 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Apr 11, 2024Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
Unraveling ChatGPT: A Critical Analysis of AI-Generated Goal-Oriented Dialogues and Annotations
May 23, 2023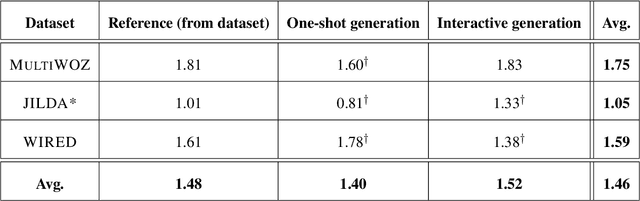

Large pre-trained language models have exhibited unprecedented capabilities in producing high-quality text via prompting techniques. This fact introduces new possibilities for data collection and annotation, particularly in situations where such data is scarce, complex to gather, expensive, or even sensitive. In this paper, we explore the potential of these models to generate and annotate goal-oriented dialogues, and conduct an in-depth analysis to evaluate their quality. Our experiments employ ChatGPT, and encompass three categories of goal-oriented dialogues (task-oriented, collaborative, and explanatory), two generation modes (interactive and one-shot), and two languages (English and Italian). Based on extensive human-based evaluations, we demonstrate that the quality of generated dialogues and annotations is on par with those generated by humans.
Tracing metaphors in time through self-distance in vector spaces
Nov 10, 2016
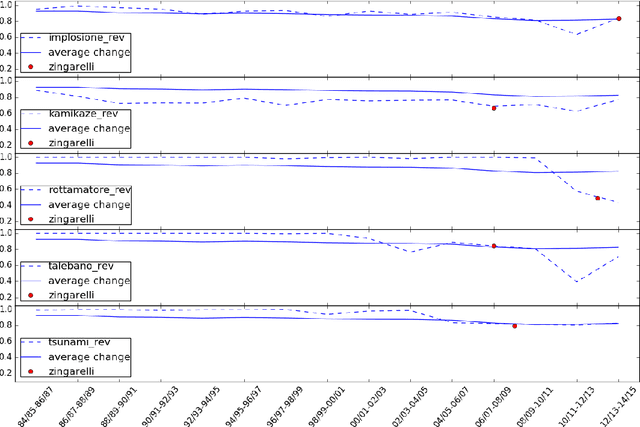
From a diachronic corpus of Italian, we build consecutive vector spaces in time and use them to compare a term's cosine similarity to itself in different time spans. We assume that a drop in similarity might be related to the emergence of a metaphorical sense at a given time. Similarity-based observations are matched to the actual year when a figurative meaning was documented in a reference dictionary and through manual inspection of corpus occurrences.