 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Model Size Matter? A Comparison of Small and Large Language Models for Requirements Classification
Oct 24, 2025[Context and motivation] Large language models (LLMs) show notable results in natural language processing (NLP) tasks for requirements engineering (RE). However, their use is compromised by high computational cost, data sharing risks, and dependence on external services. In contrast, small language models (SLMs) offer a lightweight, locally deployable alternative. [Question/problem] It remains unclear how well SLMs perform compared to LLMs in RE tasks in terms of accuracy. [Results] Our preliminary study compares eight models, including three LLMs and five SLMs, on requirements classification tasks using the PROMISE, PROMISE Reclass, and SecReq datasets. Our results show that although LLMs achieve an average F1 score of 2% higher than SLMs, this difference is not statistically significant. SLMs almost reach LLMs performance across all datasets and even outperform them in recall on the PROMISE Reclass dataset, despite being up to 300 times smaller. We also found that dataset characteristics play a more significant role in performance than model size. [Contribution] Our study contributes with evidence that SLMs are a valid alternative to LLMs for requirements classification, offering advantages in privacy, cost, and local deployability.
T-EMDE: Sketching-based global similarity for cross-modal retrieval
May 10, 2021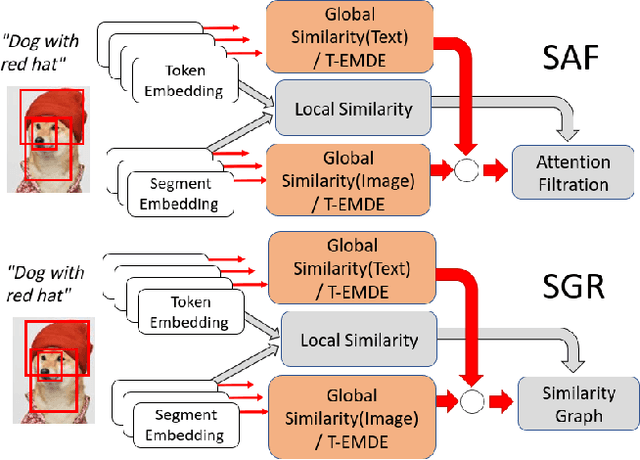
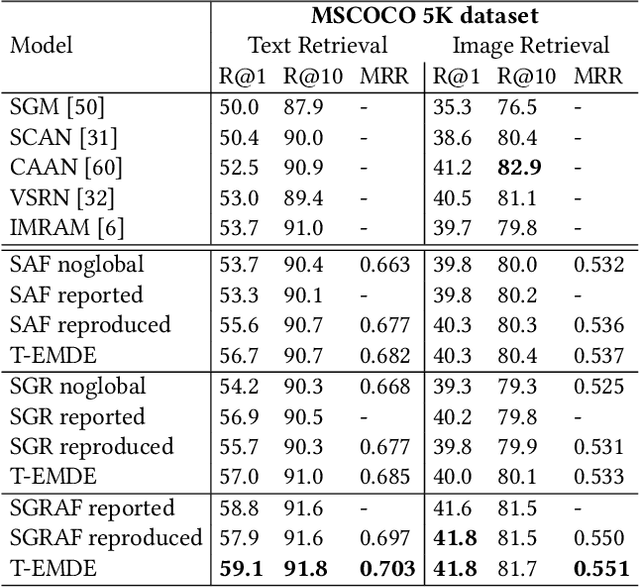
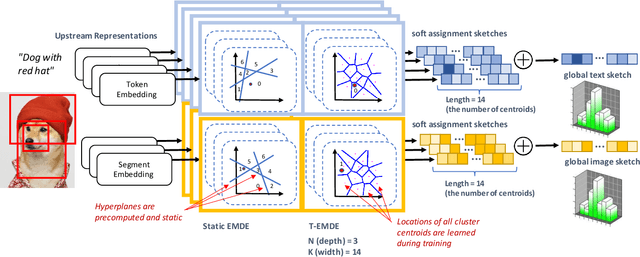
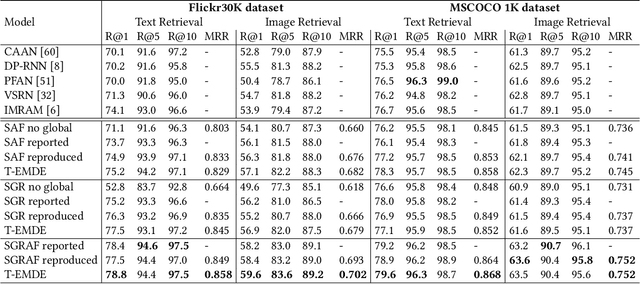
The key challenge in cross-modal retrieval is to find similarities between objects represented with different modalities, such as image and text. However, each modality embeddings stem from non-related feature spaces, which causes the notorious 'heterogeneity gap'. Currently, many cross-modal systems try to bridge the gap with self-attention. However, self-attention has been widely criticized for its quadratic complexity, which prevents many real-life applications. In response to this, we propose T-EMDE - a neural density estimator inspired by the recently introduced Efficient Manifold Density Estimator (EMDE) from the area of recommender systems. EMDE operates on sketches - representations especially suitable for multimodal operations. However, EMDE is non-differentiable and ingests precomputed, static embeddings. With T-EMDE we introduce a trainable version of EMDE which allows full end-to-end training. In contrast to self-attention, the complexity of our solution is linear to the number of tokens/segments. As such, T-EMDE is a drop-in replacement for the self-attention module, with beneficial influence on both speed and metric performance in cross-modal settings. It facilitates communication between modalities, as each global text/image representation is expressed with a standardized sketch histogram which represents the same manifold structures irrespective of the underlying modality. We evaluate T-EMDE by introducing it into two recent cross-modal SOTA models and achieving new state-of-the-art results on multiple datasets and decreasing model latency by up to 20%.
