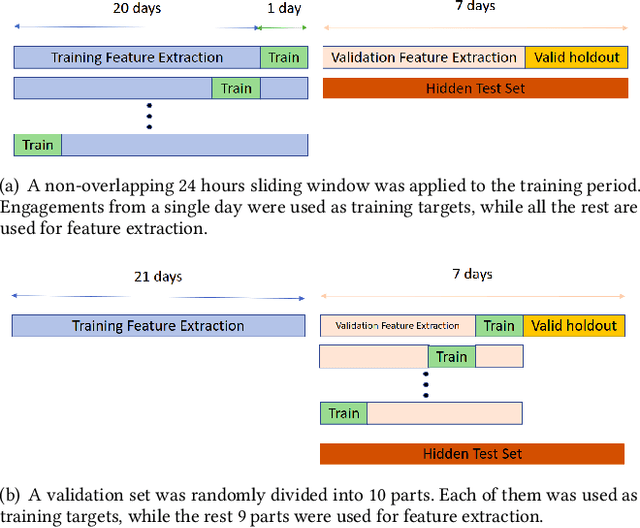


In this paper we present our 2nd place solution to ACM RecSys 2021 Challenge organized by Twitter. The challenge aims to predict user engagement for a set of tweets, offering an exceptionally large data set of 1 billion data points sampled from over four weeks of real Twitter interactions. Each data point contains multiple sources of information, such as tweet text along with engagement features, user features, and tweet features. The challenge brings the problem close to a real production environment by introducing strict latency constraints in the model evaluation phase: the average inference time for single tweet engagement prediction is limited to 6ms on a single CPU core with 64GB memory. Our proposed model relies on extensive feature engineering performed with methods such as the Efficient Manifold Density Estimator (EMDE) - our previously introduced algorithm based on Locality Sensitive Hashing method, and novel Fourier Feature Encoding, among others. In total, we create numerous features describing a user's Twitter account status and the content of a tweet. In order to adhere to the strict latency constraints, the underlying model is a simple residual feed-forward neural network. The system is a variation of our previous methods which proved successful in KDD Cup 2021, WSDM Challenge 2021, and SIGIR eCom Challenge 2020. We release the source code at: https://github.com/Synerise/recsys-challenge-2021
Visual Probing: Cognitive Framework for Explaining Self-Supervised Image Representations
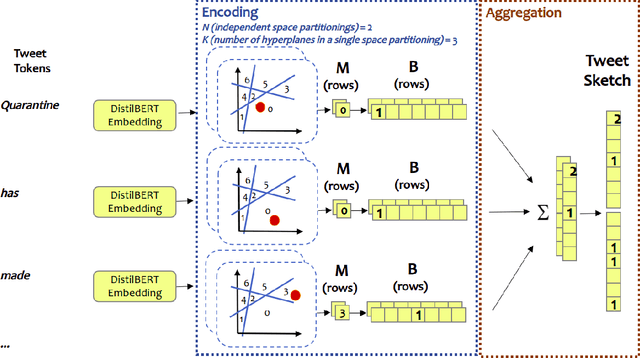
Jun 21, 2021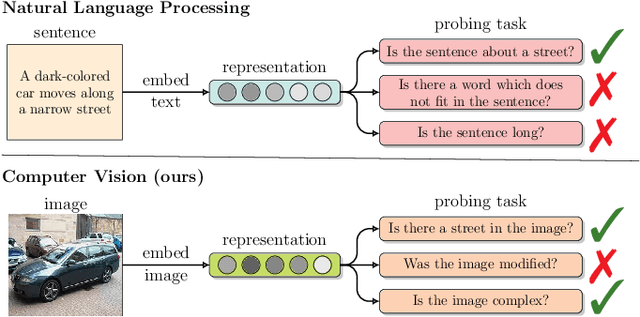
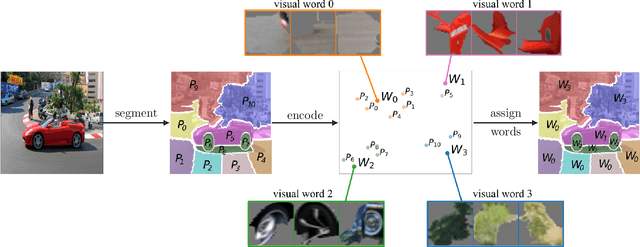
Recently introduced self-supervised methods for image representation learning provide on par or superior results to their fully supervised competitors, yet the corresponding efforts to explain the self-supervised approaches lag behind. Motivated by this observation, we introduce a novel visual probing framework for explaining the self-supervised models by leveraging probing tasks employed previously in natural language processing. The probing tasks require knowledge about semantic relationships between image parts. Hence, we propose a systematic approach to obtain analogs of natural language in vision, such as visual words, context, and taxonomy. Our proposal is grounded in Marr's computational theory of vision and concerns features like textures, shapes, and lines. We show the effectiveness and applicability of those analogs in the context of explaining self-supervised representations. Our key findings emphasize that relations between language and vision can serve as an effective yet intuitive tool for discovering how machine learning models work, independently of data modality. Our work opens a plethora of research pathways towards more explainable and transparent AI.
