 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-EMDE: Sketching-based global similarity for cross-modal retrieval
Paper and Code
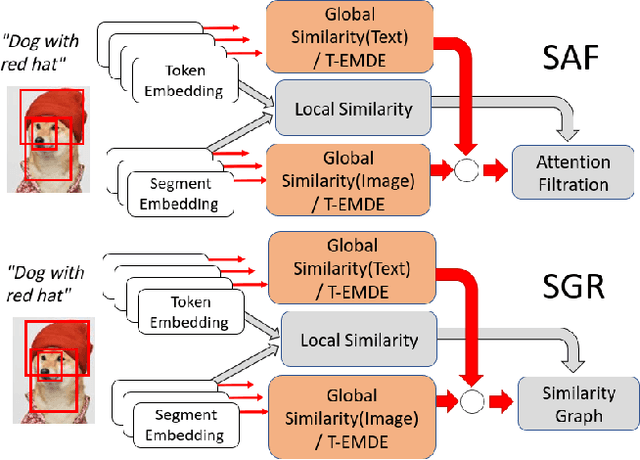
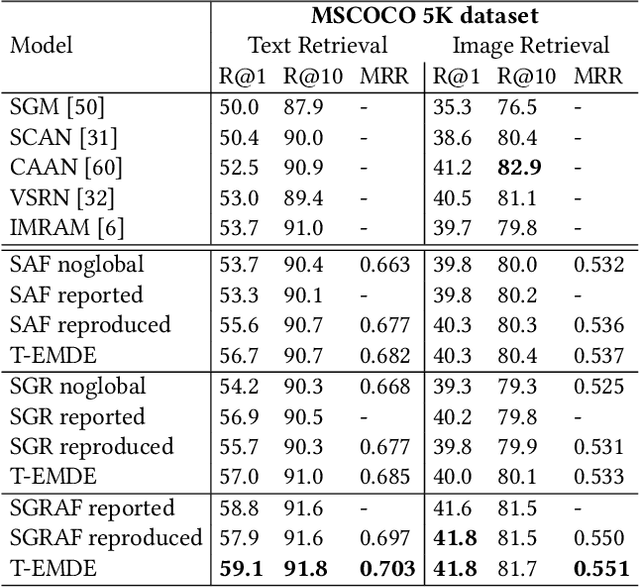
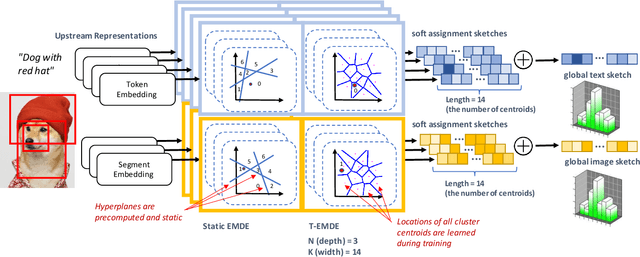
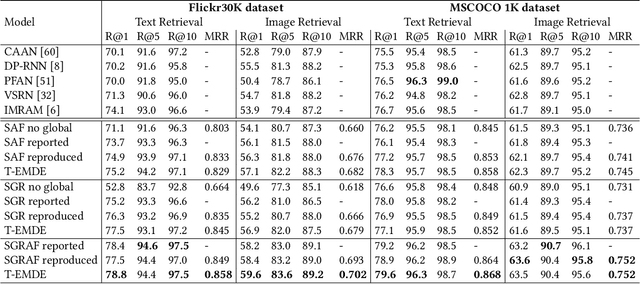
The key challenge in cross-modal retrieval is to find similarities between objects represented with different modalities, such as image and text. However, each modality embeddings stem from non-related feature spaces, which causes the notorious 'heterogeneity gap'. Currently, many cross-modal systems try to bridge the gap with self-attention. However, self-attention has been widely criticized for its quadratic complexity, which prevents many real-life applications. In response to this, we propose T-EMDE - a neural density estimator inspired by the recently introduced Efficient Manifold Density Estimator (EMDE) from the area of recommender systems. EMDE operates on sketches - representations especially suitable for multimodal operations. However, EMDE is non-differentiable and ingests precomputed, static embeddings. With T-EMDE we introduce a trainable version of EMDE which allows full end-to-end training. In contrast to self-attention, the complexity of our solution is linear to the number of tokens/segments. As such, T-EMDE is a drop-in replacement for the self-attention module, with beneficial influence on both speed and metric performance in cross-modal settings. It facilitates communication between modalities, as each global text/image representation is expressed with a standardized sketch histogram which represents the same manifold structures irrespective of the underlying modality. We evaluate T-EMDE by introducing it into two recent cross-modal SOTA models and achieving new state-of-the-art results on multiple datasets and decreasing model latency by up to 20%.