On the Unreasonable Effectiveness of Centroids in Image Retrieval
Apr 28, 2021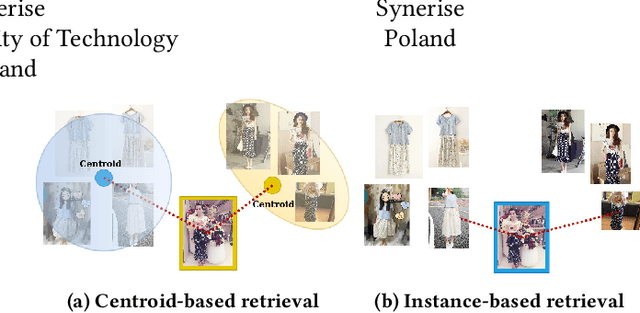
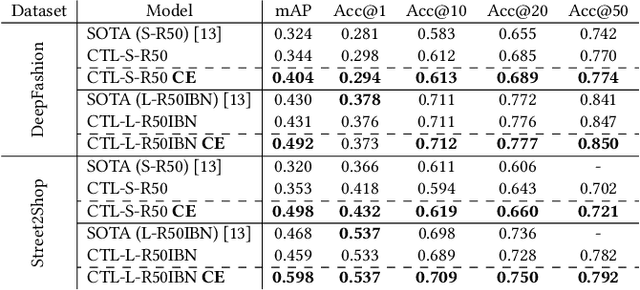
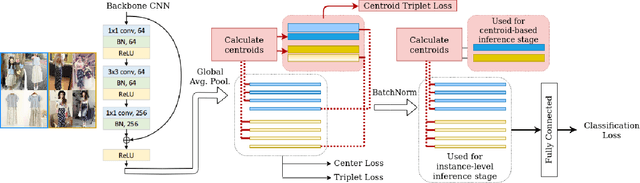
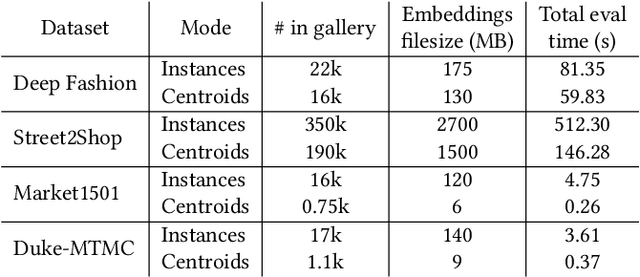
Image retrieval task consists of finding similar images to a query image from a set of gallery (database) images. Such systems are used in various applications e.g. person re-identification (ReID) or visual product search. Despite active development of retrieval models it still remains a challenging task mainly due to large intra-class variance caused by changes in view angle, lighting, background clutter or occlusion, while inter-class variance may be relatively low. A large portion of current research focuses on creating more robust features and modifying objective functions, usually based on Triplet Loss. Some works experiment with using centroid/proxy representation of a class to alleviate problems with computing speed and hard samples mining used with Triplet Loss. However, these approaches are used for training alone and discarded during the retrieval stage. In this paper we propose to use the mean centroid representation both during training and retrieval. Such an aggregated representation is more robust to outliers and assures more stable features. As each class is represented by a single embedding - the class centroid - both retrieval time and storage requirements are reduced significantly. Aggregating multiple embeddings results in a significant reduction of the search space due to lowering the number of candidate target vectors, which makes the method especially suitable for production deployments. Comprehensive experiments conducted on two ReID and Fashion Retrieval datasets demonstrate effectiveness of our method, which outperforms the current state-of-the-art. We propose centroid training and retrieval as a viable method for both Fashion Retrieval and ReID applications.
