 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstructing Large Language Models for Low-Resource Languages: A Systematic Study for Basque
Jun 09, 2025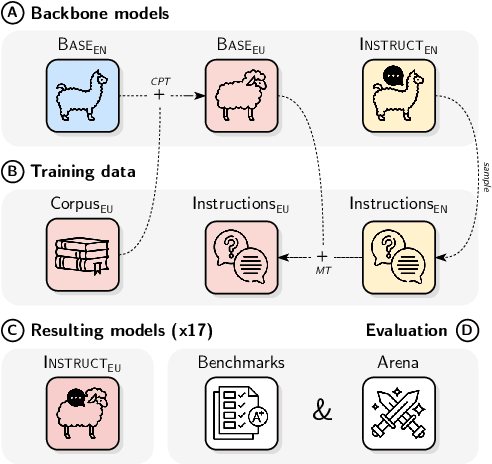
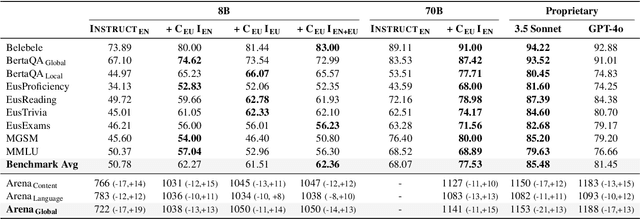
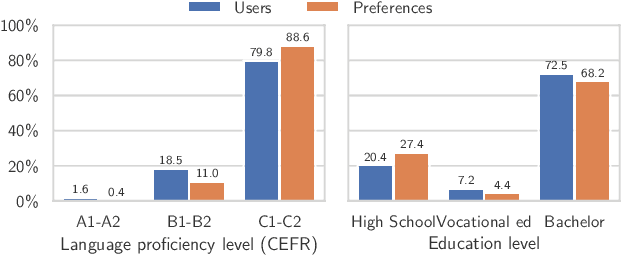

Instructing language models with user intent requires large instruction datasets, which are only available for a limited set of languages. In this paper, we explore alternatives to conventional instruction adaptation pipelines in low-resource scenarios. We assume a realistic scenario for low-resource languages, where only the following are available: corpora in the target language, existing open-weight multilingual base and instructed backbone LLMs, and synthetically generated instructions sampled from the instructed backbone. We present a comprehensive set of experiments for Basque that systematically study different combinations of these components evaluated on benchmarks and human preferences from 1,680 participants. Our conclusions show that target language corpora are essential, with synthetic instructions yielding robust models, and, most importantly, that using as backbone an instruction-tuned model outperforms using a base non-instructed model, and improved results when scaling up. Using Llama 3.1 instruct 70B as backbone our model comes near frontier models of much larger sizes for Basque, without using any Basque data apart from the 1.2B word corpora. We release code, models, instruction datasets, and human preferences to support full reproducibility in future research on low-resource language adaptation.
Medical mT5: An Open-Source Multilingual Text-to-Text LLM for The Medical Domain
Apr 11, 2024Research on language technology for the development of medical applications is currently a hot topic in Natural Language Understanding and Generation. Thus, a number of large language models (LLMs) have recently been adapted to the medical domain, so that they can be used as a tool for mediating in human-AI interaction. While these LLMs display competitive performance on automated medical texts benchmarks, they have been pre-trained and evaluated with a focus on a single language (English mostly). This is particularly true of text-to-text models, which typically require large amounts of domain-specific pre-training data, often not easily accessible for many languages. In this paper, we address these shortcomings by compiling, to the best of our knowledge, the largest multilingual corpus for the medical domain in four languages, namely English, French, Italian and Spanish. This new corpus has been used to train Medical mT5, the first open-source text-to-text multilingual model for the medical domain. Additionally, we present two new evaluation benchmarks for all four languages with the aim of facilitating multilingual research in this domain. A comprehensive evaluation shows that Medical mT5 outperforms both encoders and similarly sized text-to-text models for the Spanish, French, and Italian benchmarks, while being competitive with current state-of-the-art LLMs in English.
