 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Central Repository: a Cross-lingual Framework for Developing Wordnets
Jul 02, 2021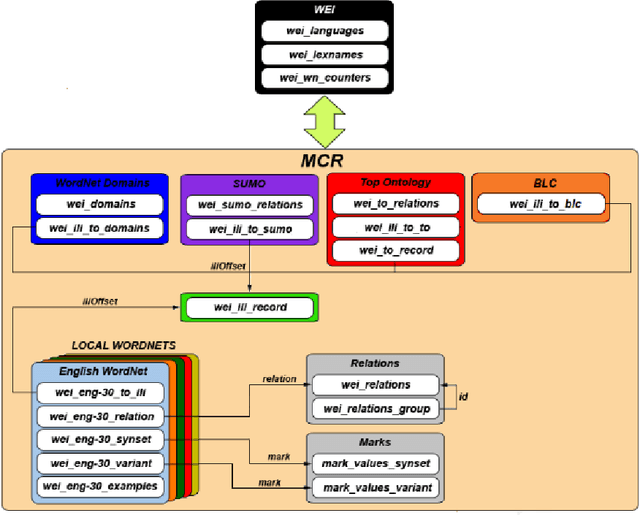
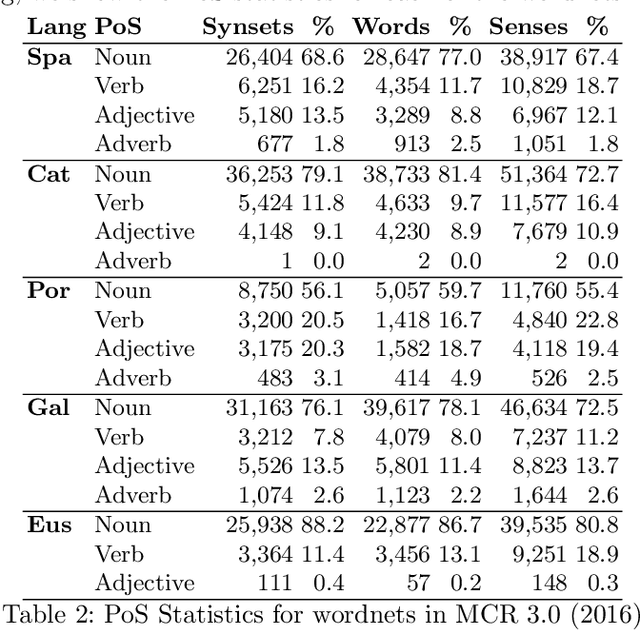
Language resources are necessary for language processing,but building them is costly, involves many researches from different areas and needs constant updating. In this paper, we describe the crosslingual framework used for developing the Multilingual Central Repository (MCR), a multilingual knowledge base that includes wordnets of Basque, Catalan, English, Galician, Portuguese, Spanish and the following ontologies: Base Concepts, Top Ontology, WordNet Domains and Suggested Upper Merged Ontology. We present the story of MCR, its state in 2017 and the developed tools.
Machine Translation of Novels in the Age of Transformer
Nov 30, 2020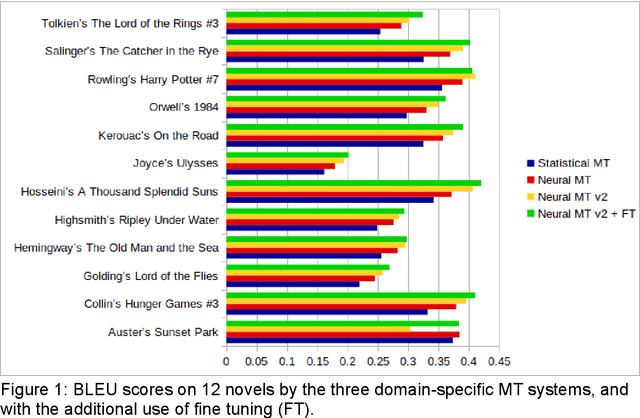
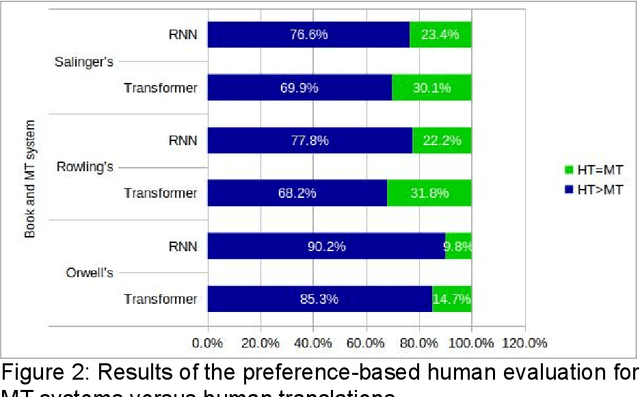
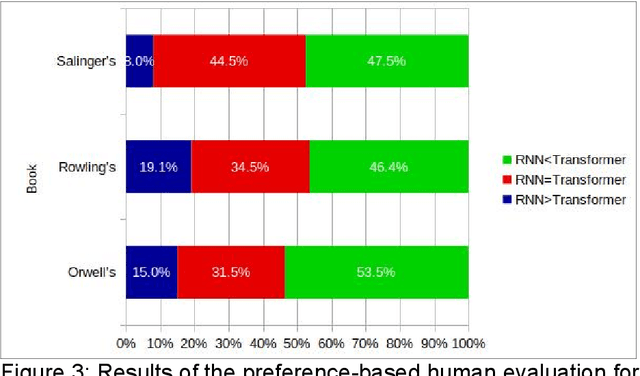
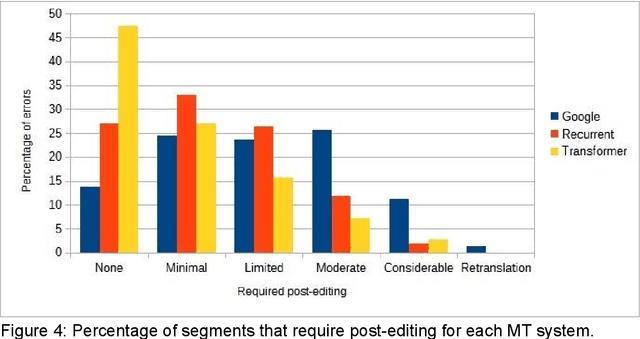
In this chapter we build a machine translation (MT) system tailored to the literary domain, specifically to novels, based on the state-of-the-art architecture in neural MT (NMT), the Transformer (Vaswani et al., 2017), for the translation direction English-to-Catalan. Subsequently, we assess to what extent such a system can be useful by evaluating its translations, by comparing this MT system against three other systems (two domain-specific systems under the recurrent and phrase-based paradigms and a popular generic on-line system) on three evaluations. The first evaluation is automatic and uses the most-widely used automatic evaluation metric, BLEU. The two remaining evaluations are manual and they assess, respectively, preference and amount of post-editing required to make the translation error-free. As expected, the domain-specific Transformer-based system outperformed the three other systems in all the three evaluations conducted, in all cases by a large margin.