Multi-modal Embedding Fusion-based Recommender
May 14, 2020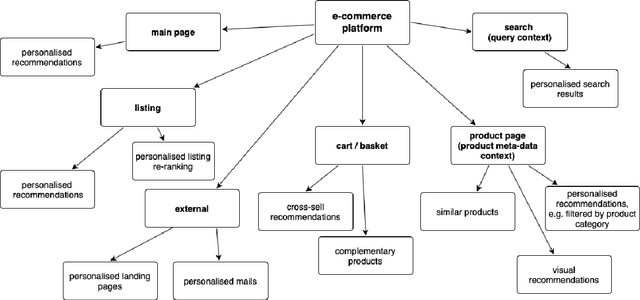
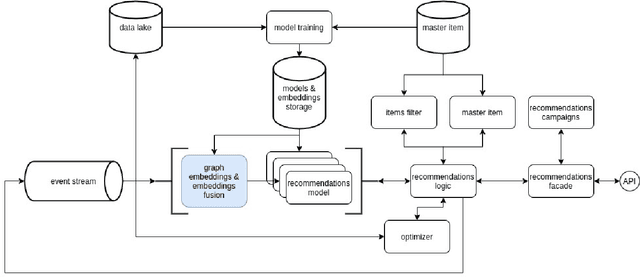
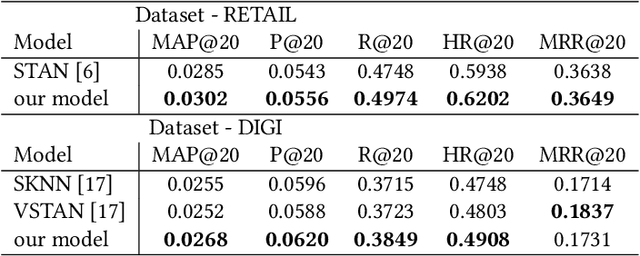
Recommendation systems have lately been popularized globally, with primary use cases in online interaction systems, with significant focus on e-commerce platforms. We have developed a machine learning-based recommendation platform, which can be easily applied to almost any items and/or actions domain. Contrary to existing recommendation systems, our platform supports multiple types of interaction data with multiple modalities of metadata natively. This is achieved through multi-modal fusion of various data representations. We deployed the platform into multiple e-commerce stores of different kinds, e.g. food and beverages, shoes, fashion items, telecom operators. Here, we present our system, its flexibility and performance. We also show benchmark results on open datasets, that significantly outperform state-of-the-art prior work.
A Strong Baseline for Fashion Retrieval with Person Re-Identification Models
Mar 09, 2020


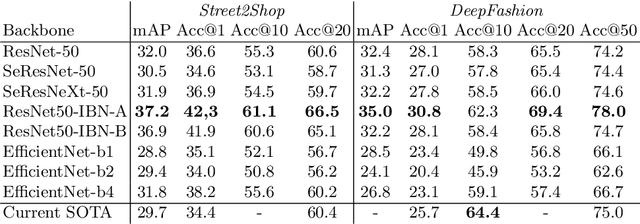
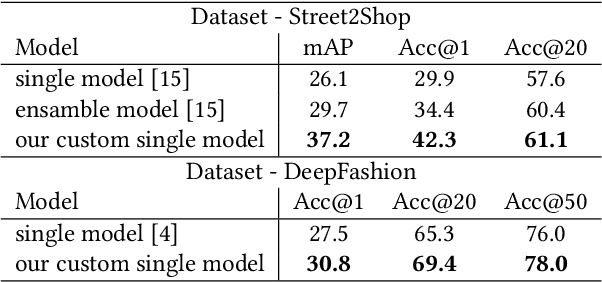
Fashion retrieval is the challenging task of finding an exact match for fashion items contained within an image. Difficulties arise from the fine-grained nature of clothing items, very large intra-class and inter-class variance. Additionally, query and source images for the task usually come from different domains - street photos and catalogue photos respectively. Due to these differences, a significant gap in quality, lighting, contrast, background clutter and item presentation exists between domains. As a result, fashion retrieval is an active field of research both in academia and the industry. Inspired by recent advancements in Person Re-Identification research, we adapt leading ReID models to be used in fashion retrieval tasks. We introduce a simple baseline model for fashion retrieval, significantly outperforming previous state-of-the-art results despite a much simpler architecture. We conduct in-depth experiments on Street2Shop and DeepFashion datasets and validate our results. Finally, we propose a cross-domain (cross-dataset) evaluation method to test the robustness of fashion retrieval models.