 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modular Approach for Multilingual Timex Detection and Normalization using Deep Learning and Grammar-based methods
Paper and Code


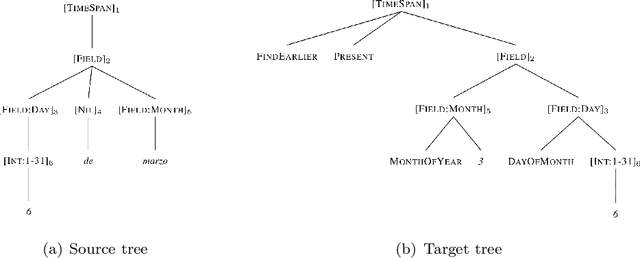

Detecting and normalizing temporal expressions is an essential step for many NLP tasks. While a variety of methods have been proposed for detection, best normalization approaches rely on hand-crafted rules. Furthermore, most of them have been designed only for English. In this paper we present a modular multilingual temporal processing system combining a fine-tuned Masked Language Model for detection, and a grammar-based normalizer. We experiment in Spanish and English and compare with HeidelTime, the state-of-the-art in multilingual temporal processing. We obtain best results in gold timex normalization, timex detection and type recognition, and competitive performance in the combined TempEval-3 relaxed value metric. A detailed error analysis shows that detecting only those timexes for which it is feasible to provide a normalization is highly beneficial in this last metric. This raises the question of which is the best strategy for timex processing, namely, leaving undetected those timexes for which is not easy to provide normalization rules or aiming for high coverage.