T-EMDE: Sketching-based global similarity for cross-modal retrieval
May 10, 2021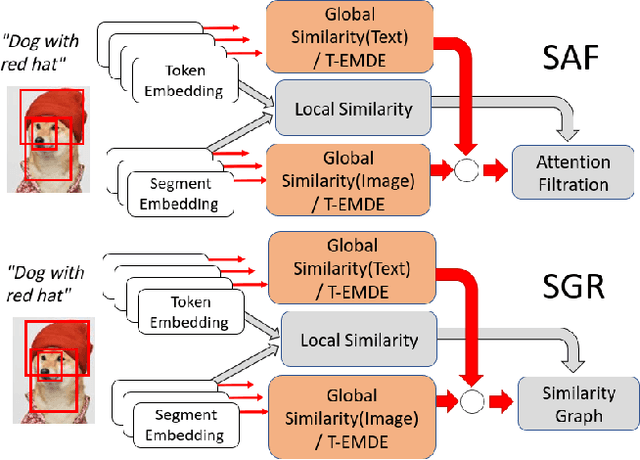
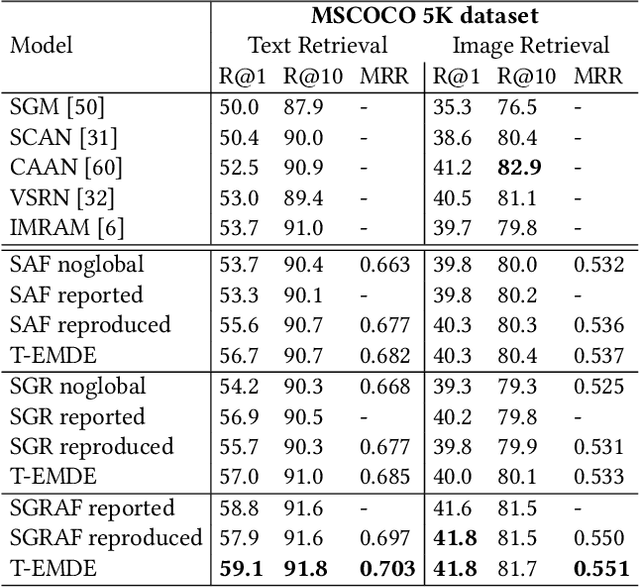
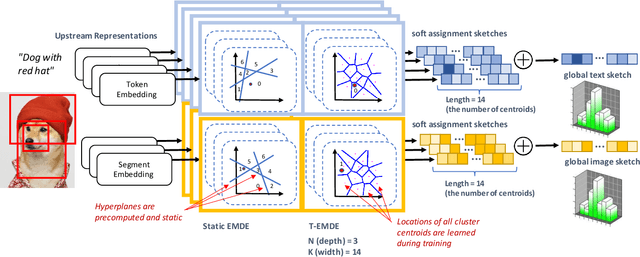
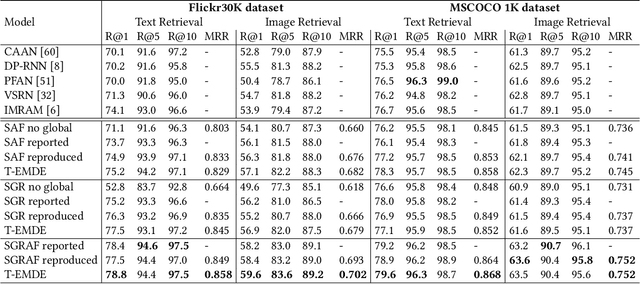
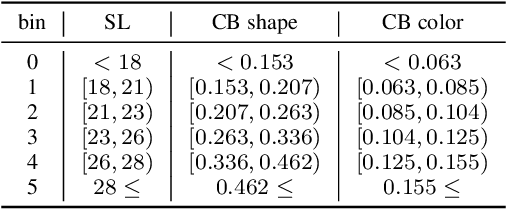
The key challenge in cross-modal retrieval is to find similarities between objects represented with different modalities, such as image and text. However, each modality embeddings stem from non-related feature spaces, which causes the notorious 'heterogeneity gap'. Currently, many cross-modal systems try to bridge the gap with self-attention. However, self-attention has been widely criticized for its quadratic complexity, which prevents many real-life applications. In response to this, we propose T-EMDE - a neural density estimator inspired by the recently introduced Efficient Manifold Density Estimator (EMDE) from the area of recommender systems. EMDE operates on sketches - representations especially suitable for multimodal operations. However, EMDE is non-differentiable and ingests precomputed, static embeddings. With T-EMDE we introduce a trainable version of EMDE which allows full end-to-end training. In contrast to self-attention, the complexity of our solution is linear to the number of tokens/segments. As such, T-EMDE is a drop-in replacement for the self-attention module, with beneficial influence on both speed and metric performance in cross-modal settings. It facilitates communication between modalities, as each global text/image representation is expressed with a standardized