 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRewrite the News: Tracing Editorial Reuse Across News Agencies
Mar 31, 2026This paper investigates sentence-level text reuse in multilingual journalism, analyzing where reused content occurs within articles. We present a weakly supervised method for detecting sentence-level cross-lingual reuse without requiring full translations, designed to support automated pre-selection to reduce information overload for journalists (Holyst et al., 2024). The study compares English-language articles from the Slovenian Press Agency (STA) with reports from 15 foreign agencies (FA) in seven languages, using publication timestamps to retain the earliest likely foreign source for each reused sentence. We analyze 1,037 STA and 237,551 FA articles from two time windows (October 7-November 2, 2023; February 1-28, 2025) and identify 1,087 aligned sentence pairs after filtering to the earliest sources. Reuse occurs in 52% of STA articles and 1.6% of FA articles and is predominantly non-literal, involving paraphrase and compositional reuse from multiple sources. Reused content tends to appear in the middle and end of English articles, while leads are more often original, indicating that simple lexical matching overlooks substantial editorial reuse. Compared with prior work focused on monolingual overlap, we (i) detect reuse across languages without requiring full translation, (ii) use publication timing to identify likely sources, and (iii) analyze where reused material is situated within articles. Dataset and code: https://github.com/kunturs/lrec2026-rewrite-news.
Deepfake tweets automatic detection
Jun 24, 2024


This study addresses the critical challenge of detecting DeepFake tweets by leveraging advanced natural language processing (NLP) techniques to distinguish between genuine and AI-generated texts. Given the increasing prevalence of misinformation, our research utilizes the TweepFake dataset to train and evaluate various machine learning models. The objective is to identify effective strategies for recognizing DeepFake content, thereby enhancing the integrity of digital communications. By developing reliable methods for detecting AI-generated misinformation, this work contributes to a more trustworthy online information environment.
A Deep Learning Approach for Automatic Detection of Qualitative Features of Lecturing
May 30, 2022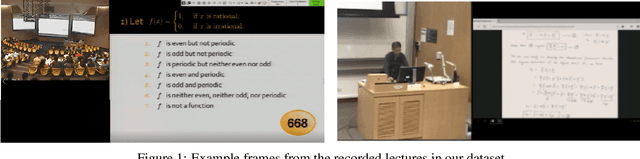
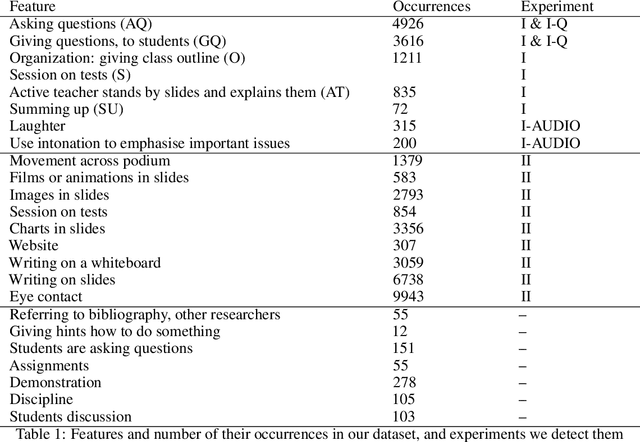
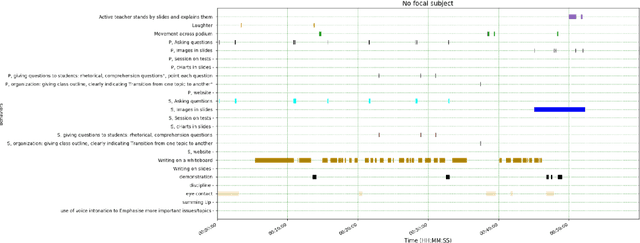
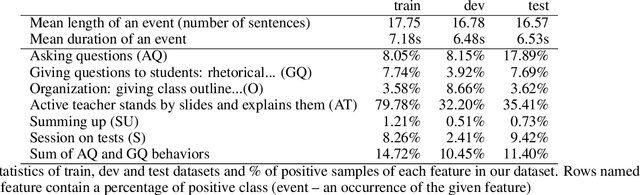
Artificial Intelligence in higher education opens new possibilities for improving the lecturing process, such as enriching didactic materials, helping in assessing students' works or even providing directions to the teachers on how to enhance the lectures. We follow this research path, and in this work, we explore how an academic lecture can be assessed automatically by quantitative features. First, we prepare a set of qualitative features based on teaching practices and then annotate the dataset of academic lecture videos collected for this purpose. We then show how these features could be detected automatically using machine learning and computer vision techniques. Our results show the potential usefulness of our work.
ProtagonistTagger -- a Tool for Entity Linkage of Persons in Texts from Various Languages and Domains
Mar 13, 2022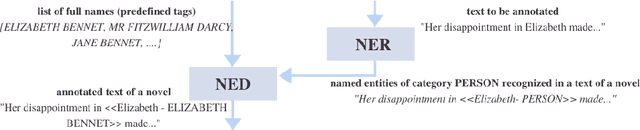