Latxa: An Open Language Model and Evaluation Suite for Basque
Mar 29, 2024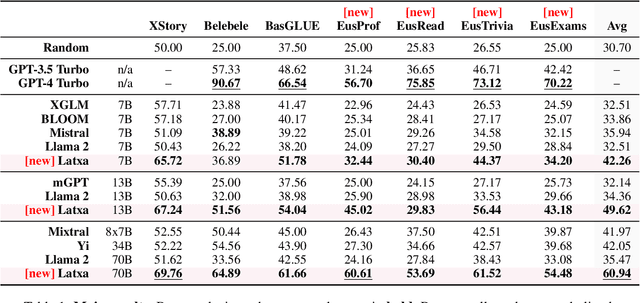
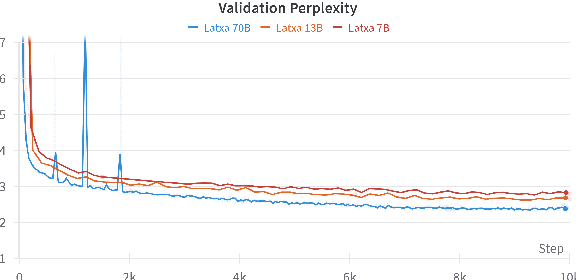
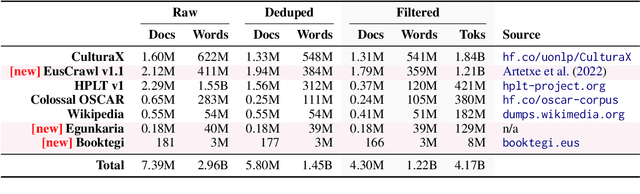
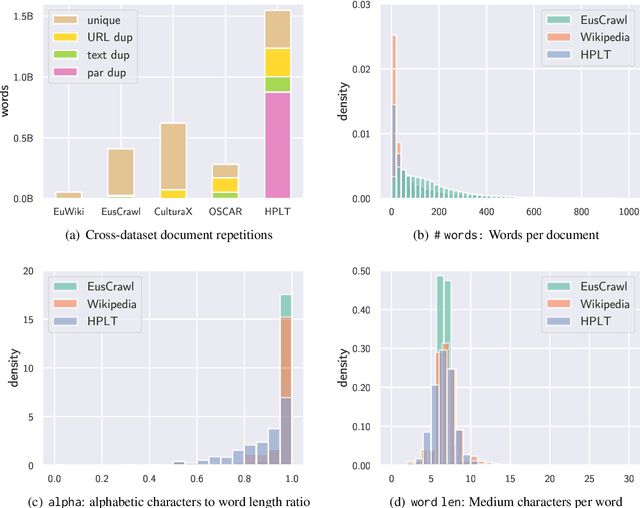
We introduce Latxa, a family of large language models for Basque ranging from 7 to 70 billion parameters. Latxa is based on Llama 2, which we continue pretraining on a new Basque corpus comprising 4.3M documents and 4.2B tokens. Addressing the scarcity of high-quality benchmarks for Basque, we further introduce 4 multiple choice evaluation datasets: EusProficiency, comprising 5,169 questions from official language proficiency exams; EusReading, comprising 352 reading comprehension questions; EusTrivia, comprising 1,715 trivia questions from 5 knowledge areas; and EusExams, comprising 16,774 questions from public examinations. In our extensive evaluation, Latxa outperforms all previous open models we compare to by a large margin. In addition, it is competitive with GPT-4 Turbo in language proficiency and understanding, despite lagging behind in reading comprehension and knowledge-intensive tasks. Both the Latxa family of models, as well as our new pretraining corpora and evaluation datasets, are publicly available under open licenses at https://github.com/hitz-zentroa/latxa. Our suite enables reproducible research on methods to build LLMs for low-resource languages.
This is not a Dataset: A Large Negation Benchmark to Challenge Large Language Models
Oct 24, 2023Although large language models (LLMs) have apparently acquired a certain level of grammatical knowledge and the ability to make generalizations, they fail to interpret negation, a crucial step in Natural Language Processing. We try to clarify the reasons for the sub-optimal performance of LLMs understanding negation. We introduce a large semi-automatically generated dataset of circa 400,000 descriptive sentences about commonsense knowledge that can be true or false in which negation is present in about 2/3 of the corpus in different forms. We have used our dataset with the largest available open LLMs in a zero-shot approach to grasp their generalization and inference capability and we have also fine-tuned some of the models to assess whether the understanding of negation can be trained. Our findings show that, while LLMs are proficient at classifying affirmative sentences, they struggle with negative sentences and lack a deep understanding of negation, often relying on superficial cues. Although fine-tuning the models on negative sentences improves their performance, the lack of generalization in handling negation is persistent, highlighting the ongoing challenges of LLMs regarding negation understanding and generalization. The dataset and code are publicly available.
GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction
Oct 06, 2023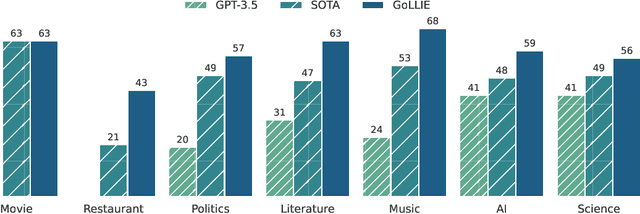
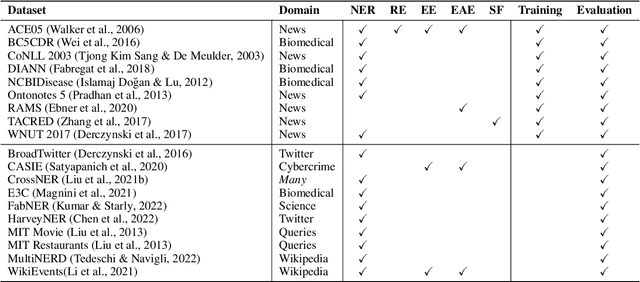

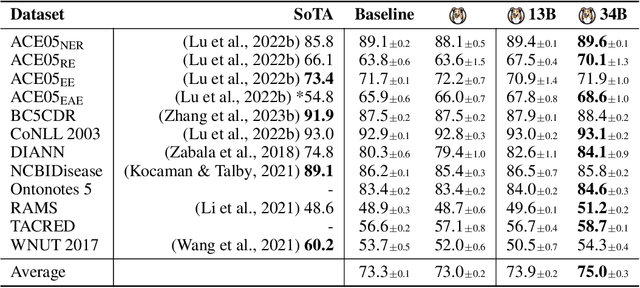
Large Language Models (LLMs) combined with instruction tuning have made significant progress when generalizing to unseen tasks. However, they have been less successful in Information Extraction (IE), lagging behind task-specific models. Typically, IE tasks are characterized by complex annotation guidelines which describe the task and give examples to humans. Previous attempts to leverage such information have failed, even with the largest models, as they are not able to follow the guidelines out-of-the-box. In this paper we propose GoLLIE (Guideline-following Large Language Model for IE), a model able to improve zero-shot results on unseen IE tasks by virtue of being fine-tuned to comply with annotation guidelines. Comprehensive evaluation empirically demonstrates that GoLLIE is able to generalize to and follow unseen guidelines, outperforming previous attempts at zero-shot information extraction. The ablation study shows that detailed guidelines is key for good results.
HiTZ@Antidote: Argumentation-driven Explainable Artificial Intelligence for Digital Medicine
Jun 09, 2023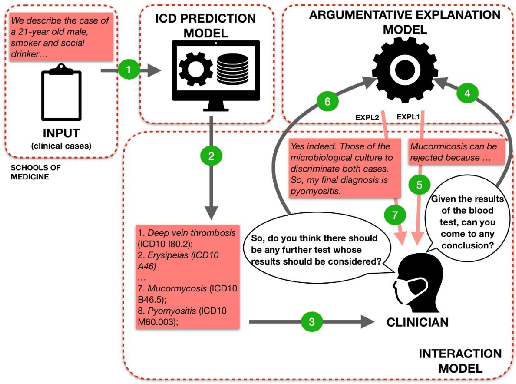
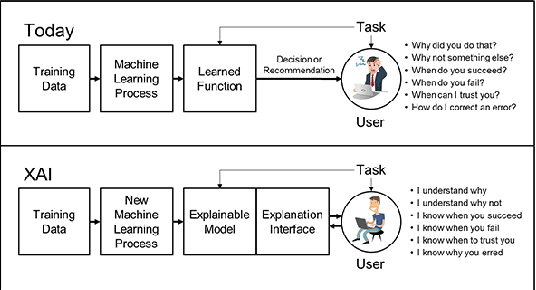
Providing high quality explanations for AI predictions based on machine learning is a challenging and complex task. To work well it requires, among other factors: selecting a proper level of generality/specificity of the explanation; considering assumptions about the familiarity of the explanation beneficiary with the AI task under consideration; referring to specific elements that have contributed to the decision; making use of additional knowledge (e.g. expert evidence) which might not be part of the prediction process; and providing evidence supporting negative hypothesis. Finally, the system needs to formulate the explanation in a clearly interpretable, and possibly convincing, way. Given these considerations, ANTIDOTE fosters an integrated vision of explainable AI, where low-level characteristics of the deep learning process are combined with higher level schemes proper of the human argumentation capacity. ANTIDOTE will exploit cross-disciplinary competences in deep learning and argumentation to support a broader and innovative view of explainable AI, where the need for high-quality explanations for clinical cases deliberation is critical. As a first result of the project, we publish the Antidote CasiMedicos dataset to facilitate research on explainable AI in general, and argumentation in the medical domain in particular.