sketch histogram which represents the same manifold structures irrespective of the underlying modality. We evaluate T-EMDE by introducing it into two recent cross-modal SOTA models and achieving new state-of-the-art results on multiple datasets and decreasing model latency by up to 20%.
On the Unreasonable Effectiveness of Centroids in Image Retrieval
Apr 28, 2021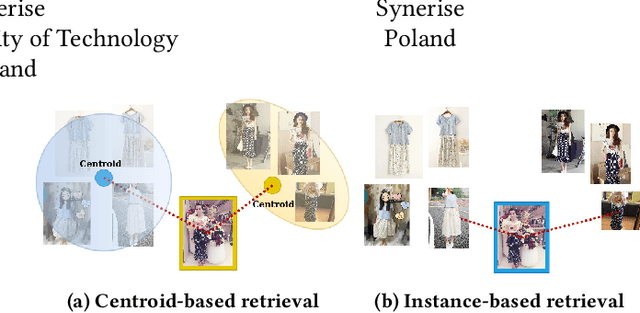
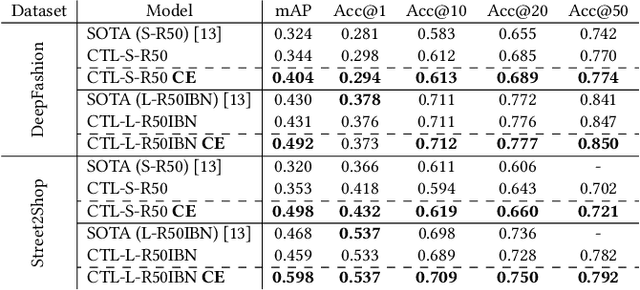
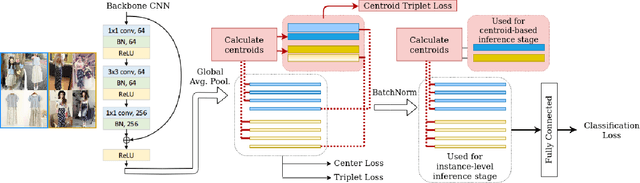
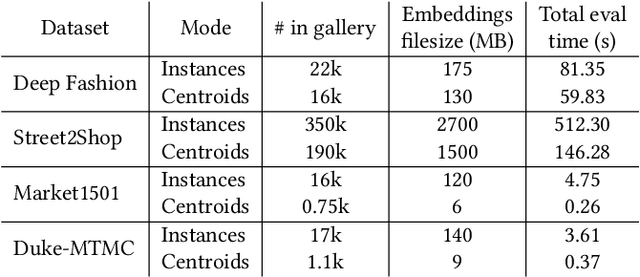
Image retrieval task consists of finding similar images to a query image from a set of gallery (database) images. Such systems are used in various applications e.g. person re-identification (ReID) or visual product search. Despite active development of retrieval models it still remains a challenging task mainly due to large intra-class variance caused by changes in view angle, lighting, background clutter or occlusion, while inter-class variance may be relatively low. A large portion of current research focuses on creating more robust features and modifying objective functions, usually based on Triplet Loss. Some works experiment with using centroid/proxy representation of a class to alleviate problems with computing speed and hard samples mining used with Triplet Loss. However, these approaches are used for training alone and discarded during the retrieval stage. In this paper we propose to use the mean centroid representation both during training and retrieval. Such an aggregated representation is more robust to outliers and assures more