 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Unreasonable Effectiveness of Centroids in Image Retrieval
Paper and Code
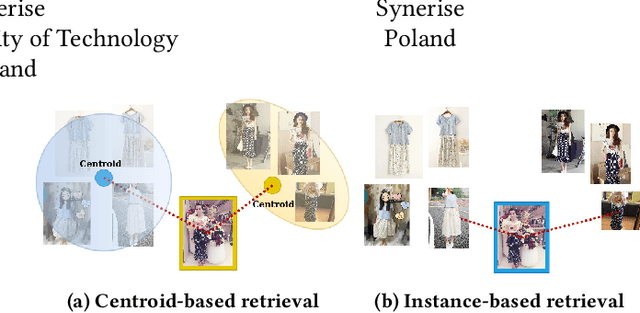
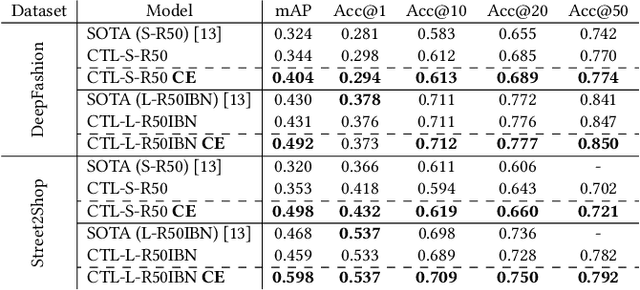
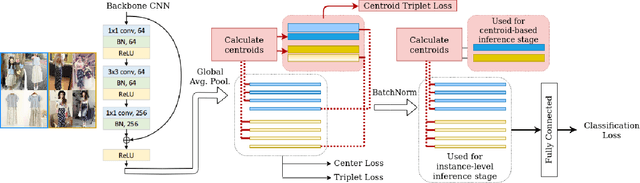
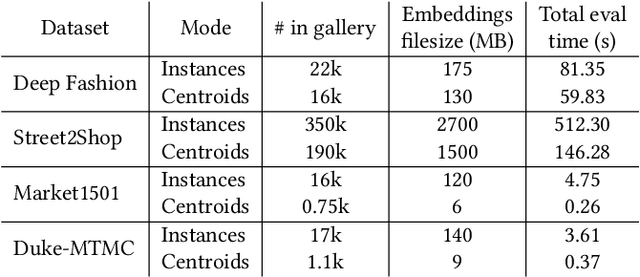
Image retrieval task consists of finding similar images to a query image from a set of gallery (database) images. Such systems are used in various applications e.g. person re-identification (ReID) or visual product search. Despite active development of retrieval models it still remains a challenging task mainly due to large intra-class variance caused by changes in view angle, lighting, background clutter or occlusion, while inter-class variance may be relatively low. A large portion of current research focuses on creating more robust features and modifying objective functions, usually based on Triplet Loss. Some works experiment with using centroid/proxy representation of a class to alleviate problems with computing speed and hard samples mining used with Triplet Loss. However, these approaches are used for training alone and discarded during the retrieval stage. In this paper we propose to use the mean centroid representation both during training and retrieval. Such an aggregated representation is more robust to outliers and assures more stable features. As each class is represented by a single embedding - the class centroid - both retrieval time and storage requirements are reduced significantly. Aggregating multiple embeddings results in a significant reduction of the search space due to lowering the number of candidate target vectors, which makes the method especially suitable for production deployments. Comprehensive experiments conducted on two ReID and Fashion Retrieval datasets demonstrate effectiveness of our method, which outperforms the current state-of-the-art. We propose centroid training and retrieval as a viable method for both Fashion Retrieval and ReID applications.