 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Distance Metric Learning for Few-Shot Natural Language Classification
Nov 28, 2022Distance Metric Learning (DML) has attracted much attention in image processing in recent years. This paper analyzes its impact on supervised fine-tuning language models for Natural Language Processing (NLP) classification tasks under few-shot learning settings. We investigated several DML loss functions in training RoBERTa language models on known SentEval Transfer Tasks datasets. We also analyzed the possibility of using proxy-based DML losses during model inference. Our systematic experiments have shown that under few-shot learning settings, particularly proxy-based DML losses can positively affect the fine-tuning and inference of a supervised language model. Models tuned with a combination of CCE (categorical cross-entropy loss) and ProxyAnchor Loss have, on average, the best performance and outperform models with only CCE by about 3.27 percentage points -- up to 10.38 percentage points depending on the training dataset.
Distance Metric Learning Loss Functions in Few-Shot Scenarios of Supervised Language Models Fine-Tuning
Nov 28, 2022This paper presents an analysis regarding an influence of the Distance Metric Learning (DML) loss functions on the supervised fine-tuning of the language models for classification tasks. We experimented with known datasets from SentEval Transfer Tasks. Our experiments show that applying the DML loss function can increase performance on downstream classification tasks of RoBERTa-large models in few-shot scenarios. Models fine-tuned with the use of SoftTriple loss can achieve better results than models with a standard categorical cross-entropy loss function by about 2.89 percentage points from 0.04 to 13.48 percentage points depending on the training dataset. Additionally, we accomplished a comprehensive analysis with explainability techniques to assess the models' reliability and explain their results.
Applying SoftTriple Loss for Supervised Language Model Fine Tuning
Dec 15, 2021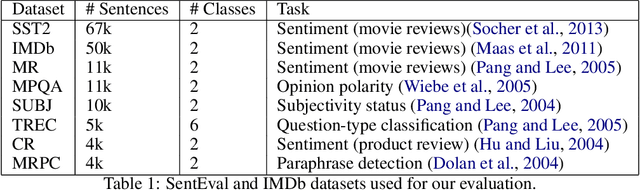
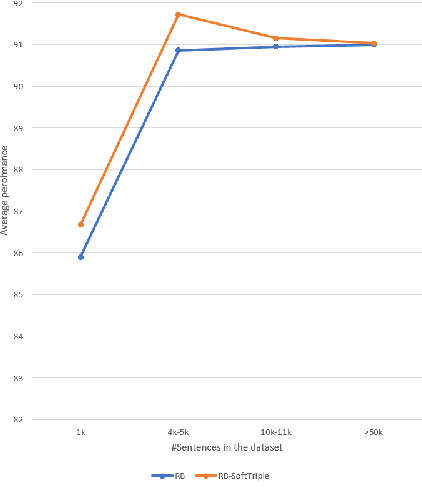

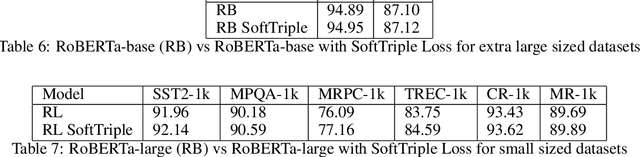
We introduce a new loss function TripleEntropy, to improve classification performance for fine-tuning general knowledge pre-trained language models based on cross-entropy and SoftTriple loss. This loss function can improve the robust RoBERTa baseline model fine-tuned with cross-entropy loss by about (0.02% - 2.29%). Thorough tests on popular datasets indicate a steady gain. The fewer samples in the training dataset, the higher gain -- thus, for small-sized dataset it is 0.78%, for medium-sized -- 0.86% for large -- 0.20% and for extra-large 0.04%.
Deep Reinforcement Learning for Resource Allocation in Business Processes
Mar 29, 2021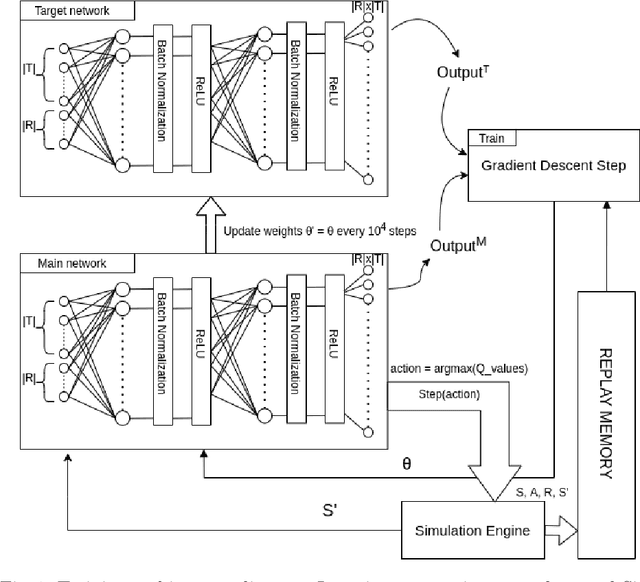
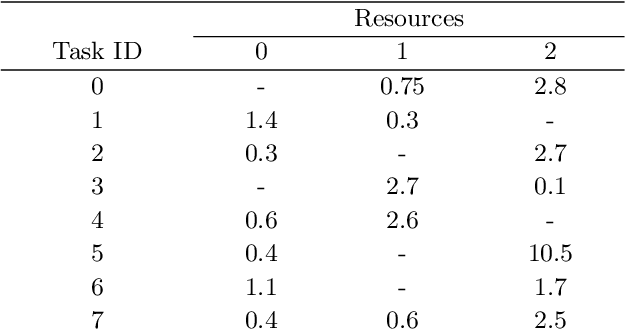
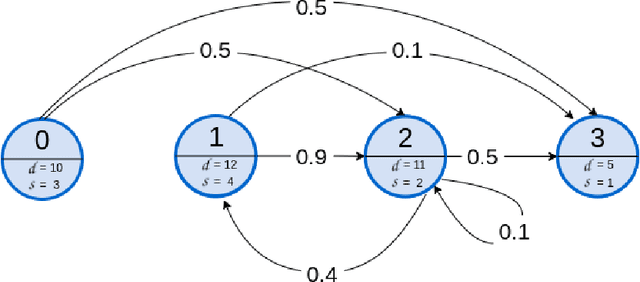
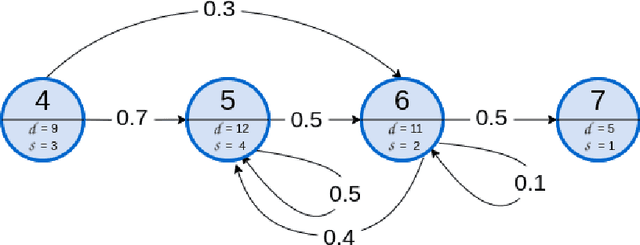
Assigning resources in business processes execution is a repetitive task that can be effectively automated. However, different automation methods may give varying results that may not be optimal. Proper resource allocation is crucial as it may lead to significant cost reductions or increased effectiveness that results in increased revenues. In this work, we first propose a novel representation that allows modeling of a multi-process environment with different process-based rewards. These processes can share resources that differ in their eligibility. Then, we use double deep reinforcement learning to look for optimal resource allocation policy. We compare those results with two popular strategies that are widely used in the industry. Learning optimal policy through reinforcement learning requires frequent interactions with the environment, so we also designed and developed a simulation engine that can mimic real-world processes. The results obtained are promising. Deep reinforcement learning based resource allocation achieved significantly better results compared to two commonly used techniques.