stable features. As each class is represented by a single embedding - the class centroid - both retrieval time and storage requirements are reduced significantly. Aggregating multiple embeddings results in a significant reduction of the search space due to lowering the number of candidate target vectors, which makes the method especially suitable for production deployments. Comprehensive experiments conducted on two ReID and Fashion Retrieval datasets demonstrate effectiveness of our method, which outperforms the current state-of-the-art. We propose centroid training and retrieval as a viable method for both Fashion Retrieval and ReID applications.
Modeling Multi-Destination Trips with Sketch-Based Model
Mar 04, 2021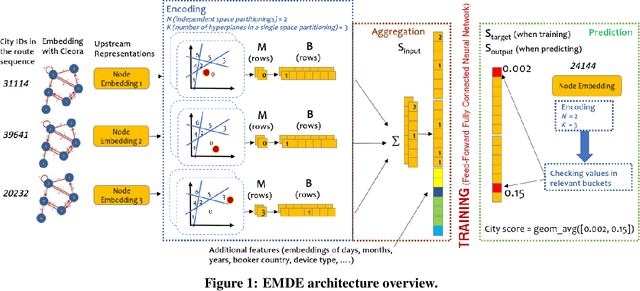
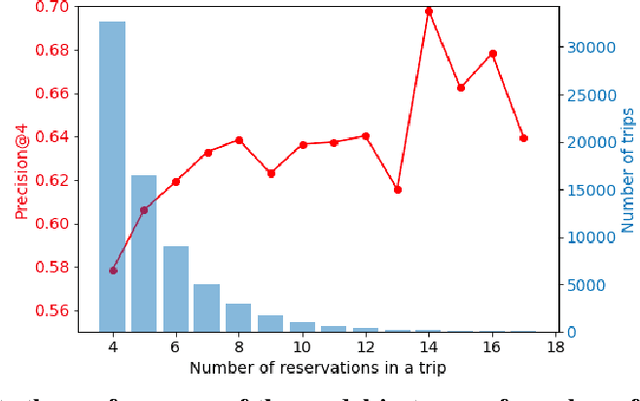

The recently proposed EMDE (Efficient Manifold Density Estimator) model achieves state of-the-art results in session-based recommendation. In this work we explore its application to Booking Data Challenge competition. The aim of the challenge is to make the best recommendation for the next destination of a user trip, based on dataset with millions of real anonymized accommodation reservations. We achieve 2nd place in this competition. First, we use Cleora - our graph embedding method - to represent cities as a directed graph and learn their vector representation. Next, we apply EMDE to predict the next user destination based on previously visited cities and some features associated with each trip. We release the source code at: https://github.com/Synerise/booking-challenge.