Named entities recognition (NER) and disambiguation (NED) can add semantic context to the recognized named entities in texts. Named entity linkage in texts, regardless of a domain, provides links between the entities mentioned in unstructured texts and individual instances of real-world objects. In this poster, we present a tool - protagonistTagger - for person NER and NED in texts. The tool was tested on texts extracted from classic English novels and Polish Internet news. The tool's performance (both precision and recall) fluctuates between 78% and even 88%.
Applying SoftTriple Loss for Supervised Language Model Fine Tuning
Dec 15, 2021
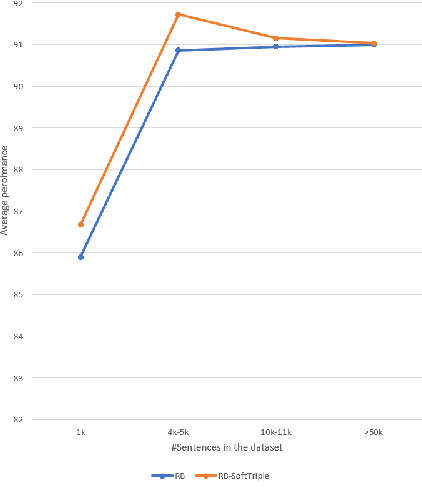

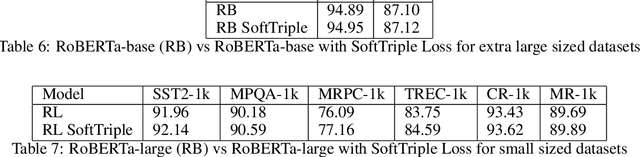
We introduce a new loss function TripleEntropy, to improve classification performance for fine-tuning general knowledge pre-trained language models based on cross-entropy and SoftTriple loss. This loss function can improve the robust RoBERTa baseline model fine-tuned with cross-entropy loss by about (0.02% - 2.29%). Thorough tests on popular datasets indicate a steady gain. The fewer samples in the training dataset, the higher gain -- thus, for small-sized dataset it is 0.78%, for medium-sized -- 0.86% for large -- 0.20% and for extra-large 0.04%.
Multi-modal Embedding Fusion-based Recommender
May 14, 2020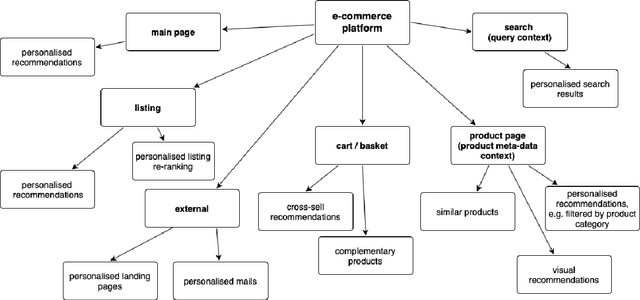
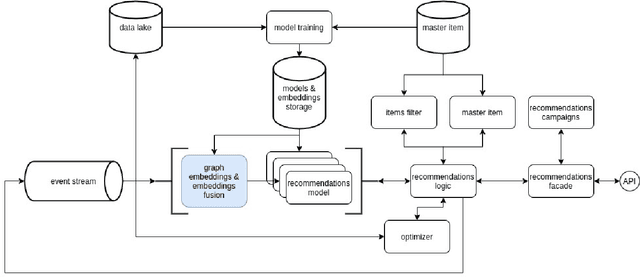
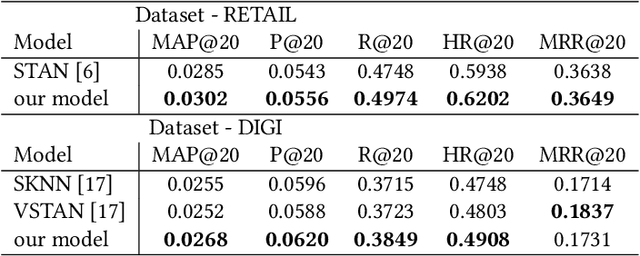
Recommendation systems have lately been popularized globally, with primary use cases in online interaction systems, with significant focus on e-commerce platforms. We have developed a machine learning-based recommendation platform, which can be easily applied to almost any items and/or actions domain. Contrary to existing recommendation systems, our platform supports multiple types of interaction data with multiple modalities of metadata natively. This is achieved through multi-modal fusion of various data representations. We deployed the platform into multiple e-commerce stores of different kinds, e.g. food and beverages, shoes, fashion items, telecom operators. Here, we present our system, its flexibility and performance. We also show benchmark results on open datasets, that significantly outperform state-of-the-art prior work.
A Strong Baseline for Fashion Retrieval with Person Re-Identification Models
Mar 09, 2020


