 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Winning Arguments with Large Language Models and Persuasion Strategies
Jan 15, 2026Detecting persuasion in argumentative text is a challenging task with important implications for understanding human communication. This work investigates the role of persuasion strategies - such as Attack on reputation, Distraction, and Manipulative wording - in determining the persuasiveness of a text. We conduct experiments on three annotated argument datasets: Winning Arguments (built from the Change My View subreddit), Anthropic/Persuasion, and Persuasion for Good. Our approach leverages large language models (LLMs) with a Multi-Strategy Persuasion Scoring approach that guides reasoning over six persuasion strategies. Results show that strategy-guided reasoning improves the prediction of persuasiveness. To better understand the influence of content, we organize the Winning Argument dataset into broad discussion topics and analyze performance across them. We publicly release this topic-annotated version of the dataset to facilitate future research. Overall, our methodology demonstrates the value of structured, strategy-aware prompting for enhancing interpretability and robustness in argument quality assessment.
PCoT: Persuasion-Augmented Chain of Thought for Detecting Fake News and Social Media Disinformation
Jun 07, 2025Disinformation detection is a key aspect of media literacy. Psychological studies have shown that knowledge of persuasive fallacies helps individuals detect disinformation. Inspired by these findings, we experimented with large language models (LLMs) to test whether infusing persuasion knowledge enhances disinformation detection. As a result, we introduce the Persuasion-Augmented Chain of Thought (PCoT), a novel approach that leverages persuasion to improve disinformation detection in zero-shot classification. We extensively evaluate PCoT on online news and social media posts. Moreover, we publish two novel, up-to-date disinformation datasets: EUDisinfo and MultiDis. These datasets enable the evaluation of PCoT on content entirely unseen by the LLMs used in our experiments, as the content was published after the models' knowledge cutoffs. We show that, on average, PCoT outperforms competitive methods by 15% across five LLMs and five datasets. These findings highlight the value of persuasion in strengthening zero-shot disinformation detection.
Evaluating Task-Oriented Dialogue Consistency through Constraint Satisfaction
Jul 16, 2024



Task-oriented dialogues must maintain consistency both within the dialogue itself, ensuring logical coherence across turns, and with the conversational domain, accurately reflecting external knowledge. We propose to conceptualize dialogue consistency as a Constraint Satisfaction Problem (CSP), wherein variables represent segments of the dialogue referencing the conversational domain, and constraints among variables reflect dialogue properties, including linguistic, conversational, and domain-based aspects. To demonstrate the feasibility of the approach, we utilize a CSP solver to detect inconsistencies in dialogues re-lexicalized by an LLM. Our findings indicate that: (i) CSP is effective to detect dialogue inconsistencies; and (ii) consistent dialogue re-lexicalization is challenging for state-of-the-art LLMs, achieving only a 0.15 accuracy rate when compared to a CSP solver. Furthermore, through an ablation study, we reveal that constraints derived from domain knowledge pose the greatest difficulty in being respected. We argue that CSP captures core properties of dialogue consistency that have been poorly considered by approaches based on component pipelines.
When to Retrieve: Teaching LLMs to Utilize Information Retrieval Effectively
Apr 30, 2024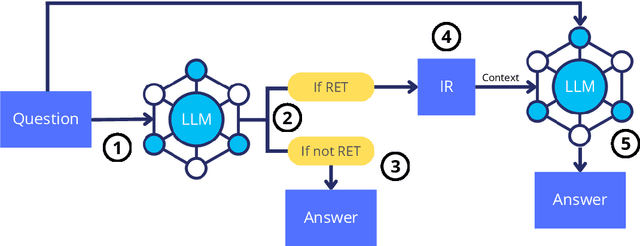

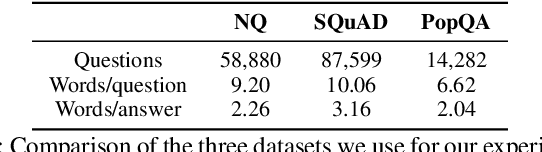
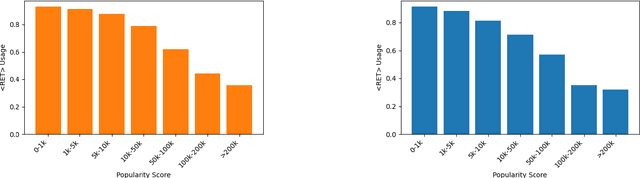
In this paper, we demonstrate how Large Language Models (LLMs) can effectively learn to use an off-the-shelf information retrieval (IR) system specifically when additional context is required to answer a given question. Given the performance of IR systems, the optimal strategy for question answering does not always entail external information retrieval; rather, it often involves leveraging the parametric memory of the LLM itself. Prior research has identified this phenomenon in the PopQA dataset, wherein the most popular questions are effectively addressed using the LLM's parametric memory, while less popular ones require IR system usage. Following this, we propose a tailored training approach for LLMs, leveraging existing open-domain question answering datasets. Here, LLMs are trained to generate a special token, <RET>, when they do not know the answer to a question. Our evaluation of the Adaptive Retrieval LLM (Adapt-LLM) on the PopQA dataset showcases improvements over the same LLM under three configurations: (i) retrieving information for all the questions, (ii) using always the parametric memory of the LLM, and (iii) using a popularity threshold to decide when to use a retriever. Through our analysis, we demonstrate that Adapt-LLM is able to generate the <RET> token when it determines that it does not know how to answer a question, indicating the need for IR, while it achieves notably high accuracy levels when it chooses to rely only on its parametric memory.
Unraveling ChatGPT: A Critical Analysis of AI-Generated Goal-Oriented Dialogues and Annotations
May 23, 2023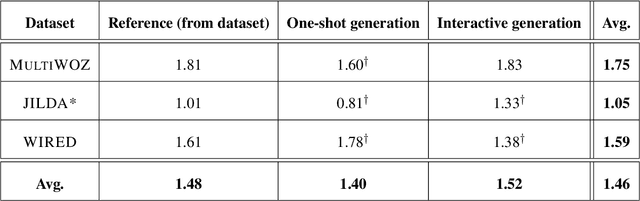

Large pre-trained language models have exhibited unprecedented capabilities in producing high-quality text via prompting techniques. This fact introduces new possibilities for data collection and annotation, particularly in situations where such data is scarce, complex to gather, expensive, or even sensitive. In this paper, we explore the potential of these models to generate and annotate goal-oriented dialogues, and conduct an in-depth analysis to evaluate their quality. Our experiments employ ChatGPT, and encompass three categories of goal-oriented dialogues (task-oriented, collaborative, and explanatory), two generation modes (interactive and one-shot), and two languages (English and Italian). Based on extensive human-based evaluations, we demonstrate that the quality of generated dialogues and annotations is on par with those generated by humans.