Cleora: A Simple, Strong and Scalable Graph Embedding Scheme
Feb 03, 2021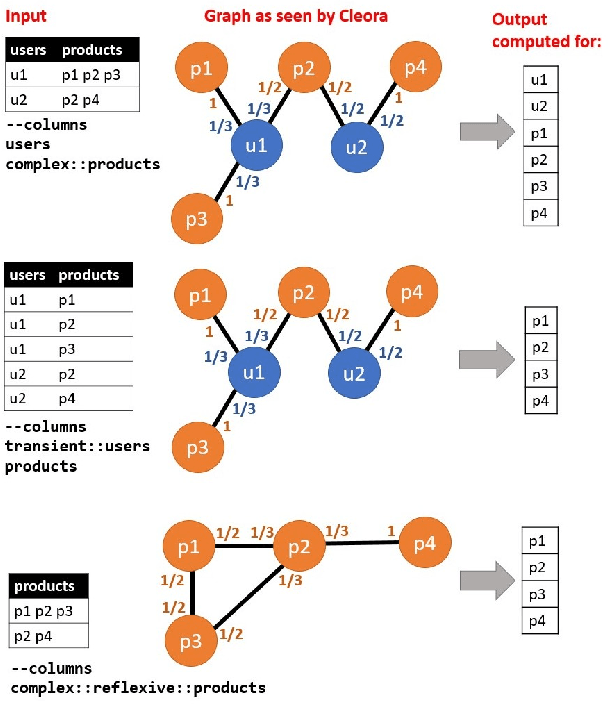
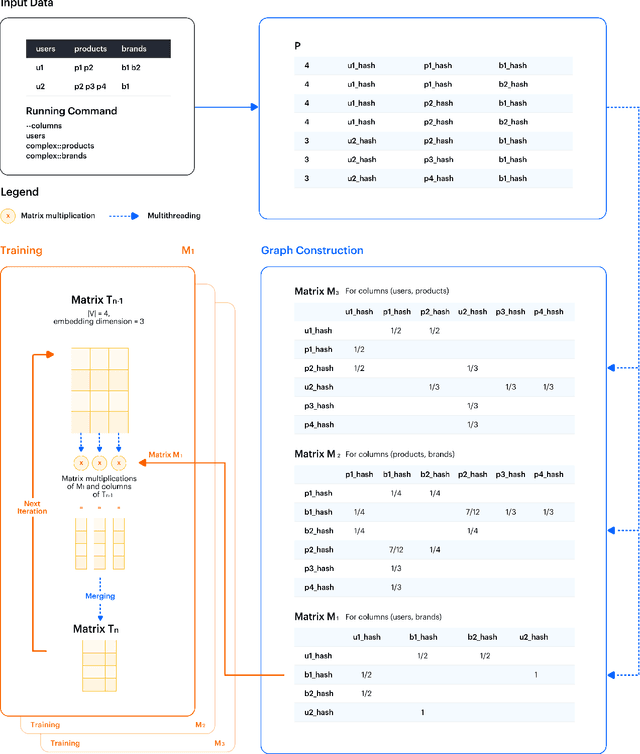
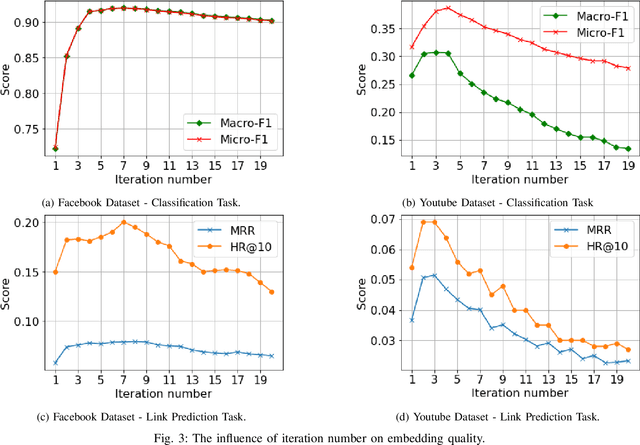
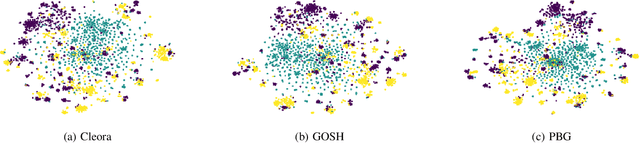
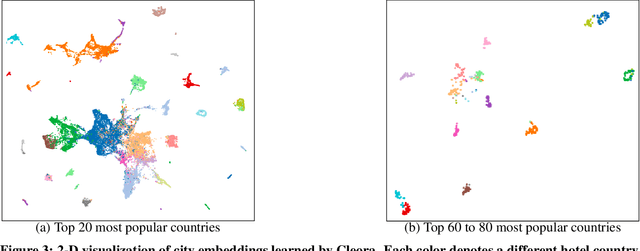
The area of graph embeddings is currently dominated by contrastive learning methods, which demand formulation of an explicit objective function and sampling of positive and negative examples. This creates a conceptual and computational overhead. Simple, classic unsupervised approaches like Multidimensional Scaling (MSD) or the Laplacian eigenmap skip the necessity of tedious objective optimization, directly exploiting data geometry. Unfortunately, their reliance on very costly operations such as matrix eigendecomposition make them unable to scale to large graphs that are common in today's digital world. In this paper we present Cleora: an algorithm which gets the best of two worlds, being both unsupervised and highly scalable. We show that high quality embeddings can be produced without the popular step-wise learning framework with example sampling. An intuitive learning objective of our algorithm is that a node should be similar to its neighbors, without explicitly pushing disconnected nodes apart. The objective is achieved by iterative weighted averaging of node neigbors' embeddings, followed by normalization across dimensions. Thanks to the averaging operation the algorithm makes rapid strides across the embedding space and usually reaches optimal embeddings in just a few iterations. Cleora runs faster than other state-of-the-art CPU algorithms and produces embeddings of competitive quality as measured on downstream tasks: link prediction and node classification. We show that Cleora learns a data abstraction that is similar to contrastive methods, yet at much lower computational cost. We open-source Cleora under the MIT license allowing commercial use under https://github.com/Synerise/cleora.
I know why you like this movie: Interpretable Efficient Multimodal Recommender
Jun 09, 2020


