 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMALicious INTent Dataset and Inoculating LLMs for Enhanced Disinformation Detection
Mar 15, 2026The intentional creation and spread of disinformation poses a significant threat to public discourse. However, existing English datasets and research rarely address the intentionality behind the disinformation. This work presents MALINT, the first human-annotated English corpus developed in collaboration with expert fact-checkers to capture disinformation and its malicious intent. We utilize our novel corpus to benchmark 12 language models, including small language models (SLMs) such as BERT and large language models (LLMs) like Llama 3.3, on binary and multilabel intent classification tasks. Moreover, inspired by inoculation theory from psychology and communication studies, we investigate whether incorporating knowledge of malicious intent can improve disinformation detection. To this end, we propose intent-based inoculation, an intent-augmented reasoning for LLMs that integrates intent analysis to mitigate the persuasive impact of disinformation. Analysis on six disinformation datasets, five LLMs, and seven languages shows that intent-augmented reasoning improves zero-shot disinformation detection. To support research in intent-aware disinformation detection, we release the MALINT dataset with annotations from each annotation step.
PCoT: Persuasion-Augmented Chain of Thought for Detecting Fake News and Social Media Disinformation
Jun 07, 2025Disinformation detection is a key aspect of media literacy. Psychological studies have shown that knowledge of persuasive fallacies helps individuals detect disinformation. Inspired by these findings, we experimented with large language models (LLMs) to test whether infusing persuasion knowledge enhances disinformation detection. As a result, we introduce the Persuasion-Augmented Chain of Thought (PCoT), a novel approach that leverages persuasion to improve disinformation detection in zero-shot classification. We extensively evaluate PCoT on online news and social media posts. Moreover, we publish two novel, up-to-date disinformation datasets: EUDisinfo and MultiDis. These datasets enable the evaluation of PCoT on content entirely unseen by the LLMs used in our experiments, as the content was published after the models' knowledge cutoffs. We show that, on average, PCoT outperforms competitive methods by 15% across five LLMs and five datasets. These findings highlight the value of persuasion in strengthening zero-shot disinformation detection.
Distance Metric Learning Loss Functions in Few-Shot Scenarios of Supervised Language Models Fine-Tuning
Nov 28, 2022This paper presents an analysis regarding an influence of the Distance Metric Learning (DML) loss functions on the supervised fine-tuning of the language models for classification tasks. We experimented with known datasets from SentEval Transfer Tasks. Our experiments show that applying the DML loss function can increase performance on downstream classification tasks of RoBERTa-large models in few-shot scenarios. Models fine-tuned with the use of SoftTriple loss can achieve better results than models with a standard categorical cross-entropy loss function by about 2.89 percentage points from 0.04 to 13.48 percentage points depending on the training dataset. Additionally, we accomplished a comprehensive analysis with explainability techniques to assess the models' reliability and explain their results.
Revisiting Distance Metric Learning for Few-Shot Natural Language Classification
Nov 28, 2022Distance Metric Learning (DML) has attracted much attention in image processing in recent years. This paper analyzes its impact on supervised fine-tuning language models for Natural Language Processing (NLP) classification tasks under few-shot learning settings. We investigated several DML loss functions in training RoBERTa language models on known SentEval Transfer Tasks datasets. We also analyzed the possibility of using proxy-based DML losses during model inference. Our systematic experiments have shown that under few-shot learning settings, particularly proxy-based DML losses can positively affect the fine-tuning and inference of a supervised language model. Models tuned with a combination of CCE (categorical cross-entropy loss) and ProxyAnchor Loss have, on average, the best performance and outperform models with only CCE by about 3.27 percentage points -- up to 10.38 percentage points depending on the training dataset.