A Modular Approach for Multilingual Timex Detection and Normalization using Deep Learning and Grammar-based methods
Apr 27, 2023

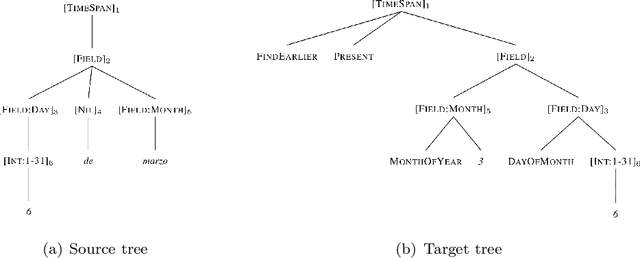

Detecting and normalizing temporal expressions is an essential step for many NLP tasks. While a variety of methods have been proposed for detection, best normalization approaches rely on hand-crafted rules. Furthermore, most of them have been designed only for English. In this paper we present a modular multilingual temporal processing system combining a fine-tuned Masked Language Model for detection, and a grammar-based normalizer. We experiment in Spanish and English and compare with HeidelTime, the state-of-the-art in multilingual temporal processing. We obtain best results in gold timex normalization, timex detection and type recognition, and competitive performance in the combined TempEval-3 relaxed value metric. A detailed error analysis shows that detecting only those timexes for which it is feasible to provide a normalization is highly beneficial in this last metric. This raises the question of which is the best strategy for timex processing, namely, leaving undetected those timexes for which is not easy to provide normalization rules or aiming for high coverage.
What do Language Models know about word senses? Zero-Shot WSD with Language Models and Domain Inventories
Feb 07, 2023



Language Models are the core for almost any Natural Language Processing system nowadays. One of their particularities is their contextualized representations, a game changer feature when a disambiguation between word senses is necessary. In this paper we aim to explore to what extent language models are capable of discerning among senses at inference time. We performed this analysis by prompting commonly used Languages Models such as BERT or RoBERTa to perform the task of Word Sense Disambiguation (WSD). We leverage the relation between word senses and domains, and cast WSD as a textual entailment problem, where the different hypothesis refer to the domains of the word senses. Our results show that this approach is indeed effective, close to supervised systems.
T-Projection: High Quality Annotation Projection for Sequence Labeling Tasks
Dec 20, 2022In the absence of readily available labeled data for a given task and language, annotation projection has been proposed as one of the possible strategies to automatically generate annotated data which may then be used to train supervised systems. Annotation projection has often been formulated as the task of projecting, on parallel corpora, some labels from a source into a target language. In this paper we present T-Projection, a new approach for annotation projection that leverages large pretrained text2text language models and state-of-the-art machine translation technology. T-Projection decomposes the label projection task into two subtasks: (i) The candidate generation step, in which a set of projection candidates using a multilingual T5 model is generated and, (ii) the candidate selection step, in which the candidates are ranked based on translation probabilities. We evaluate our method in three downstream tasks and five different languages. Our results show that T-projection improves the average F1 score of previous methods by more than 8 points.
Model and Data Transfer for Cross-Lingual Sequence Labelling in Zero-Resource Settings
Oct 23, 2022Zero-resource cross-lingual transfer approaches aim to apply supervised models from a source language to unlabelled target languages. In this paper we perform an in-depth study of the two main techniques employed so far for cross-lingual zero-resource sequence labelling, based either on data or model transfer. Although previous research has proposed translation and annotation projection (data-based cross-lingual transfer) as an effective technique for cross-lingual sequence labelling, in this paper we experimentally demonstrate that high capacity multilingual language models applied in a zero-shot (model-based cross-lingual transfer) setting consistently outperform data-based cross-lingual transfer approaches. A detailed analysis of our results suggests that this might be due to important differences in language use. More specifically, machine translation often generates a textual signal which is different to what the models are exposed to when using gold standard data, which affects both the fine-tuning and evaluation processes. Our results also indicate that data-based cross-lingual transfer approaches remain a competitive option when high-capacity multilingual language models are not available.