Recently, the Efficient Manifold Density Estimator (EMDE) model has been introduced. The model exploits Local Sensitive Hashing and Count-Min Sketch algorithms, combining them with a neural network to achieve state-of-the-art results on multiple recommender datasets. However, this model ingests a compressed joint representation of all input items for each user/session, so calculating attributions for separate items via gradient-based methods seems not applicable. We prove that interpreting this model in a white-box setting is possible thanks to the properties of EMDE item retrieval method. By exploiting multimodal flexibility of this model, we obtain meaningful results showing the influence of multiple modalities: text, categorical features, and images, on movie recommendation output.
An efficient manifold density estimator for all recommendation systems
Jun 05, 2020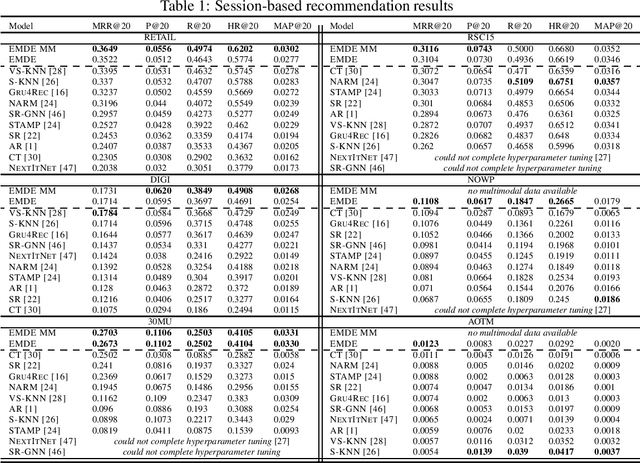
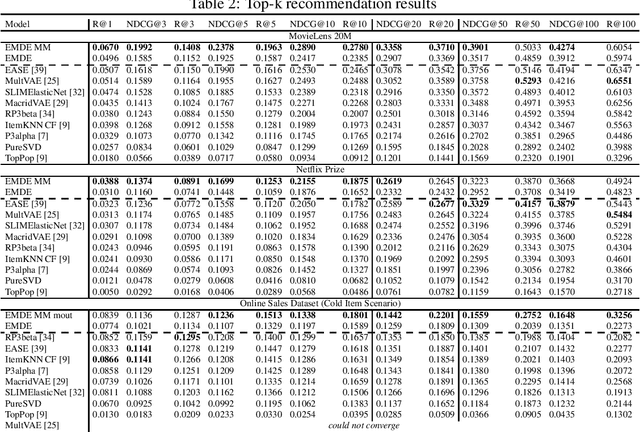

Many unsupervised representation learning methods belong to the class of similarity learning models. While various modality-specific approaches exist for different types of data, a core property of many methods is that representations of similar inputs are close under some similarity function. We propose EMDE (Efficient Manifold Density Estimator) - a framework utilizing arbitrary vector representations with the property of local similarity to succinctly represent smooth probability densities on Riemannian manifolds. Our approximate representation has the desirable properties of being fixed-size and having simple additive compositionality, thus being especially amenable to treatment with neural networks - both as input and output format, producing efficient conditional estimators. We generalize and reformulate the problem of multi-modal recommendations as conditional, weighted density estimation on manifolds. Our approach allows for trivial inclusion of multiple interaction types, modalities of data as well as interaction strengths for any recommendation setting. Applying EMDE to both top-k and session-based recommendation settings, we establish new state-of-the-art results on multiple open datasets in both uni-modal and multi-modal settings. We release the source code and our own real-world dataset of e-commerce product purchases, with special focus on modeling of the item cold-start problem.
