Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying SoftTriple Loss for Supervised Language Model Fine Tuning
Paper and Code
Dec 15, 2021
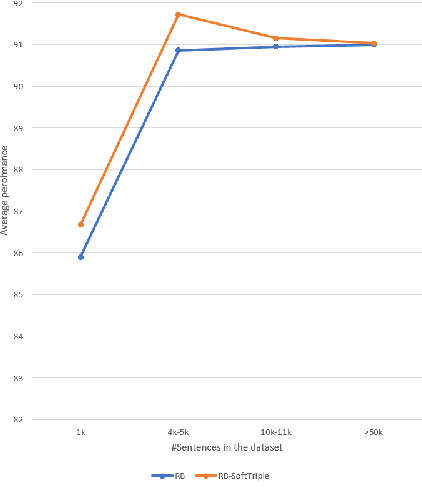

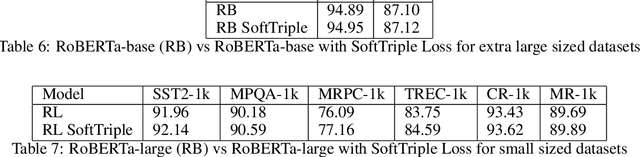
We introduce a new loss function TripleEntropy, to improve classification performance for fine-tuning general knowledge pre-trained language models based on cross-entropy and SoftTriple loss. This loss function can improve the robust RoBERTa baseline model fine-tuned with cross-entropy loss by about (0.02% - 2.29%). Thorough tests on popular datasets indicate a steady gain. The fewer samples in the training dataset, the higher gain -- thus, for small-sized dataset it is 0.78%, for medium-sized -- 0.86% for large -- 0.20% and for extra-large 0.04%.
View paper on