Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Central Repository: a Cross-lingual Framework for Developing Wordnets
Paper and Code
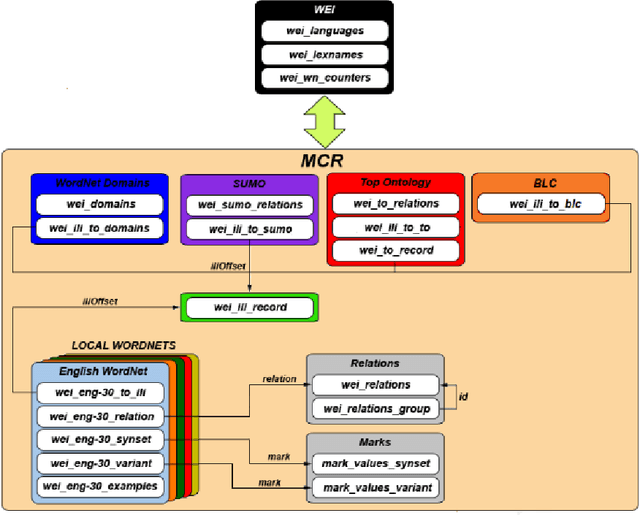
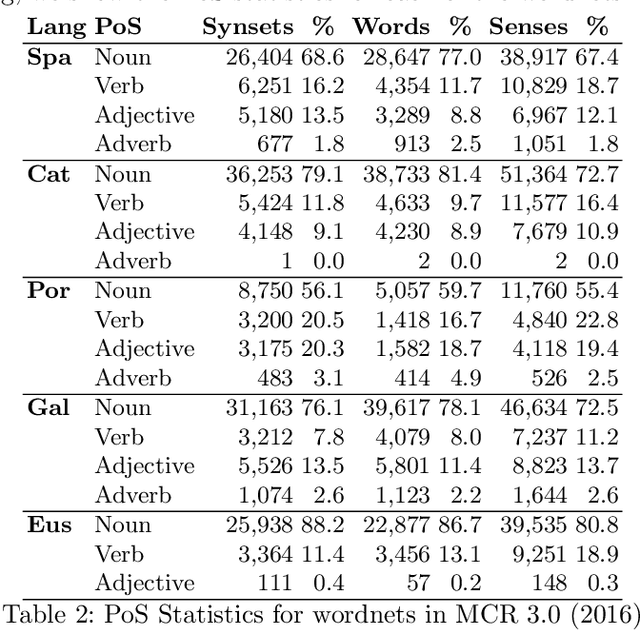
Language resources are necessary for language processing,but building them is costly, involves many researches from different areas and needs constant updating. In this paper, we describe the crosslingual framework used for developing the Multilingual Central Repository (MCR), a multilingual knowledge base that includes wordnets of Basque, Catalan, English, Galician, Portuguese, Spanish and the following ontologies: Base Concepts, Top Ontology, WordNet Domains and Suggested Upper Merged Ontology. We present the story of MCR, its state in 2017 and the developed tools.
* 11 pages, 1 figure. To appear in Special Issue on Linking,
Integrating and Extending Wordnets, Linguistic Issues in Language Technology
(LiLT) Volume 10, Issue 4, Sep 2017
View paper on