Multi-modal Embedding Fusion-based Recommender
May 14, 2020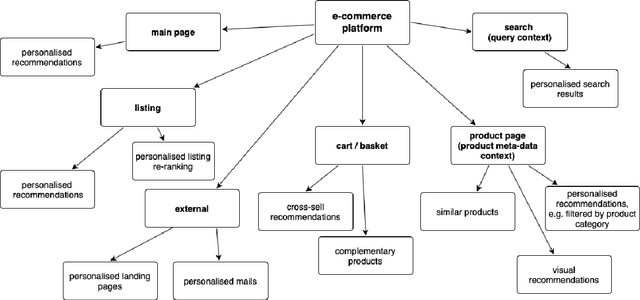
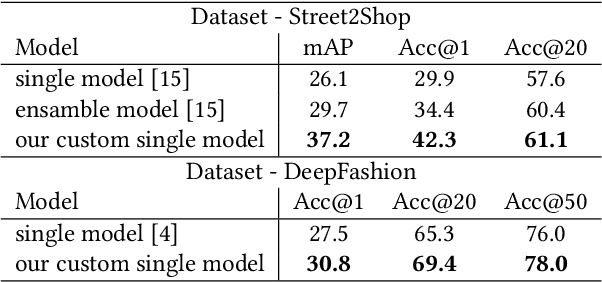
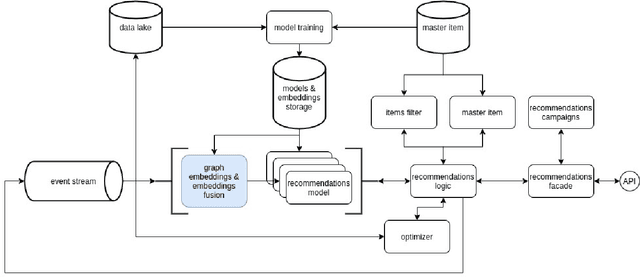
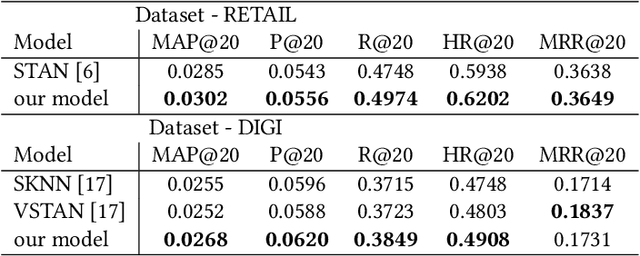
Recommendation systems have lately been popularized globally, with primary use cases in online interaction systems, with significant focus on e-commerce platforms. We have developed a machine learning-based recommendation platform, which can be easily applied to almost any items and/or actions domain. Contrary to existing recommendation systems, our platform supports multiple types of interaction data with multiple modalities of metadata natively. This is achieved through multi-modal fusion of various data representations. We deployed the platform into multiple e-commerce stores of different kinds, e.g. food and beverages, shoes, fashion items, telecom operators. Here, we present our system, its flexibility and performance. We also show benchmark results on open datasets, that significantly outperform state-of-the-art prior work.