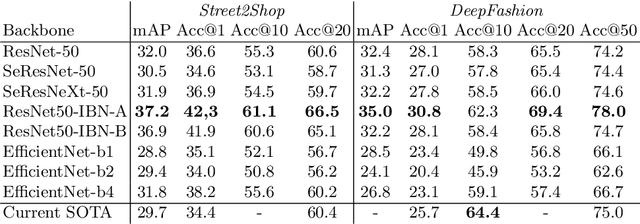
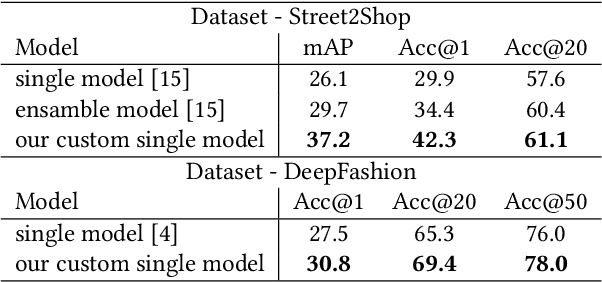
Fashion retrieval is the challenging task of finding an exact match for fashion items contained within an image. Difficulties arise from the fine-grained nature of clothing items, very large intra-class and inter-class variance. Additionally, query and source images for the task usually come from different domains - street photos and catalogue photos respectively. Due to these differences, a significant gap in quality, lighting, contrast, background clutter and item presentation exists between domains. As a result, fashion retrieval is an active field of research both in academia and the industry. Inspired by recent advancements in Person Re-Identification research, we adapt leading ReID models to be used in fashion retrieval tasks. We introduce a simple baseline model for fashion retrieval, significantly outperforming previous state-of-the-art results despite a much simpler architecture. We conduct in-depth experiments on Street2Shop and DeepFashion datasets and validate our results. Finally, we propose a cross-domain (cross-dataset) evaluation method to test the robustness of fashion retrieval models.
Does it care what you asked? Understanding Importance of Verbs in Deep Learning QA System
Sep 11, 2018
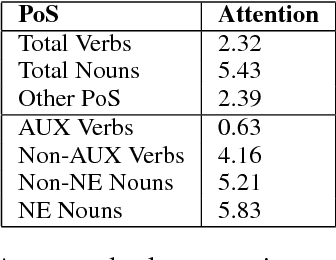
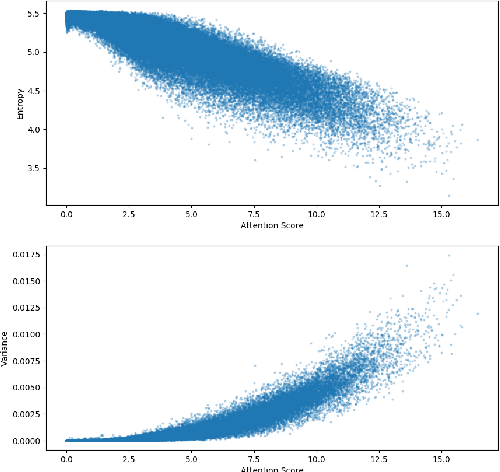
In this paper we present the results of an investigation of the importance of verbs in a deep learning QA system trained on SQuAD dataset. We show that main verbs in questions carry little influence on the decisions made by the system - in over 90% of researched cases swapping verbs for their antonyms did not change system decision. We track this phenomenon down to the insides of the net, analyzing the mechanism of self-attention and values contained in hidden layers of RNN. Finally, we recognize the characteristics of the SQuAD dataset as the source of the problem. Our work refers to the recently popular topic of adversarial examples in NLP, combined with investigating deep net structure.
How much should you ask? On the question structure in QA systems
Sep 11, 2018



Datasets that boosted state-of-the-art solutions for Question Answering (QA) systems prove that it is possible to ask questions in natural language manner. However, users are still used to query-like systems where they type in keywords to search for answer. In this study we validate which parts of questions are essential for obtaining valid answer. In order to conclude that, we take advantage of LIME - a framework that explains prediction by local approximation. We find that grammar and natural language is disregarded by QA. State-of-the-art model can answer properly even if 'asked' only with a few words with high coefficients calculated with LIME. According to our knowledge, it is the first time that QA model is being explained by LIME.