TASTEset -- Recipe Dataset and Food Entities Recognition Benchmark
Apr 16, 2022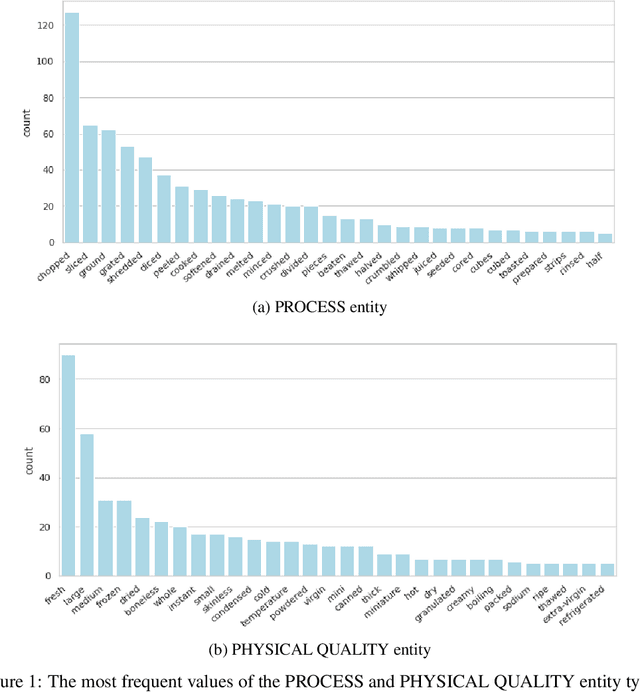
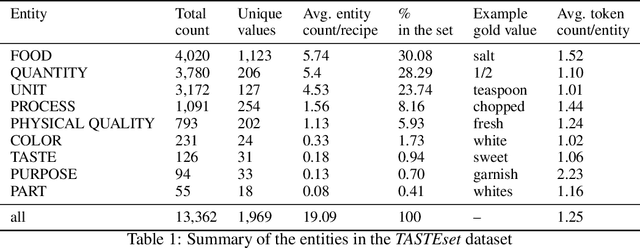
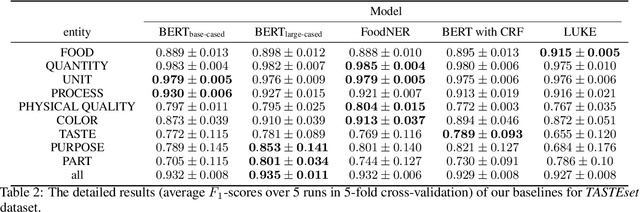
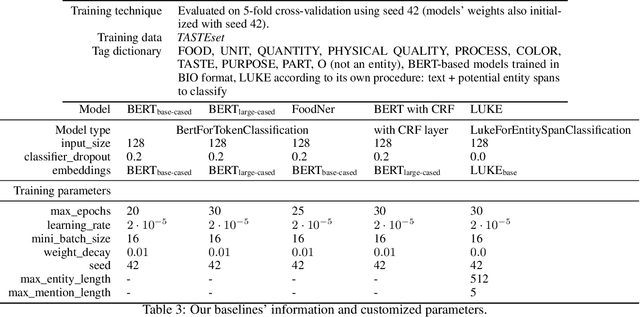
Food Computing is currently a fast-growing field of research. Natural language processing (NLP) is also increasingly essential in this field, especially for recognising food entities. However, there are still only a few well-defined tasks that serve as benchmarks for solutions in this area. We introduce a new dataset -- called \textit{TASTEset} -- to bridge this gap. In this dataset, Named Entity Recognition (NER) models are expected to find or infer various types of entities helpful in processing recipes, e.g.~food products, quantities and their units, names of cooking processes, physical quality of ingredients, their purpose, taste. The dataset consists of 700 recipes with more than 13,000 entities to extract. We provide a few state-of-the-art baselines of named entity recognition models, which show that our dataset poses a solid challenge to existing models. The best model achieved, on average, 0.95 $F_1$ score, depending on the entity type -- from 0.781 to 0.982. We share the dataset and the task to encourage progress on more in-depth and complex information extraction from recipes.
Applying SoftTriple Loss for Supervised Language Model Fine Tuning
Dec 15, 2021
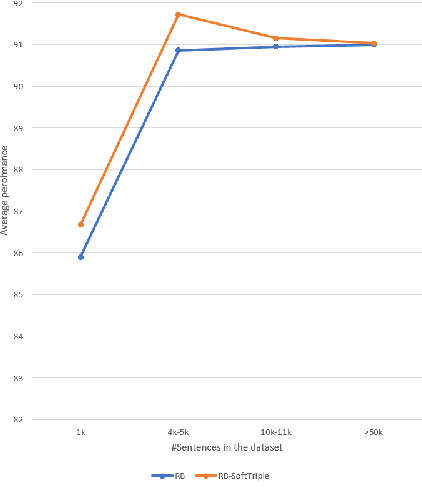

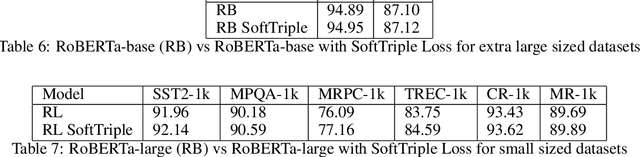
We introduce a new loss function TripleEntropy, to improve classification performance for fine-tuning general knowledge pre-trained language models based on cross-entropy and SoftTriple loss. This loss function can improve the robust RoBERTa baseline model fine-tuned with cross-entropy loss by about (0.02% - 2.29%). Thorough tests on popular datasets indicate a steady gain. The fewer samples in the training dataset, the higher gain -- thus, for small-sized dataset it is 0.78%, for medium-sized -- 0.86% for large -- 0.20% and for extra-large 0.04%.